本文主要是介绍TOFEC:使用纠删码实现云存储的最佳吞吐量延迟权衡,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

第一部分:论文中的名词解释
- TOFEC(Throughput Optimal FEC Cloud) 吞吐量最优的FEC云,FEC是指前向纠删码
- 并行连接:指同时使用多个网络来传输数据的一种技术,这样可以提高数据传输的速率和效率,特别是在云存储中。
- 有限分块是指将一个大的数据对象分成若干个较小的段,每个段都有自己的标识符和哈希值。这样可以提高数据去重的能力,减少存储空间的占用,以及降低传输延迟。
第二部分:TOFEC算法策略介绍
这篇文章提出了一种使用纠删码(erasure code)来提高云存储系统的吞吐量-延迟性能的自适应策略,称为TOFEC。
TOFEC利用纠删码的特性,可以动态地调整文件分块和冗余的级别,根据请求队列的长度作为工作负载的指标。在轻负载时,TOFEC使用更小的分块和更多的并行连接来减少服务延迟;在重负载时,TOFEC减少分块和冗余的级别,以降低开销,提高吞吐量,并防止排队延迟。文章通过基于Amazon S3的实测数据和仿真实验,证明了TOFEC能够有效地适应不同的工作负载,实现最优的吞吐量-延迟折衷。
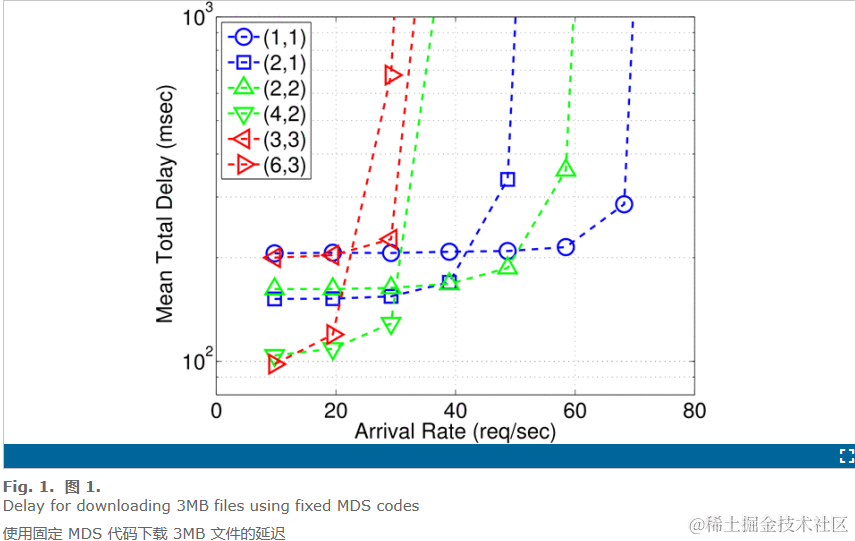
第三部分:论文大致介绍
本文的引言部分首先介绍了云存储系统作为一种经济、灵活和可靠的数据存储服务,在当今许多云端应用中的广泛应用。然后指出了云存储系统在延迟性能方面存在的高度随机性和不可预测性,以及这对于需要更强和更稳定的服务质量保证(QoS)的应用带来的挑战。接着回顾了相关工作中使用纠删码或冗余请求等方法来改善云存储系统延迟性能的优缺点,并指出了现有方法中存在的问题:如何在不降低系统容量的情况下,在不同工作负载下实现最优的吞吐量-延迟折衷。最后概述了本文提出的TOFEC策略及其主要贡献和创新点。
第四部分:本文的研究结果
- 通过对Amazon S3进行大规模测量,发现了两种支持不同分块大小的纠删码访问方法(Unique Key和Shared Key)在延迟性能上没有显著差异,但Shared Key具有更高的存储效率。
- 建立了一个基于纠删码访问云存储系统的排队模型,并通过拟合实测数据得到了任务延迟分布的参数估计。
- 通过对排队模型进行非凸优化分析,得到了一个闭合形式的解析解,表明最优的纠删码参数只取决于请求队列长度,并且随着队列长度增加而单调递减。
- 基于上述解析解,设计了一个基于请求队列长度驱动的自适应策略TOFEC,并通过仿真实验验证了其在不同工作负载下相对于静态策略和简单启发式策略(Greedy)具有更好或相当的延迟性能。
第五部分:本文的讨论部分
- 与已有的使用纠删码或冗余请求的方法进行比较,说明TOFEC的优势在于能够动态地调整分块和冗余的级别,而不是固定地使用一个预先确定的纠删码参数,从而实现更好的吞吐量-延迟折衷。
- 与已有的使用动态任务大小(job sizing)的方法进行比较,说明TOFEC的优势在于能够同时利用纠删码和并行连接的特性,而不是仅仅依赖于任务大小的调整,从而实现更高的可靠性和灵活性。
- 分析了TOFEC策略的一些局限性和不足,例如对于非均匀分布的任务延迟,TOFEC可能无法达到最优性;对于不同类型和大小的请求,TOFEC可能需要更细粒度的分块和冗余参数;对于不支持部分读写APIs的云存储系统,TOFEC可能无法使用Shared Key方法等。
- 提出了一些未来的研究方向和改进措施,例如考虑更复杂的纠删码结构和编解码算法;考虑更多的影响因素,如网络带宽、存储成本、数据一致性等;考虑更多的应用场景,如视频流、实时通信等。
第六部分:本文的方法部分
- 使用纠删码来提高云存储系统的延迟性能。纠删码是一种前向纠错编码(FEC)技术,可以将一个文件分成k个数据块,并编码成n个编码块,使得任意k个编码块就可以恢复原始文件。这样可以提高数据的可靠性和容错性,同时也可以利用并行连接来加速文件的上传和下载。
- 使用排队模型来分析云存储系统的吞吐量-延迟折衷。排队模型是一种数学工具,可以用来描述系统中请求和任务之间的动态关系。本文使用了一个双队列模型,其中一个队列用来缓存用户请求,另一个队列用来执行任务。每个请求会产生n个任务,并且只要有k个任务完成,就认为请求被服务。本文使用了M/M/1模型来近似请求队列,并根据实测数据拟合了任务延迟分布。
- 使用非凸优化方法来求解最优的纠删码参数。非凸优化方法是一种求解非线性问题的数学技术,可以用来寻找目标函数在可行域内的最小值或最大值。本文将云存储系统中总延迟作为目标函数,并将纠删码参数作为决策变量。通过一些数学推导和变换,本文得到了一个闭合形式的解析解,表明最优的纠删码参数只取决于请求队列长度,并且随着队列长度增加而单调递减。
第七部分:本文涉及的数据
本文设计的数据是云存储系统中用户请求和任务延迟的实测数据。其分析方法和筛选标准如下:
- 分析方法:本文使用了基于Amazon EC2和S3的大规模测量实验,以及基于实测数据驱动的仿真实验。测量实验在不同时间、日期和区域对S3进行了多次测试,收集了不同分块大小和冗余级别下任务延迟数据。仿真实验使用了不同的纠删码参数和到达率,模拟了不同的工作负载和服务质量。
- 筛选标准:本文对测量数据进行了一些预处理和筛选,以提高分析的准确性和有效性。具体来说,本文采用了以下几个步骤:
-
- 去除了一些异常值,如超过10秒的任务延迟,因为它们可能是由于网络故障或其他非常规因素造成的。
- 对任务延迟进行了对数变换,以减小数据的偏度和方差,并使其更接近正态分布。
- 对任务延迟进行了线性拟合,以估计其均值和标准差随着分块大小的变化关系,并用这些参数来构建任务延迟模型。
- 对不同区域和时间段的数据进行了分组和比较,以评估云存储系统的稳定性和一致性,并排除了一些表现不佳或不典型的区域。
🤩创新点:
- TOFEC新颖之处:基于积压的自适应算法,用于动态调整块大小以及为满足存储访问请求而发出的冗余请求数量。
- MDS纠删码,n=k+m 完成任何k编码块意味着已将足够的数据存储在云中,完成请求后,n-k未开始或已完成的任务被抢先取消并从系统中删除。
导师发的论文,做的学习笔记🤡争取早日发论文🥳
论文原地址:https://ieeexplore.ieee.org/document/6848010?denied=
这篇关于TOFEC:使用纠删码实现云存储的最佳吞吐量延迟权衡的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




