本文主要是介绍【翻译】A Neural Conversational Model,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文:http://arxiv.org/abs/1506.05869
摘要
对话建模是自然语言理解和机器智能中的一个重要任务。尽管已经存在先前的方法,但它们通常限制在特定领域(例如,预订机票)并需要手工制定规则。在本文中,我们提出了一种简单的方法来处理这一任务,它使用了最近提出的序列到序列框架。我们的模型通过预测给定之前的一句或多句对话后的下一句来进行对话。我们模型的优势在于它可以端到端地训练,因此需要更少的手工制定规则。我们发现,这个简单的模型在给定大量对话训练数据集的情况下,可以生成简单的对话。我们的初步结果表明,尽管优化了错误的目标函数,模型仍然能够很好地进行对话。它能够从特定领域的数据集以及大型、嘈杂、通用领域的电影字幕数据集中提取知识。在特定领域的IT服务台数据集上,模型可以通过对话找到技术问题的解决方案。在嘈杂的开放领域电影剧本数据集上,模型可以执行简单形式的常识推理。正如预期的那样,我们还发现,缺乏一致性是我们模型的一个常见失败模式。
1.介绍:
端到端训练神经网络的进步在许多领域如语音识别、计算机视觉和语言处理等领域取得了显著进展。最近的研究表明,神经网络不仅仅能做分类任务,它们还可以用来将复杂结构映射到其他复杂结构。这方面的一个例子是将一个序列映射到另一个序列的任务,这在自然语言理解中有直接应用(Sutskever et al., 2014)。这个框架的主要优势是,它几乎不需要特征工程和领域特异性,同时能够匹配或超越最先进的结果。我们认为,这一进步使研究人员可以处理那些领域知识可能不容易获得的任务,或者那些设计规则过于困难的任务。
对话建模可以直接从这种形式中受益,因为它需要在查询和回复之间进行映射。由于这种映射的复杂性,对话建模以前被设计得非常狭窄,需要大量的特征工程。在这项工作中,我们通过将对话建模任务转化为使用循环网络(Sutskever et al., 2014)预测给定前一序列或序列的下一序列的任务来进行实验。我们发现这种方法在生成流畅且准确的对话回复方面表现出奇的好。
我们在 IT helpdesk数据集的聊天会话上测试了该模型,并发现该模型有时可以追踪问题并为用户提供有用的答案。我们还使用从电影字幕的嘈杂数据集中获取的对话进行了实验,发现该模型可以进行自然对话,有时甚至能执行简单形式的常识推理。在这两种情况下,与n-gram模型相比,循环网络获得了更好的困惑度,并捕获了重要的长距离相关性。从定性的角度来看,我们的模型有时能够产生自然的对话。
2. 相关工作
我们的方法基于最近的工作,该工作提出使用神经网络将序列映射到序列(Kalchbrenner & Blunsom, 2013; Sutskever et al., 2014; Bahdanau et al., 2014)。这个框架已经被用于神经机器翻译,并在WMT’14数据集的英法和英德翻译任务上取得了改进(Luong et al., 2014; Jean et al., 2014)。它也被用于其他任务,如解析(Vinyals et al., 2014a)和图像描述(Vinyals et al., 2014b)。由于众所周知普通的循环神经网络(RNN)存在梯度消失问题,大多数研究者使用长短期记忆(LSTM)循环神经网络的变体(Hochreiter & Schmidhuber, 1997)。
我们的工作还受到了最近神经语言建模成功的启发(Bengio et al., 2003; Mikolov et al., 2010; Mikolov, 2012),这表明循环神经网络对自然语言而言是相当有效的模型。最近,Sordoni et al.(Sordoni et al., 2015)和Shang et al.(Shang et al., 2015)的工作使用循环神经网络来模拟短对话(在Twitter风格的聊天中训练)中的对话。
在过去的几十年中,许多研究者一直在构建机器人和对话代理,本文的范围之外是提供一个详尽的参考列表。然而,这些系统中的大多数都需要一个相当复杂的多阶段处理流程(Lester et al., 2004; Will, 2007; Jurafsky & Martin, 2009)。我们的工作与传统系统不同之处在于,我们提出了一种端到端的方法来解决缺乏领域知识的问题。原则上,它可以与其他系统结合使用,以对候选回答的短列表进行重新评分,但我们的工作是基于生成由概率模型给出的答案,该模型经过训练以最大化给定一些上下文的答案的概率。
3. 模型
我们的方法利用了(Sutskever et al., 2014)中描述的序列到序列(seq2seq)框架。该模型基于一个循环神经网络,它一次读取一个输入序列的标记,并预测输出序列,也是一次一个标记。在训练过程中,真实的输出序列被提供给模型,因此学习可以通过反向传播来完成。该模型被训练以最大化给定其上下文的正确序列的交叉熵。在推断过程中,由于真实的输出序列没有被观察到,我们简单地将预测的输出标记作为输入来预测下一个输出。这是一种“贪婪”的推断方法。一种不那么贪婪的方法是使用束搜索,并在前一步将几个候选项提供给下一步。根据序列的概率可以选择预测的序列。
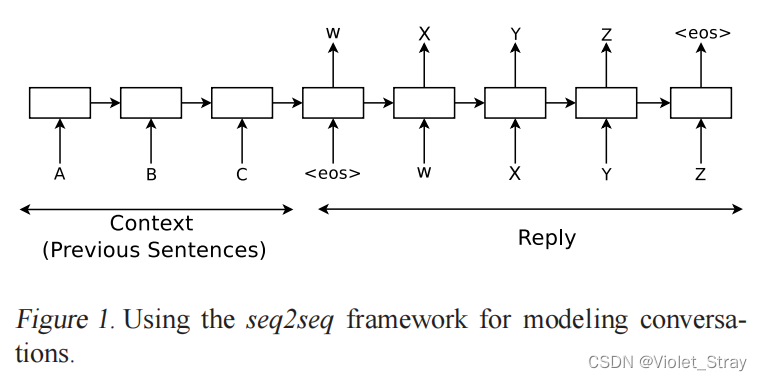
具体来说,假设我们观察到一个有两个轮次的对话:第一个人说“ABC”,第二个人回答“WXYZ”。我们可以使用一个循环神经网络,并训练将“ABC”映射到“WXYZ”,如上图1所示。当模型接收到序列结束符号“”时的隐藏状态可以被视为思想向量,因为它存储了句子或思想“ABC”的信息。
这个模型的优势在于其简单性和通用性。我们可以使用这个模型进行机器翻译、问题回答和对话,而无需在架构上进行重大改变。将这种技术应用于对话建模也很直接:输入序列可以是到目前为止已经进行的对话的串联(上下文),输出序列是回复。
然而,与翻译等较容易的任务不同,像序列到序列这样的模型将无法成功地“解决”对话建模的问题,因为存在几个明显的简化:被优化的目标函数并没有捕捉到通过人类交流实现的实际目标,后者通常是基于信息交换的长期目标,而不是下一步预测。缺乏模型来确保一致性和一般世界知识是纯粹无监督模型的另一个明显限制。
4.模型
在我们的实验中,我们使用了两个数据集:一个封闭领域的IT帮助台故障排除数据集和一个开放领域的电影剧本数据集。这两个数据集的详细信息如下。
4.1 IT Helpdesk Troubleshooting数据集
在我们的第一组实验中,我们使用了从IT帮助台故障排除聊天服务中提取的数据集。在这项服务中,客户面临与计算机相关的问题,专家通过交谈并指导解决方案来帮助他们。典型的互动(或线程)长约400个单词,且轮流发言被清楚地标示出来。我们的训练集包含3000万个标记,300万个标记被用作验证。进行了一些清理工作,例如删除常见的姓名、数字和完整的网址。
4.2 OpenSubtitles 数据集
我们还在 OpenSubtitles 数据集(Tiedemann, 2009)上测试了我们的模型。该数据集包含以 XML 格式的电影对话。它包含电影角色说出的句子。我们应用了一个简单的处理步骤,从数据集中删除了 XML 标签和明显的非对话文本(例如,超链接)。由于未明确指示轮流发言,我们将连续的句子视为由不同角色发出。我们训练我们的模型根据前一句来预测下一句,并且我们对每个句子都这样做(注意这将我们的数据集大小翻倍,因为每个句子既用作上下文又用作目标)。我们的训练和验证划分有 6200 万句子(9.23 亿个标记)作为训练示例,验证集有 2600 万句子(3.95 亿个标记)。划分方式是这样的:每对句子中的每个句子要么一起出现在训练集中,要么一起出现在测试集中,但不会同时出现。与前一个数据集不同,OpenSubtitles 数据集相当大,并且相当嘈杂,因为连续的句子可能由同一角色发出。鉴于电影的广泛范围,这是一个开放领域的对话数据集,与技术故障排除数据集形成对比。
5.实验
在本节中,我们描述了使用两个数据集的实验结果,并展示了我们训练的系统与人类交互的一些样本。我们还使用一组200个问题的人类评估,将我们系统的性能与流行的基于规则的机器人(CleverBot1)进行比较。
5.1 IT Helpdesk Troubleshooting实验
在这个实验中,我们使用随机梯度下降和梯度裁剪训练了一个单层LSTM,该LSTM具有1024个存储单元。词汇表由最常见的20K个单词组成,其中包括指示轮换和演员的特殊标记。
在收敛时,该模型达到了8的困惑度,而n-gram模型达到了18。以下是针对最常见的三个IT问题(远程访问、软件崩溃和密码问题)的一些模拟故障排除会话样本。在这些对话中,Machine是我们的神经对话模型,Human是与之交互的人类演员。
对话1:VPN问题。
描述您的问题:我在访问vpn时遇到问题。

5.2 OpenSubtitles实验
在这个实验中,我们使用AdaGrad和梯度裁剪训练了一个两层的LSTM。LSTM的每一层都有4096个存储单元,我们构建了一个包含最常见的10万个单词的词汇表。为了加速softmax,我们在将信息传递给分类器之前,将存储单元投影到2048个线性单元。
在收敛时,循环模型在验证集上的困惑度为17。我们的平滑5-gram模型达到了28的困惑度。有趣的是,添加(Bahdanau et al., 2014)的软注意力机制并没有显著改善训练集或验证集上的困惑度。
5.2.1 模型样本
除了困惑度指标之外,我们的简单循环模型经常产生合理的答案。以下是一些样本问答对,它们让我们了解了在训练有噪声但庞大的电影OpenSubtitles数据集时模型的能力。同样,在这些对话中,Machine是我们的神经对话模型,Human是与之交互的人类演员。
(对话略)
我们发现鼓舞人心的是,模型能够记住事实、理解上下文、在没有传统流程复杂性的情况下进行常识推理。令我们惊讶的是,模型能够做到这一点,除了词向量中的参数外,没有任何显式的知识表示组件。
也许最实际重要的是,模型可以泛化到新问题。换句话说,它不仅仅通过将问题与现有数据库匹配来寻找答案。实际上,上面提出的大多数问题,除了第一个对话外,都没有出现在训练集中。
尽管如此,这个基本模型的一个缺点是它只能给出简单、短暂、有时不令人满意的答案,如上所示。也许更为问题的是,模型没有捕捉到一致的个性。实际上,如果我们提出不完全相同但语义上相似的问题,答案有时可能是不一致的。由于我们模型和实验中的数据集的简单性,这是预期的。下面的对话展示了这种失败:
5.2.2 人类评估
为了公平和客观地比较我们的模型和CleverBot,我们挑选了200个问题,让四位不同的人类评价者对我们的模型(NCM)和CleverBot(CB)进行评分。人类评价者被要求选择他们更喜欢的两个机器人之一,并且如果两个答案的质量相等,他们也被允许宣布平局。
如果四位人类评价者中有三位达成一致,我们就记录这个评分。我们的模型在200个问题中有97个被偏爱,而CleverBot在200个问题中有60个被选择。有20个问题是平局,还有23个问题评价者之间存在分歧。
以下是一些评价者如何评价系统的样本(我们用粗体显示他们偏爱的答案,第三个例子显示了平局,第四个例子显示了分歧):
(对话例子略)
然而,我们认为设计一个好的指标来快速衡量对话模型的质量仍然是一个开放的研究问题。我们通过手动检查、使用Mechanical Turk来获取与基于规则的机器人进行比较的人类评估以及计算困惑度来做到这一点。然而,使用这些方法显然存在缺点,我们正在积极地追求这个和其他研究方向。
6.讨论
在本文中,我们展示了一个基于seq2seq框架的简单语言模型可以用来训练一个对话引擎。我们的初步结果显示,它可以生成简单和基本的对话,并从一个嘈杂但开放领域的数据集中提取知识。尽管模型有明显的限制,但令我们惊讶的是,一个纯粹基于数据的方法,没有任何规则,却能产生相当正确的回答。然而,模型可能需要大量的修改才能提供现实的对话。在众多的限制中,缺乏一致的个性使我们的系统难以通过图灵测试(Turing, 1950)。
致谢
我们感谢Greg Corrado、Andrew Dai、Jeff Dean、Tom Dean、Matthieu Devin、Rajat Monga、Mike Schuster、Noam Shazeer、Ilya Sutskever和Google Brain团队对该项目的帮助。
这篇关于【翻译】A Neural Conversational Model的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!