本文主要是介绍【Intel校企合作课程】基于ResNet18实现猫狗大战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1作业简介
1.1问题描述
在这个问题中,你将面临一个经典的机器学习分类挑战——猫狗大战。你的任务是建立一个分类模型,能够准确地区分图像中是猫还是狗。
1.2预期解决方案
你的目标是通过训练一个机器学习模型,使其在给定一张图像时能够准确地预测图像中是猫还是狗。模型应该能够推广到未见过的图像,并在测试数据上表现良好。我们期待您将其部署到模拟的生产环境中——这里推理时间和二分类准确度(F1分数)将作为评分的主要依据。
1.3数据集
链接:https://pan.baidu.com/s/1vyJUrX9iA0Z-L_Xxtx3e1g
提取码:1227
1.4图像显示



2数据预处理
本数据集经划分后分成了两部分,train训练集,test测试集
2.1数据集结构
train训练集和test测试集下都有有cats和dogs文件夹,训练时文件夹的名字将会作为标签,即在cats文件夹里的图片标签是猫,dogs文件夹里的图片标签是狗。一开始我并没有进行划分子文件夹,因为每张图片都有含有cat或者dog,就直接使用图片名作为标签,但是这样放到模型去训练的时候需要耗费大量的时间,训练时间远比分子文件夹要多。
cats子文件夹下的部分图片(dogs子文件夹类似)
2.2统计训练集和测试集的大小
def count_images_in_folder(folder_path):cat_count = len([file for file in os.listdir(os.path.join(folder_path, 'cats')) if file.endswith('.jpg')])dog_count = len([file for file in os.listdir(os.path.join(folder_path, 'dogs')) if file.endswith('.jpg')])return cat_count, dog_counttrain_folder_path = '../Cats vs Dogs/train' # 训练集文件路径
test_folder_path = '../Cats vs Dogs/test' # 测试集文件路径train_cat_count, train_dog_count = count_images_in_folder(train_folder_path)
test_cat_count, test_dog_count = count_images_in_folder(test_folder_path)print(f"Train set: Cats - {train_cat_count} images, Dogs - {train_dog_count} images")
print(f"Test set: Cats - {test_cat_count} images, Dogs - {test_dog_count} images")运行结果

训练集共25000张图片,其中猫的图片有12500张,狗的图片有12500张
测试集共1000张图片,其中猫的图片有500张,狗的图片有500张
2.3查看测试集部分图片
from PIL import Image
import os
import random
import matplotlib.pyplot as pltdef show_random_images(folder_path, num_images=3):cat_files = [file for file in os.listdir(os.path.join(folder_path, 'cats')) if file.endswith('.jpg')]dog_files = [file for file in os.listdir(os.path.join(folder_path, 'dogs')) if file.endswith('.jpg')]random_cat_files = random.sample(cat_files, num_images)random_dog_files = random.sample(dog_files, num_images)for cat_file, dog_file in zip(random_cat_files, random_dog_files):cat_path = os.path.join(folder_path, 'cats', cat_file)dog_path = os.path.join(folder_path, 'dogs', dog_file)cat_image = Image.open(cat_path)dog_image = Image.open(dog_path)# Display the imagesplt.figure(figsize=(8, 4))plt.subplot(1, 2, 1)plt.imshow(cat_image)plt.title('Cat')plt.subplot(1, 2, 2)plt.imshow(dog_image)plt.title('Dog')plt.show()train_folder_path = '../Cats vs Dogs/train'
show_random_images(train_folder_path, num_images=3) 显示图片
2.4数据处理
# 数据预处理
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])# 创建自定义Dataset
class CatDogDataset(Dataset):def __init__(self, folder_path, transform=None):self.folder_path = folder_pathself.transform = transformself.cat_files = [file for file in os.listdir(os.path.join(folder_path, 'cats')) if file.endswith('.jpg')]self.dog_files = [file for file in os.listdir(os.path.join(folder_path, 'dogs')) if file.endswith('.jpg')]def __len__(self):return len(self.cat_files) + len(self.dog_files)def __getitem__(self, index):if index < len(self.cat_files):img_path = os.path.join(self.folder_path, 'cats', self.cat_files[index])label = 0 # 0 represents catelse:img_path = os.path.join(self.folder_path, 'dogs', self.dog_files[index - len(self.cat_files)])label = 1 # 1 represents dogimg = Image.open(img_path).convert('RGB')if self.transform:img = self.transform(img)return img, label先将训练集的图片统一标准,方便训练,调整图像大小为 (224, 224) 像素,将图片转化成Pytorch张量,同时对图像进行标准化,标准化的目的是将图像的像素值缩放到一个较小的范围,以便更好地适应模型的训练。在这里,给定了均值(mean)和标准差(std),它们用于调整图像的像素值。
创建一个自定义的dataset,用于加载数据集,并在训练模型时使用,同时根据路径给各个图片打了标签。
3模型训练
这里采用的模型是预训练的ResNet18(Residual Network with 18 layers),ResNet18是一个深度卷积神经网络架构,属于ResNet系列的一部分。ResNet系列是由微软研究院提出的,通过引入残差学习(residual learning)的概念来解决深度神经网络训练过程中的梯度消失和梯度爆炸问题。
3.1ResNet18
以下是ResNet18的主要特点和架构:
-
残差学习: ResNet引入了残差块(Residual Block),使得网络可以学习残差映射。每个残差块包含跳跃连接(skip connection),允许信息在网络中直接传递,而不是仅通过层层传递。这有助于解决梯度消失问题,使得可以训练更深的网络。
-
ResNet18结构: ResNet18由基础的卷积层、池化层、残差块等组成。整体架构较浅,共有18个可学习的层。下面是ResNet18的基本结构:
- 输入层:3x224x224 的图像(RGB通道)。
- 预处理:7x7卷积层、最大池化,逐步减小图像尺寸。
- 残差块:包含多个残差块,其中每个块都包含两个卷积层和一个跳跃连接。
- 全局平均池化:对特征图进行全局平均池化,减少参数数量。
- 全连接层:输出最终的分类结果。
-
激活函数: 在ResNet中,常用的激活函数是修正线性单元(ReLU),它在每个残差块中被使用。
-
全局平均池化: ResNet采用全局平均池化来减少参数数量,将最后的特征图的每个通道的值取平均作为整个通道的池化值。
ResNet18相对较浅,适用于一些计算资源有限的场景(我这里全程使用CPU跑,有条件的可用使用GPU,模型训练时间将会大大缩短),同时在许多图像分类任务中表现出色。由于其简单而有效的结构,ResNet18经常被用作迁移学习的基础模型,用于处理各种计算机视觉任务。
3.2搭建模型
3.2.1数据集的划分
- 通过 CatDogDataset 类加载整个训练集,并应用了数据预处理操作 transform。
- 使用 random_split 函数将整个数据集划分为训练集(80%)和验证集(20%)。train_dataset 和 val_dataset 分别表示训练集和验证集。
from torch.utils.data import random_splitfull_dataset = CatDogDataset(train_folder_path, transform=transform)
train_size = int(0.8 * len(full_dataset))
val_size = len(full_dataset) - train_size
train_dataset, val_dataset = random_split(full_dataset, [train_size, val_size])3.2.2数据加载器的创建
- 使用 DataLoader 创建了训练集和验证集的数据加载器 (train_loader 和 val_loader)。
- batch_size=32 指定了每个小批量的样本数,shuffle=True 表示在每个epoch开始前打乱数据顺序,以增加模型训练的随机性。
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32)
3.2.3模型的定义
- 使用 models.resnet18(pretrained=True) 加载了预训练的ResNet18模型。这里的 pretrained=True 表示加载在ImageNet上预训练得到的权重。
- 修改了模型的最后一层 (model.fc),将输出维度从512修改为2,以适应猫狗图像分类的二分类任务。
# 定义模型
model = models.resnet18(pretrained=True)
model.fc = nn.Linear(512, 2) # 修改最后一层,适应二分类任务3.2.4损失函数和优化器的定义
- 使用交叉熵损失函数 (nn.CrossEntropyLoss()) 来计算模型输出与标签之间的损失。
- 使用Adam优化器 (optim.Adam) 来更新模型的参数,学习率为0.001。
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)3.3模型训练
3.3.1训练模型
- 使用
num_epochs指定了训练的总epoch数。 - 使用
torch.device将模型移动到GPU(如果可用),或者保持在CPU上。 - 创建了两个空列表
train_losses和val_accuracies,用于保存每个epoch的训练损失和验证准确率。
# 记录训练开始时间
start_time = time.time()
# 训练模型
num_epochs = 10
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)# 训练过程中保存损失函数和准确率
train_losses = []
val_accuracies = []3.3.2训练循环
- 对于每个epoch,模型分别处于训练(
model.train())和评估(model.eval())模式。 - 在训练模式下,使用
train_loader遍历训练集,进行模型的训练。计算训练集上的损失并进行反向传播优化。 - 在评估模式下,使用
val_loader在验证集上评估模型。计算验证集上的准确率。
for epoch in range(num_epochs):model.train()running_loss = 0.0for inputs, labels in tqdm(train_loader, desc=f'Epoch {epoch + 1}/{num_epochs}', unit='batch'):inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()# 计算训练集损失train_loss = running_loss / len(train_loader)train_losses.append(train_loss)# 在验证集上评估模型model.eval()correct = 0total = 0with torch.no_grad():for inputs, labels in val_loader:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()# 计算验证集准确率val_accuracy = correct / totalval_accuracies.append(val_accuracy)print(f'Epoch {epoch + 1}/{num_epochs} - Training Loss: {train_loss}, Validation Accuracy: {val_accuracy}')3.3.3记录训练时间
在训练开始前记录了训练开始的时间戳,并在训练结束后记录了训练结束的时间戳。通过这两个时间戳的差值,计算了整个训练过程的耗时。
# 记录训练结束时间
end_time = time.time()# 输出训练时间
training_time = end_time - start_time
print(f'Training Time: {training_time} seconds')
3.3.4训练可视化
打印在训练过程中损失函数和验证机准确率的变化
# 可视化损失函数和准确率
plt.figure(figsize=(10, 5))# 绘制损失函数曲线
plt.subplot(2, 1, 1)
plt.plot(range(1, num_epochs + 1), train_losses, label='Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.legend()# 绘制准确率曲线
plt.subplot(2, 1, 2)
plt.plot(range(1, num_epochs + 1), val_accuracies, label='Validation Accuracy', color='orange')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Validation Accuracy over Epochs')
plt.legend()plt.tight_layout()
plt.show()3.3.5模型保存
使用 torch.save 将训练好的模型参数保存到文件 'cat_dog_classifier.pth' 中,以便在之后的任务中加载模型并进行预测。
torch.save(model.state_dict(), 'cat_dog_classifier.pth')3.3.6运行结果
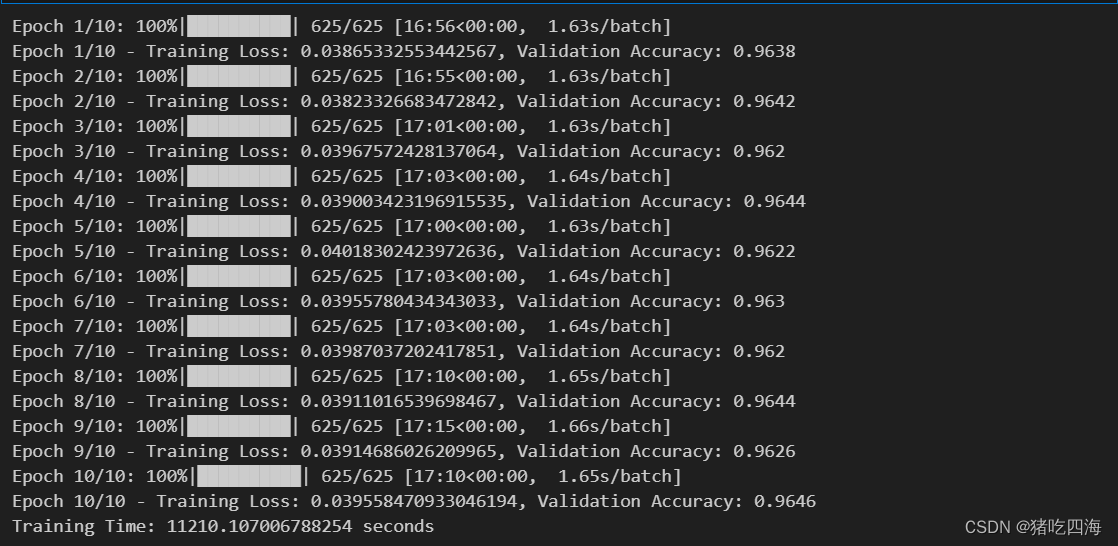
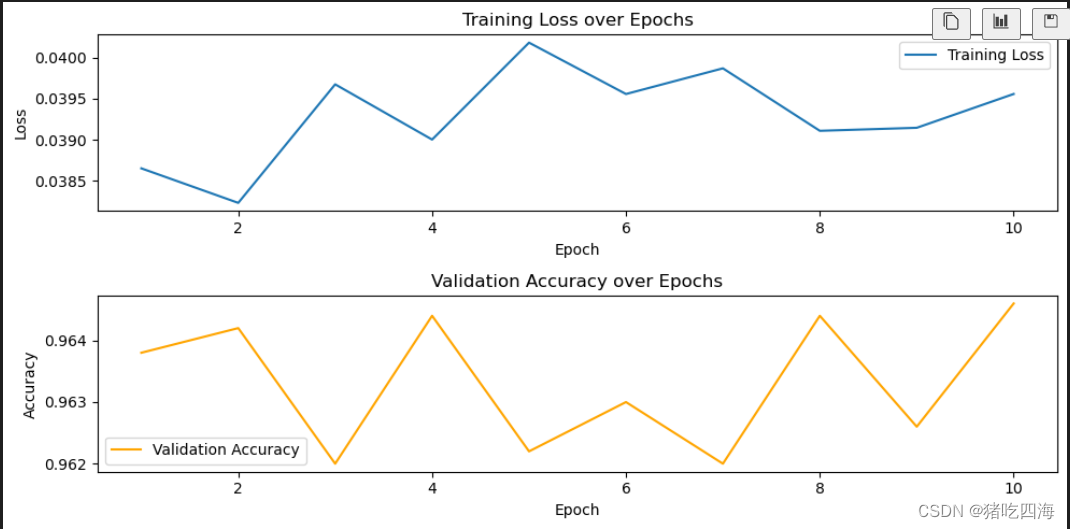 经过了漫长的等待,模型训练用了整整3小时(建议在跑模型的时候干点别的),训练的损失值在0.0385到0.04之间浮动,验证集的准确率在0.962到0.964之间浮动。
经过了漫长的等待,模型训练用了整整3小时(建议在跑模型的时候干点别的),训练的损失值在0.0385到0.04之间浮动,验证集的准确率在0.962到0.964之间浮动。
4模型预测
4.1计算推理时间和f1值
# 数据预处理
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])# 创建自定义Dataset(测试集)
class TestCatDogDataset(Dataset):def __init__(self, folder_path, transform=None):self.folder_path = folder_pathself.transform = transformself.class_to_label = {'cats': 0, 'dogs': 1}# 获取所有图像文件和对应的标签self.test_files = []self.labels = []for class_name in os.listdir(folder_path):class_path = os.path.join(folder_path, class_name)if os.path.isdir(class_path):for file in os.listdir(class_path):if file.endswith('.jpg'):self.test_files.append(os.path.join(class_path, file))self.labels.append(self.class_to_label[class_name])def __len__(self):return len(self.test_files)def __getitem__(self, index):img_path = self.test_files[index]label = self.labels[index]img = Image.open(img_path).convert('RGB')if self.transform:img = self.transform(img)return img, label# 创建测试集Dataset
test_dataset = TestCatDogDataset(test_folder_path, transform=transform)# 创建测试集数据加载器
test_loader = DataLoader(test_dataset, batch_size=32)# 定义模型(保持和训练时一致的模型结构)
model = models.resnet18(pretrained=False)
model.fc = nn.Linear(512, 2) # 修改最后一层,适应二分类任务# 加载训练好的模型参数
model.load_state_dict(torch.load('cat_dog_classifier.pth'))
model.eval()# 记录预测开始时间
start_time_predict = time.time()# 预测
predictions = []
true_labels = []with torch.no_grad():for inputs, labels in test_loader:outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)predictions.extend(predicted.cpu().numpy())true_labels.extend(labels.cpu().numpy())# 记录预测结束时间
end_time_predict = time.time()# 输出预测时间
predict_time = end_time_predict - start_time_predict
print(f'Prediction Time: {predict_time:.3f} seconds')# 计算 F1 值
if len(true_labels) > 0:f1 = f1_score(true_labels, predictions)print(f'F1 Score: {f1:.3f}')
else:print('Unable to calculate F1 Score. No true labels in the test set.')做类似训练集的数据处理,包括图片标准化,标签化等,由于test数据集与train数据集的结构一致,这里不再解释。计算模型在训练集的推理时间和f1值:

f1值虽然有0.98,但是推理时间高达19秒
4.2预测单张图片
# 随机选择一张图片
random_class = random.choice(['cats', 'dogs'])
random_file = random.choice(os.listdir(os.path.join(test_folder_path, random_class)))
random_img_path = os.path.join(test_folder_path, random_class, random_file)# 预处理图像
img = Image.open(random_img_path).convert('RGB')
img_tensor = transform(img).unsqueeze(0) # 添加 batch 维度# 预测
with torch.no_grad():output = model(img_tensor)_, predicted = torch.max(output.data, 1)# 显示图片
plt.imshow(img)
plt.title(f"Predicted Label: {'cat' if predicted.item() == 0 else 'dog'}")
plt.show()从test测试集中随机选取一张图片进行预测,预测结果直接用作图片标题输出

5使用oneAPI组件
oneAPI 是一个由英特尔领导的行业倡议,旨在简化和加速跨不同硬件架构的开发。oneAPI 旨在提供一个统一的编程模型,使开发人员能够轻松地在不同类型的处理器上编写高性能代码。
5.1使用Intel Extension for PyTorch进行优化
import intel_extension_for_pytorch as ipex
import torch
import torch.nn as nn
from torchvision import models# 定义模型
model = models.resnet18(pretrained=False)
model.fc = nn.Linear(512, 2) # 修改最后一层,适应二分类任务# 加载训练好的模型参数
model.load_state_dict(torch.load('cat_dog_classifier.pth'))
model.eval()# 使用 ipex.optimize 进行优化
optimized_model = ipex.optimize(model)# 保存模型时同时保存结构信息
torch.save({'model_state_dict': optimized_model.state_dict(), 'model_structure': optimized_model}, 'new_cat_dog_classifier.pth')重新加载训练好的模型(cat_dog_classifier.pth),使用Intel Extension for PyTorch进行优化,建议使用Intel® DevCloud云环境(没有账号的需要先注册),保存优化后的模型(new_cat_dog_classfier.pth)和模型结构
5.2加载并创建优化后的模型
checkpoint = torch.load('new_cat_dog_classifier.pth')
model_structure = checkpoint['model_structure']
model_state_dict = checkpoint['model_state_dict']# 创建模型
loaded_model = ipex.optimize(model_structure)
loaded_model.load_state_dict(model_state_dict)
loaded_model.eval()5.3使用Intel Extension for PyTorch优化后的模型预测
# 预测
predictions = []
true_labels = []# 记录预测开始时间
start_time_predict = time.time()with torch.no_grad():for inputs, labels in test_loader:outputs = loaded_model(inputs)_, predicted = torch.max(outputs.data, 1)predictions.extend(predicted.cpu().numpy())true_labels.extend(labels.cpu().numpy())# 记录预测结束时间
end_time_predict = time.time()# 输出预测时间
predict_time = end_time_predict - start_time_predict
print(f'Prediction Time: {predict_time:.3f} seconds')# 计算 F1 值
if len(true_labels) > 0:f1 = f1_score(true_labels, predictions)print(f'F1 Score: {f1:.3f}')
else:print('Unable to calculate F1 Score. No true labels in the test set.')运行结果

优化结果在预测时间上尤为明显,从没优化前的19秒缩减到现在的7.99秒, F1值也有进一步的提升,从0.98直接就到了1.00
5.4使用 Intel® Neural Compressor 量化模型
加载优化后的模型进行量化
import torch
import torch.nn as nn
from torchvision import models
from neural_compressor.config import PostTrainingQuantConfig, AccuracyCriterion
from neural_compressor import quantization
import os# 1. 定义模型
class CustomModel(nn.Module):def __init__(self, num_classes=2):super(CustomModel, self).__init__()# 使用 ResNet18 作为基础模型self.base_model = models.resnet18(pretrained=False)# 修改最后一层以适应二分类任务in_features = self.base_model.fc.in_featuresself.base_model.fc = nn.Linear(in_features, num_classes)def forward(self, x):return self.base_model(x)# 2. 加载优化模型
model = CustomModel(num_classes=2)# 3. 加载模型参数,确保匹配模型结构
checkpoint = torch.load('new_cat_dog_classifier.pth')
model_dict = model.state_dict()
for key in checkpoint['model_state_dict']:if key in model_dict and checkpoint['model_state_dict'][key].shape == model_dict[key].shape:model_dict[key] = checkpoint['model_state_dict'][key]
model.load_state_dict(model_dict)model.eval() # 设置模型为评估模式# 4. 配置量化参数
conf = PostTrainingQuantConfig(backend='ipex', accuracy_criterion=AccuracyCriterion(higher_is_better=True, criterion='relative', tolerable_loss=0.01))# 5. 执行量化
q_model = quantization.fit(model,conf,calib_dataloader=train_loader, # 替换为你的数据加载器eval_func=eval_func)# 6. 保存量化模型
quantized_model_path = './quantized_models'
if not os.path.exists(quantized_model_path):os.makedirs(quantized_model_path)q_model.save(quantized_model_path)
量化成功后,出现以下结果

5.5加载量化后的模型
import torch
import jsonfrom neural_compressor import quantization# 指定量化模型的路径
quantized_model_path = './quantized_models'# 加载 Qt 模型和 JSON 配置
resnet18_model_path = f'{quantized_model_path}/best_model.pt'
json_config_path = f'{quantized_model_path}/best_configure.json'# 加载 Qt 模型
resnet18_model = torch.jit.load(resnet18_model_path, map_location='cpu')# 加载 JSON 配置
with open(json_config_path, 'r') as json_file:json_config = json.load(json_file)
5.6使用量化后的模型进行预测
resnet18_model.eval()# 预测
predictions = []
true_labels = []# 记录预测开始时间
start_time_predict = time.time()with torch.no_grad():for inputs, labels in test_loader:outputs = loaded_model(inputs)_, predicted = torch.max(outputs.data, 1)predictions.extend(predicted.cpu().numpy())true_labels.extend(labels.cpu().numpy())# 记录预测结束时间
end_time_predict = time.time()# 输出预测时间
predict_time = end_time_predict - start_time_predict
print(f'Prediction Time: {predict_time:.3f} seconds')# 计算 F1 值
if len(true_labels) > 0:f1 = f1_score(true_labels, predictions)print(f'F1 Score: {f1:.3f}')
else:print('Unable to calculate F1 Score. No true labels in the test set.')运行结果

预测时间再次缩减,从7.99秒缩减到5.03秒,与此同时,F1分数稳定不变,仍然是1.00.
6总结
在本次事例中,足以证明OneApi强大的优化能力和模型压缩能力。未优化前的预测时间是19秒,F1值是0.98,经过优化后,在将F1提升到1.00的情况下把预测时间缩减到7.99秒,经过量化后,不仅F1值保持1.00不变,训练时间还进一步缩减到5.03秒,说明 oneAPI 在模型精度和性能之间找到了一个良好的平衡点。
这篇关于【Intel校企合作课程】基于ResNet18实现猫狗大战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




