本文主要是介绍隐私计算实训营学习二:隐私计算开源如何助力数据要素流通,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、数据要素流转与数据内外循环
- 二、数据外循环中的信任焦虑
- 三、数据要素流通对隐私计算的期望
- 四、隐私计算开源助力数据要素流通
一、数据要素流转与数据内外循环
数据要素流转过程(从数据采集加工->到数据价值释放): 链路主要包括采集、存储、加工、使用、提供、传输。
内循环: 数据持有方在自己的运维管控域内对自己的数据使用和安全拥有全责。
外循环: 数据要素离开了持有方管控域,在使用方运维域,持有方依然拥有管控需求和责任,数据外循环是构建数据要素市场的核心,通过外循环数据提供方与使用方都可以获得收益。
- 数据提供方收益:新增长点、资产入表、数据资本化。
- 数据使用方收益:业务提效、运营降本、扩大营收。

二、数据外循环中的信任焦虑
构建数据要素市场关键:需要有足够的数据提供方加入->才会有足够多数据->数据才会呈现多样性->吸引更多数据使用方加入->数据价值变现。 这是一个理想的良性循环。
信任焦虑: 不可信内部人员、不按约定使用、用户隐私泄露。
信任焦虑的解决方案:从主体信任到技术信任: 信任本质上是对不确定性和复杂性的依赖,从主体信任到技术信任,基于安全可信的技术信任体系,是支撑全行业数据要素安全可控流转的基础。
数据要素流通的技术信任体系: 控制面以区块链/可信计算为核心支撑技术构建数据使用权跨域管控层;数据面以隐私计算为核心支撑技术构建密态数联网,包括密态枢纽与密态管道。
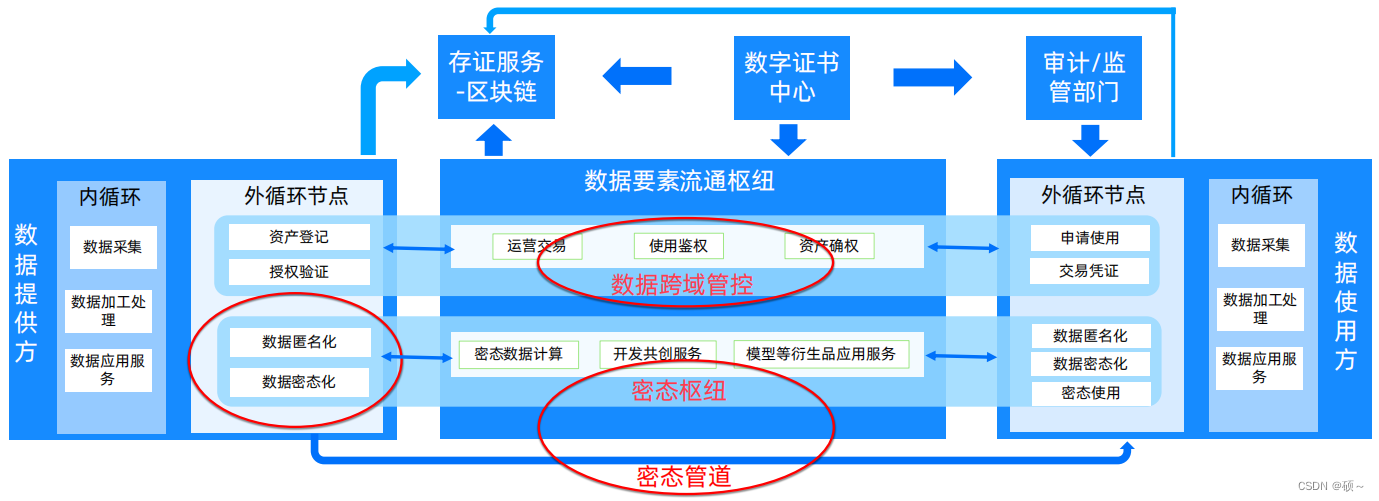
技术信任需要完备的信任链:
运维权限最小化: 只允许预期内的行为可以执行;
完备的信任链: 从信任根、硬件平台、操作系统到应用系统整个链路的可信认证;
远程验证: 能够远程验证云上运行环境,甚至执行环境安全隔离;
可信安全模块: 使用基于硬件的可信安全模块

三、数据要素流通对隐私计算的期望
1、隐私计算内涵在扩大: 原始数据不出域,数据可用不可见、数据使用可控可计量、数据可算不可识。
2、隐私计算产品需要通用的安全分级和评测方式。
3、隐私计算需要通过开源降低门槛促进数据安全流通: 让更多企业轻松使用隐私计算技术、让技术产品的安全可信性更透明、促进数据要素流转中事实标准的发展。
四、隐私计算开源助力数据要素流通
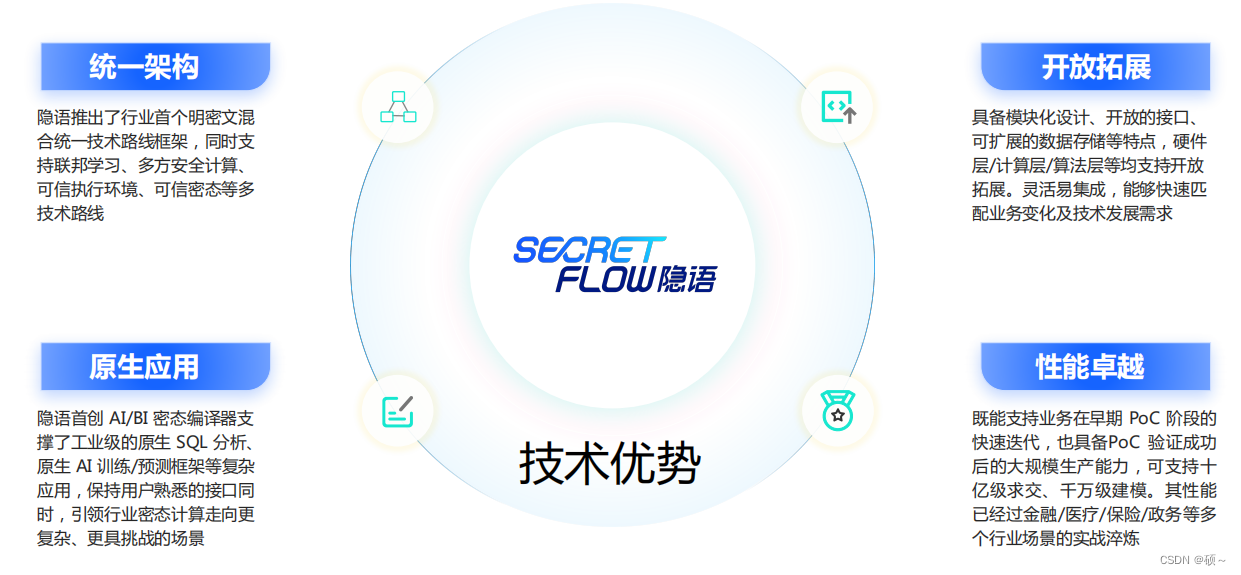
隐语SecretFlow: 其以安全、开放为核心设计理念,支持MPC、FL、TEE 等主流隐私计算技术,融合产学研生态共创能力,助力隐私计算更广泛应用到AI、数据分析等场景中,解决隐私保护和数据孤岛等行业痛点。
优点: 统一架构、原生应用、开放拓展、性能卓越。
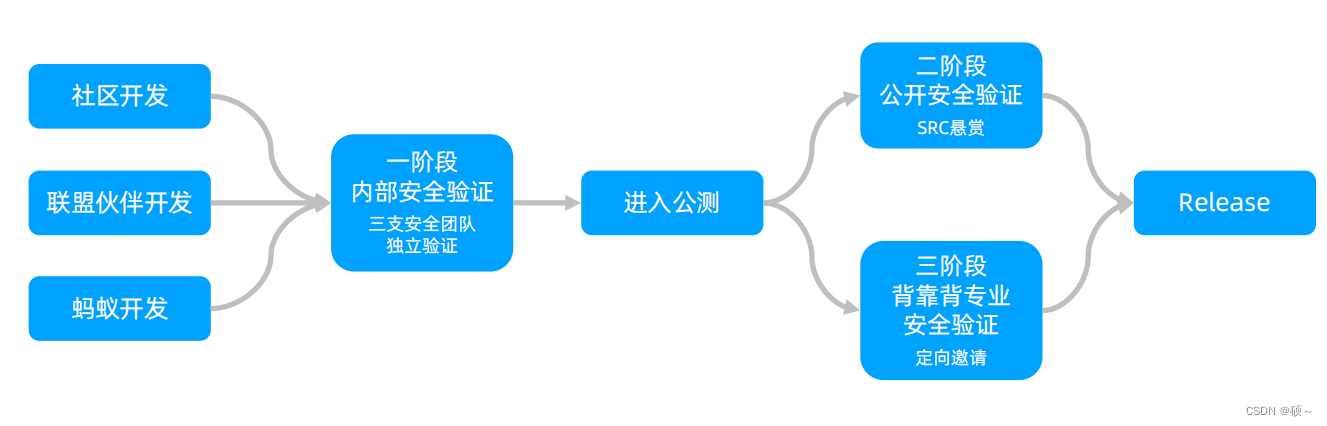
隐语开源经过多轮技术验证:
这篇关于隐私计算实训营学习二:隐私计算开源如何助力数据要素流通的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





