本文主要是介绍超启发式算法综述,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
尽管启发式算法和其他搜索技术已经在解决现实计算搜索问题取得了成功,但再将其应用于相似问题的新实例方面仍存在困难,这些困难主要表现在参数调整和算法选择上,因此需要一种更为通用的搜索方法,即自动化设计和调整启发式算法。
超启发式算法可以看作一种由高层次启发式策略HLH(High-level Heuristic)去操纵管理一系列低级启发式算子LLH(Low-level Heuristic)以此产生高质量的解决方案。
分类
超启发式算法分类考虑了两个维度:
- 启发式搜索空间的性质
- 反馈信息的不同来源
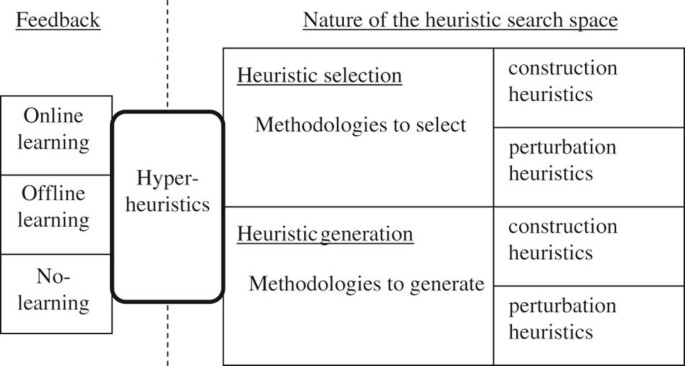
根据搜索空间的性质,可以分为:
- 选择式启发式(Heuristic Selection):选择现有启发式方法
- 生成式启发式(Heuristic Generation): 用于从现有启发式方法的组成部分生成新的启发式方法
这两种方式对应的还有二级分类,即分为构造型启发式和扰动型启发式。其中:
- 构造型启发式(Construction Heuristics):通过考虑完整的候选解并通过修改其中一个或多个解的分量来进行更改
- 扰动型启发式(Perturbation Heuristics):通过考虑部分的候选解并对其进行迭代扩展
构造型启发式和扰动型启发式也可以合并组合在一起用。
当在搜索过程中使用反馈时,超启发式算法是一种学习算法,可以根据反馈信息方式分为:
- 在线学习(Online Learning):学习是在算法解决问题实例的同时进行的
- 离线学习(Offline Learning):从训练实例中以规则或程序的形式收集历史信息,以此推广到其他情况中
超启发式方法中最常用的一种方法就是强化学习:
- 强化学习系统与环境(或环境模型)进行交互并赋予状态,并基于策略采取措施。通过反复试验,系统尝试通过累积奖励来评估状态和动作对,从而了解要执行哪些动作。在超启发式方法的背景下,根据搜索过程中每个启发式方法的表现来奖励和惩罚每种启发式方法。如果低级别的启发式方法可以改善解决方案,则它会得到奖励,并且其分数会得到积极更新,而恶化的举动会通过降低其启发式值来惩罚启发式方法。可以设计不同的操作员组合以进行奖惩。
接受策略是本地搜索的重要组成部分,接受策略可以分为:
- 确定性 :无论搜索过程中的决策点如何,都做出相同的接受决策
- 非确定性:做出不同的接受决策
[1] Burke, E., Gendreau, M., Hyde, M. et al. Hyper-heuristics: a survey of the state of the art. J Oper Res Soc 64, 1695–1724 (2013). https://doi.org/10.1057/jors.2013.71
[2] Chakhlevitch K., Cowling P. (2008) Hyperheuristics: Recent Developments. In: Cotta C., Sevaux M., Sörensen K. (eds) Adaptive and Multilevel Metaheuristics. Studies in Computational Intelligence, vol 136. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-79438-7_1
这篇关于超启发式算法综述的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









