本文主要是介绍YOLO_you only look once,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
计算机图形学的课程即将结束,我需要提交一份关于YOLO模型的学习报告。在这段时间里,我对YOLO进行了深入的学习和研究,并记录下了我的学习过程和心得体会。本文将详细介绍YOLO模型的原理、优缺点以及应用领域,希望能够为后续学习者提供参考和启发。
YOLO介绍
YOLO(You Only Look Once)是一种利用卷积神经网络进行目标检测的算法。它的特点是只需扫视一次图像,就能够确定图像中物体的类别和位置。由于只需看一次,YOLO被称为无区域(Region-free)的方法,与基于区域(Region-based)的方法不同,后者需要先找出图像中可能存在物体的区域。 也就是说,一个典型的基于区域的方法的流程是这样的:先用计算机图形学(或者深度学习)的方法,对图像进行分析,找出一些可能含有物体的区域,然后将这些区域裁剪下来,放入一个图像分类器中,进行分类。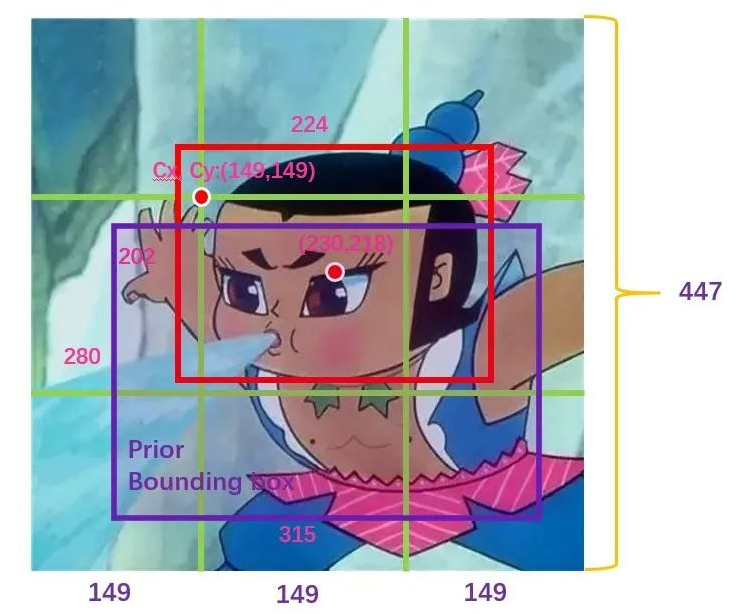
YOLO是一种单阶段(one-stage)的算法,它与双阶段(two-stage)的算法,如R-CNN,不同,YOLO不需要先找出图像中可能存在物体的区域,而是将图像划分为多个网格(grid),每个网格预测多个边界框(bounding box)和类别概率。 YOLO的优势是速度快,适合实时检测的场景,但是它的准确度相对较低,容易出现漏检和误检的情况。YOLO目前已经发展到第八代(计算机更新迭代真是快啊,想想第一代YOLO还是2015年的事),每一代都在前一代的基础上进行了改进和提高。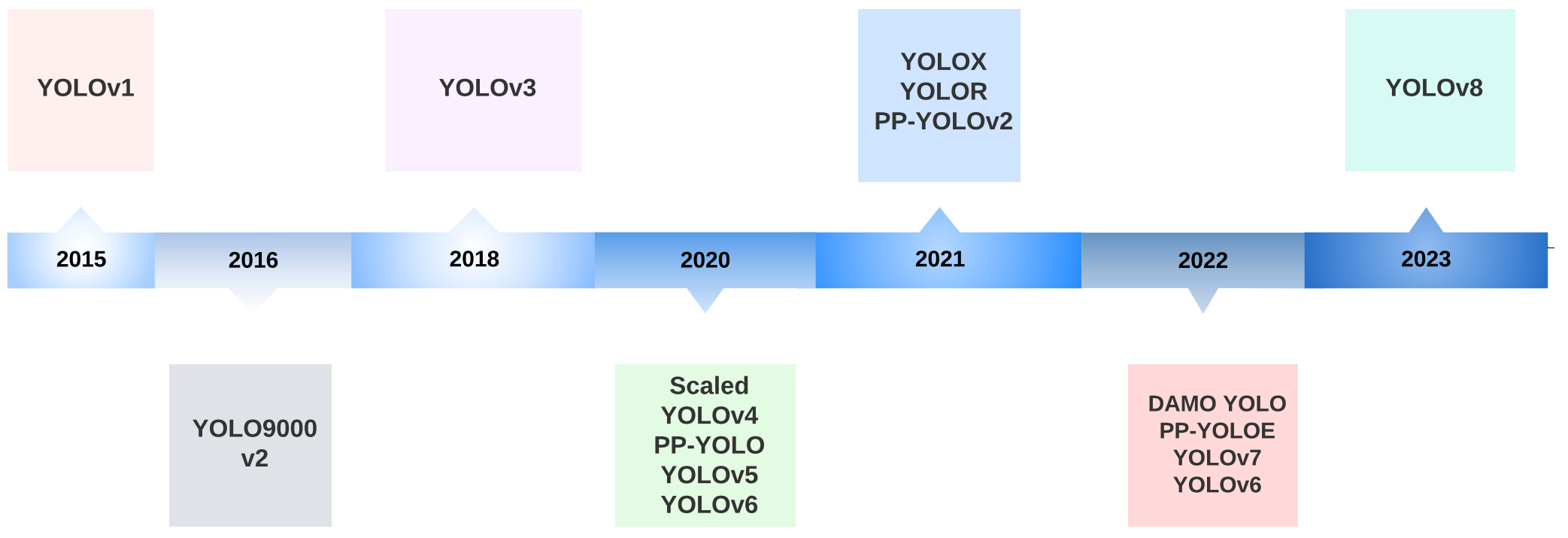
Yolo以前的世界
YOLO算法是在近年来才出现和发展的,它改变了物体检测领域的面貌。YOLO以前的世界主要使用了以下3种物体检测算法:
- 滑动窗口法:这种方法是最简单和最直观的,它通过在图像上滑动不同大小和形状的窗口,然后对每个窗口内的图像进行分类,来检测物体。这种方法的优点是可以检测任意形状的物体,但是缺点是非常慢,因为它需要对图像的每个位置和尺度进行分类,计算量非常大。
- 基于区域的方法:这种方法是在滑动窗口法的基础上进行改进,它通过一些技术,如选择性搜索(Selective Search),来生成一些可能包含物体的候选区域,然后对这些区域进行分类和回归,来检测物体。这种方法的优点是可以减少计算量,提高检测速度,但是缺点是生成的候选区域可能不准确,导致漏检或误检的情况。
- 基于区域的卷积神经网络(R-CNN)方法:这种方法是在基于区域的方法的基础上,引入了卷积神经网络(CNN)来提取图像特征,然后对这些特征进行分类和回归,来检测物体。这种方法的优点是可以利用CNN的强大的特征提取能力,提高检测的准确性,但是缺点是仍然需要生成候选区域,而且对每个区域都需要单独进行CNN的前向传播,计算量仍然很大。
All in all,没有YOLO的世界,非常“暗淡”。
YOLO的优缺点
优点:
- 速度快:这是因为它只需要看一次整张图片,就可以直接输出所有检测到的目标的信息,包括类别和位置。而且它也不需要像二阶段的算法那样先生成候选区域,再对每个区域再进行分类和回归,这样就可以大大的减少了计算量和时间。
- 全局信息:YOLO算法会基于整张图片的全局信息进行预测,然后其他滑窗式的检测框架,只能基于局部图片信息进行推理。这样可以降低背景的误检率,提高检测的准确性。
- 通用特征:YOLO算法学到的图片特征更为通用,可以适应不同的场景和任务。而且它在艺术品的检测上准确率高于其他的检测算法。
缺点:
- 准确性较差:这是因为它将图片分割为多个网格,而每个网格只能预测固定数量的边界框和类别。如果图像中存在多物体密集挨着的时候或者小目标的时候,那检测效果不好。
- 召回率较低:因为它对目标的尺度和形状的变化不够敏感,容易漏检一些目标。它也没有考虑目标之间的上下文关系,可能会误检一些不相关的物体。
- 计算资源需求高:YOLO算法的网络结构较大且复杂,模型对计算资源需求较高,不适用于资源受限的设备。它的模型大小也较大,可能对部署和存储造成一定的挑战。
YOLO应用领域
首先要说的是YOLO真的是一项非常强大的算法,涉及的领域非常广,主要涉及网络结构、损失函数、锚框和输入分辨率等方面。现在YOLO已经被广泛应用于各个领域,如自动驾驶、器人、视频监控、医学诊断、遥感分析等。
YOLO是一种实时目标检测算法,它可以快速地识别出图像中的物体的类别和位置。YOLO可以应用于多个领域,如:
- 自动驾驶和机器人:YOLO可以检测和跟踪车辆、行人、自行车和其他障碍物,提高安全性和效率 。
- 视频监控和分析:YOLO可以识别视频序列中的动作、人物、表情和场景,用于安防、体育、人机交互等应用 。
- 农业和生物识别:YOLO可以检测和分类作物、害虫、疾病和动物,协助精准农业和生物多样性保护 。
- 医学和健康:YOLO可以检测癌症、皮肤病、药片等,提高诊断的准确性和治疗的效果 。
- 遥感和城市规划:YOLO可以检测和分类卫星和航空图像中的物体,如建筑、道路、水体、森林等,用于土地利用、灾害评估、城市发展等应用 。
结论
YOLO是一种非常强大和灵活的算法,它可以适应不同的场景和任务,为人类的生活和工作带来便利和价值。然而,我们也要认识到它的局限性和挑战,如准确性较差、召回率较低以及计算资源需求高等。在未来的研究和应用中,可以进一步改进YOLO算法,提高其性能和适用性,为计算机领域的发展做出更大的贡献。
这篇关于YOLO_you only look once的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


![[数据集][目标检测]血细胞检测数据集VOC+YOLO格式2757张4类别](https://i-blog.csdnimg.cn/direct/22c867ab717d44c78b985ed667169b42.png)
![[数据集][目标检测]智慧农业草莓叶子病虫害检测数据集VOC+YOLO格式4040张9类别](https://i-blog.csdnimg.cn/direct/4a9ca83db964467783f221a1fd15ab5b.png)


![[数据集][目标检测]抽烟检测数据集VOC+YOLO格式22559张2类别](https://i-blog.csdnimg.cn/direct/cda7c7a3ea8348c5a8f4cddff90c679c.png)
![[数据集][目标检测]人脸口罩佩戴目标检测数据集VOC+YOLO格式8068张3类别](https://i-blog.csdnimg.cn/direct/088e80f82eb14e728a652ec9ba9fc6d4.png)

![[数据集][目标检测]井盖丢失未盖破损检测数据集VOC+YOLO格式2890张5类别](https://i-blog.csdnimg.cn/direct/31cf5cd2f3cd4257a13e5fb30d7908a0.png)