本文主要是介绍研报复现 | 优加换手率策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本策略根据东吴证券研报《“技术分析拥抱选股因子”系列研究(八):优加换手率:解决1+1<2的难题》提出一种“优加法”,构建了“优加换手率 UTR 因子” ,表现明显优于传统的组合方式。
量稳与量小换手率因子的相互碰撞,产生了与单因子逻辑相矛盾之处:同时满足“量最稳”、“量最小” 的股票,未来表现并非最强;在量较稳的样本中,反而是量越大的股票, 未来表现越好。其中,量小换手率因子为传统的换手率因子。
通过“优加法”对量小换手率因子和量稳换手率因子进行计算组合,得到优加换手率因子,根据因子值进行交易。
本策略运行所基于的环境:python3.8 掘金终端IDE
一、策略思路
1、计算量小换手率因子 Turn20 :以 20 日换手率为例,即每月月底计算每只股票过去 20 个交易日的日均换手率,做市值中性化处理;
2、计算量稳换手率因子 STR:每月月底,回溯每只股票过去 20 个交易日,计算 20 日换手率的标准差,做市值中性化处理;
3、计算优加换手率因子 UTR:
a.每月月底,计算所有股票的量小因子 Turn20 和量稳因子 STR;
b.先将所有样本按照量稳因子从小到大排序,打分 1,2,……,N-1,N,N 为当期样本数量,记为“得分 1”;为了方便表述,暂且假定 N 为偶数;
c.取量稳因子排名靠前的 50%样本,再将它们按照量小因子从大到小排序,打分1,2,……,N/2,记为“得分 2”;“得分 1”+“得分 2”,即为这些股票的最终得分;
d.对于量稳因子排名靠后的 50%样本,则将它们按照量小因子从小到大排序, 打分1,2,……,N/2,记为“得分 3”;这些股票的最终得分为“得分 1”+“得分 3”;
所有样本的上述最终得分,即为优加换手率因子的因子值。
4、按照因子值对所有样本排序,做 10 分组回测。
5、对每组中最终得分最小的10%的股票进行买入。
二、策略逻辑
· 第一步:设置参数
· 第二步:每月第一个交易日定时执行algo任务,按策略思路筛选股票
· 第三步:不在股票池的股票全部卖出,对股票池中的股票进行买入
· 回测期:2019-01-01 08:00:00 到 2020-12-31 16:00:00
· 回测初始资金:1000万
· 手续费:0.0001
· 滑点:0.0001
三、回测结果与稳健性分析
我们进行了10分组回测,下图为每组的回测结果。


可见,其中第一组的回测结果是较好的,回测期策略累计收益率为94.26%,年化收益率为47.06%,最大回撤为8.05%,夏普比率为2.28,胜率为56.72%。
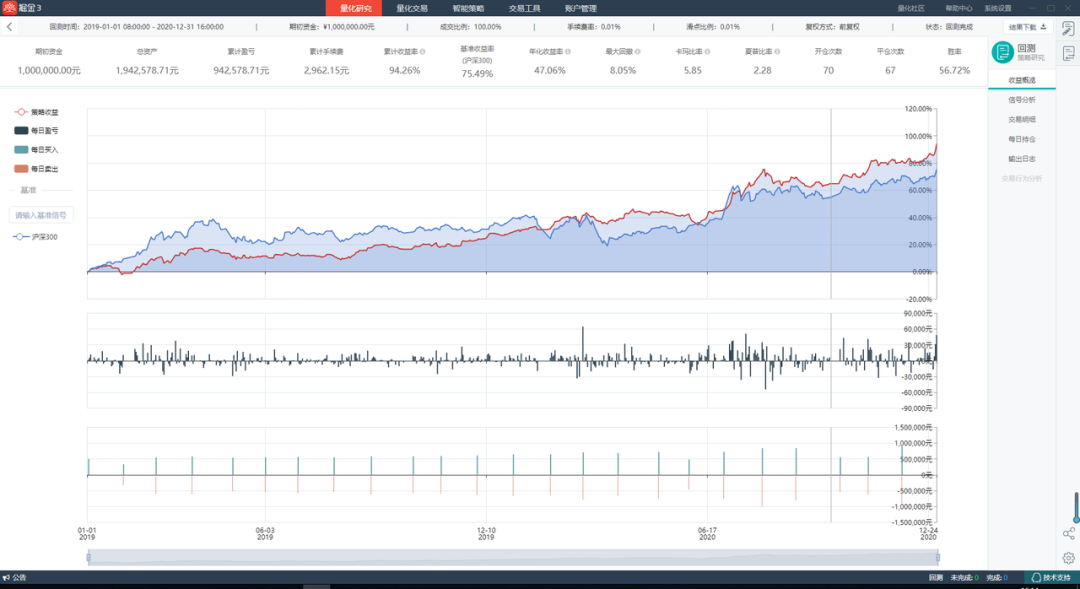
(本次回测报告由掘金量化提供)
四、策略代码
# coding=utf-8
from __future__ import print_function, absolute_import, unicode_literals
from sklearn.linear_model import LinearRegression
import multiprocessing
import numpy as np
import pandas as pd
from gm.api import *'''
本策略计算优加换手率因子,通过10分组回测筛选有效因子;
10分组回测基本思想:设定所需优化的参数数值范围及步长,将参数数值循环输入进策略,进行遍历回测,记录每次回测结果和参数,根据某种规则将回测结果排序,找到最好的参数。
1、定义策略函数
2、多进程循环输入参数数值
3、获取回测报告,生成DataFrame格式
4、排序
'''# 原策略中的参数定义语句需要删除!
def init(context):# 每月的第一个交易日的09:40:00执行策略algoschedule(schedule_func=algo, date_rule='1m', time_rule='9:40:00')# 设置交易标的context.symbol = None# 设置买入股票资金比例context.ratio = 0.5def MAD(data, N):"""---N倍中位数去极值---1 求所有因子的中位数 median2 求每个因子与中位数的绝对偏差值,求得到绝对偏差值的中位数 new_median3 根据参数 N 确定合理的范围为 [median−N*new_median,median+N*new_median],并针对超出合理范围的因子值做调整"""median = data.quantile(0.5)new_median = abs(data - median).quantile(0.5)# 定义N倍的中位数上下限high = median + N * new_medianlow = median - N * new_median# 替换上下限data = np.where(data > high, high, data)data = np.where(data < low, low, data)return data如需获取完整源码,请点击下方链接查看:
研报复现 | 优加换手率策略 - 掘金量化社区 - 量化交易者的交流社区
声明:本内容首发至掘金量化公众号与掘金量化社区,仅供学习、交流、演示之用,不构成任何投资建议!如需转载原创文章请联系掘金小Q(myquant2018)。

掘金量化-集数据、投研、实盘交易的一站式专业量化平台
这篇关于研报复现 | 优加换手率策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




