本文主要是介绍目标检测——PP-PicoDet算法解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PP-YOLO系列,均是基于百度自研PaddlePaddle深度学习框架发布的算法,2020年基于YOLOv3改进发布PP-YOLO,2021年发布PP-YOLOv2和移动端检测算法PP-PicoDet,2022年发布PP-YOLOE和PP-YOLOE-R。由于均是一个系列,所以放一起解读,方便对比前后改进地方。
PP-YOLO系列算法解读:
- PP-YOLO算法解读
- PP-YOLOv2算法解读
- PP-PicoDet算法解读
- PP-YOLOE算法解读
- PP-YOLOE-R算法解读
YOLO系列算法解读:
- YOLOv1通俗易懂版解读
- SSD算法解读
- YOLOv2算法解读
- YOLOv3算法解读
- YOLOv4算法解读
- YOLOv5算法解读
文章目录
- 1、算法概述
- 2、PP-PicoDet细节
- 2.1 Better Backbone
- 2.2 CSPPAN and Detector Head
- 2.3 Label Assignment Strategy and Loss
- 2.4 Other Strategies
- 3、实验
- 3.1 消融实验
- 3.2 与其他检测算法对比
PP-PicoDet(2021.11.1)
论文:PP-PicoDet: A Better Real-Time Object Detector on Mobile Devices
作者:Guanghua Yu, Qinyao Chang, Wenyu Lv, Chang Xu, Cheng Cui, Wei Ji, Qingqing Dang, Kaipeng Deng, Guanzhong Wang, Yuning Du, Baohua Lai, Qiwen Liu, Xiaoguang Hu, Dianhai Yu, Yanjun Ma
链接:https://arxiv.org/abs/2111.00902
代码:https://github.com/PaddlePaddle/PaddleDetection
1、算法概述
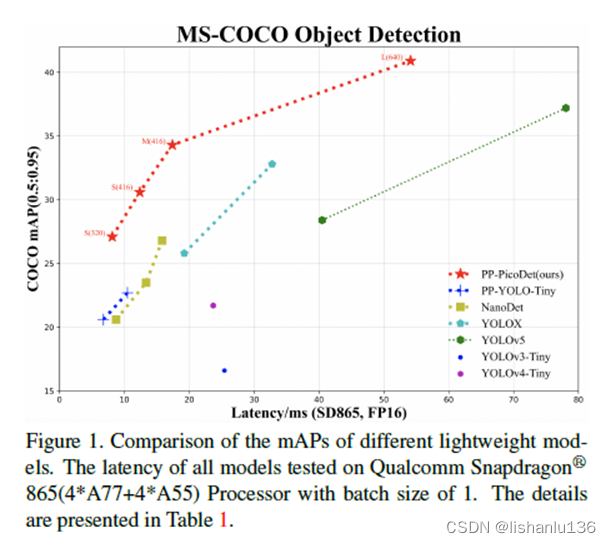
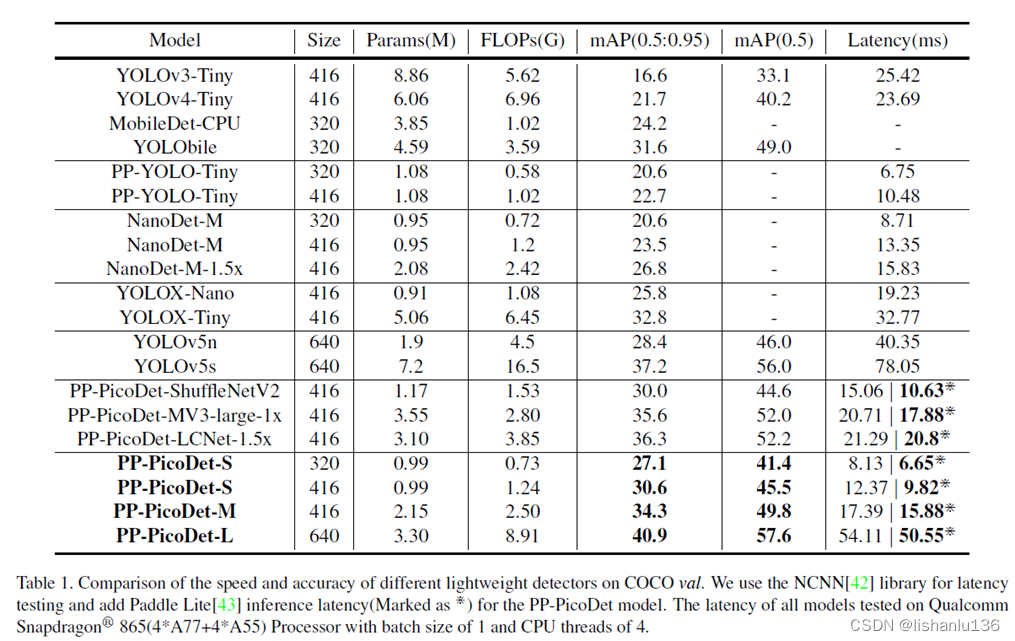
从论文标题可以看出来,该算法主要是针对移动端设备提出来的,所以该算法特点是模型小推理速度快。本文中,作者致力于研究目标检测的关键优化和神经网络架构选择,以提高准确性和推理速度。作者研究了无锚框策略在轻量级目标检测模型中的适用性,并且增强了主干结构,设计了颈部轻量化结构,提高了网络的特征提取能力。改进了标签分配策略和损失函数,使训练更加稳定和高效。通过这些优化,作者建立了一个新的实时目标检测器系列,名为PP-PicoDet,它在移动设备的目标检测上实现了卓越的性能。与其他流行的模型相比,该模型在准确性和延迟之间实现了更好的权衡。只有0.99M个参数的PicoDet-S实现了30.6%的mAP,与YOLOX-Nano相比,mAP值提高了4.8%,同时将移动CPU推理延迟降低了55%;与NanoDet相比,mAP提高了7.1%。当输入大小为320时,它在移动ARM CPU上达到123 FPS(使用Paddle Lite时为150 FPS)。仅使用330万个参数的PicoDet-L实现了40.9%的mAP, mAP提高了3.7%,比YOLOv5s快44%。在COCO数据集上的表现为:
PP-PicoDet的贡献如下:
- 1、neck中改进PAN结构,采用CSP-PAN,用1x1卷积减少参数的情况下提升了特征提取能力,用5x5的深度可分离卷积(depthwise separable convolution)替换了3x3的可分离卷积,提升了感受野的大小。
- 2、采用SimOTA动态标签分配策略,对部分计算细节进行优化。具体来说,使用了变焦损失(VFL)的加权求和与GIoU loss来计算成本矩阵,在不损害效率的前提下提高了准确性。
- 3、提出了基于ShuffleNetV2改进的Enhanced ShuffleNet(ESNet),性能比原版ShuffleNetV2好。
- 4、提出一种改进的单次神经网络检测架构搜索(NAS)流水线,自动查找最优的架构进行目标检测。
2、PP-PicoDet细节
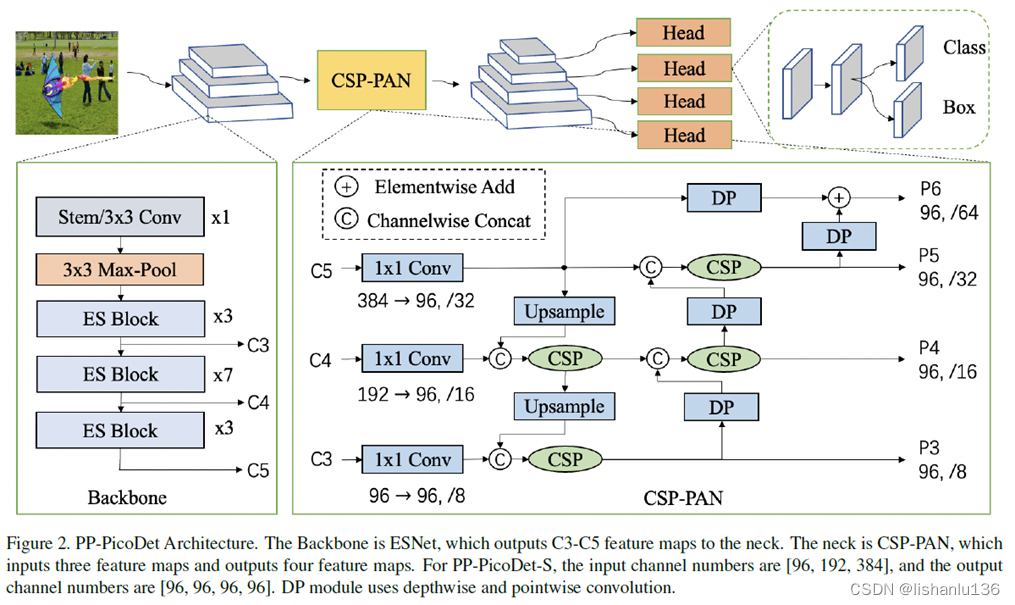
PP-PicoDet网络结构图如下所示:
Backbone:基于shuffleNetV2改进,ESNet,输出C3,C4,C5特征图进入neck;
Neck:CSP-PAN,接受C3,C4,C5输入,输出P3,P4,P5,P6;
2.1 Better Backbone
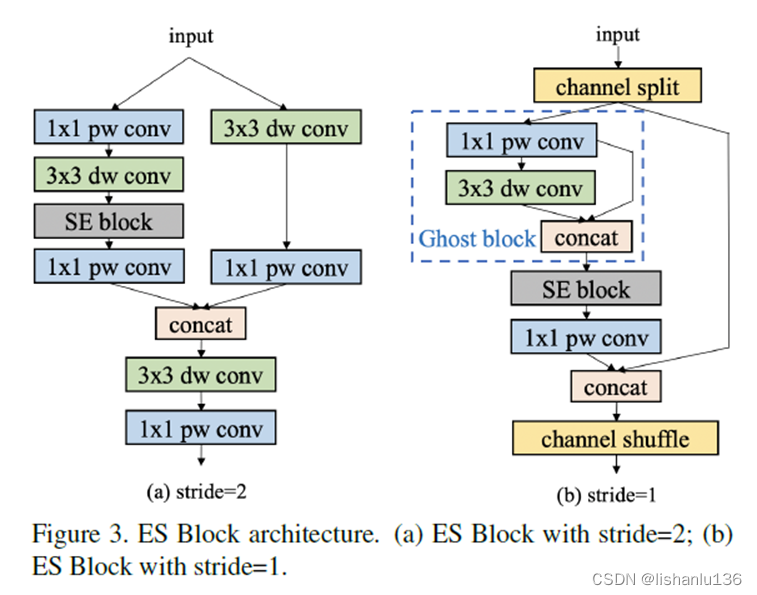
手工设计的backbone: 基于之前的经验,作者发现ShuffleNetV2在移动端设备上比其他网络更强大,为了进一步提高ShuffleNetV2的性能,作者遵循了PPLCNet的一些方法优化网络结构,构建新的骨干网络,即Enhanced ShuffleNet(ESNet)。ESNet主要由ES Block组成,其结构如下:
神经网络结构搜索: 作者首次提出了单次搜索目标探测器的方法。配备了用于分类的高性能主干的对象检测器可能不是最优的,因为分类和检测是两个不同的任务。所以作者不是搜索更好的分类器,而是直接在检测数据集上训练和搜索检测超级网络(the detection supernet),这可以节省大量的计算量并优化检测任务而不是优化分类任务。该框架包括两个步骤:(1)在检测数据集上训练单次超级网络;(2)在训练好的超级网络上使用进化算法(EA)进行架构搜索。为了方便起见,作者在这里简单地使用通道搜索主干网。具体来说,作者提供了灵活的比率选项来选择不同的通道比率。比如:[0.5, 0.675, 0.75, 0.875, 1]。
2.2 CSPPAN and Detector Head
本文使用PAN结构获得多层次特征图,使用CSP结构进行相邻特征图之间的特征拼接和融合。具体的使用用1x1卷积减少参数的情况下提升了特征提取能力,用5x5的深度可分离卷积提升感受野大小。具体参考上图CSP-PAN结构图。
在detector head部分,作者也使用5x5的深度可分离卷积提升感受野大小,不像YOLOX解耦了回归分支和分类分支,PP-PicoDet没有将两者解耦,获得的性能相同。
2.3 Label Assignment Strategy and Loss
作者采用了SimOTA动态分配标签策略(和YOLOX一样),SimOTA首先通过中心先验确定候选区域,然后计算预测框和候选区域中gt框的IoU,最后通过对每个gt框的n个最大IoU求和得到参数k。成本矩阵(The cost matrix)是通过直接计算所有预测框的损失与候选区域内的gt框得到的。原始的SimOTA是CEloss和IoUloss加权求和得到成本矩阵。为了使SimOTA中的代价与目标函数保持一致,作者使用Varifocal损失和GIoU损失的加权和作为成本矩阵。公式为:
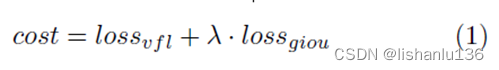
实验中λ设置为6
在检测头中,对于分类任务,作者利用Varifocal损失将分类预测和质量预测结合起来;对于回归任务,作者利用GIoU损失和Distribution Focal Loss,公式如下:
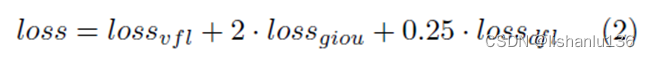
2.4 Other Strategies
激活函数: 作者将检测算法中的激活函数从ReLU替换为H-Swish,在保持推理时间不变的情况下,性能显著提高。
学习率下降策略: 采用Cosine learning rate decay,余弦学习率平稳下降,在batchsize比较大时,有利于训练过程。
数据增强: 过多的数据增强往往会增加正则化效果,使训练更难以收敛。所以在这项工作中,作者只使用随机翻转、随机裁剪和多尺度调整来进行训练中的数据增强。
3、实验
在COCO-2017 training集上训练,在COCO-2017 test-dev集上评估。
3.1 消融实验
关于改进措施的消融实验,如下表所示:
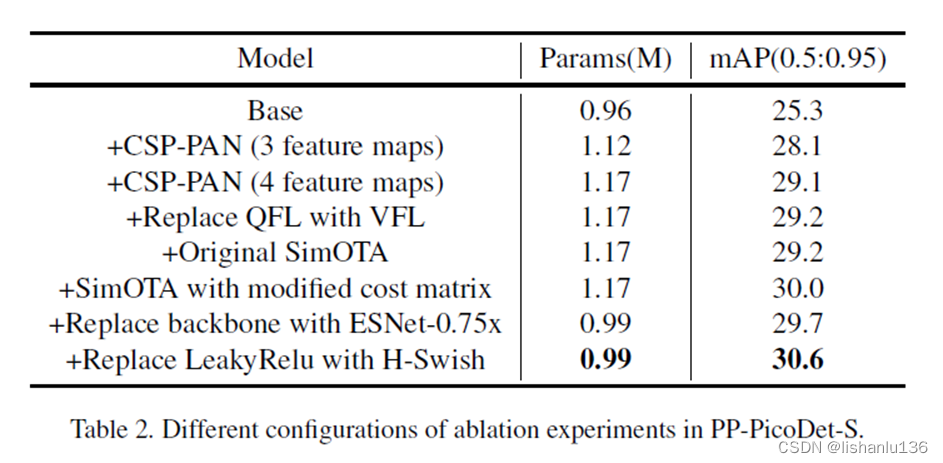
Base模型为与NanoDet相似的基础模型,主干采用ShuffleNetV2-1x,颈部采用无卷积的PAN,Loss采用标准GFL损失,标签分配策略采用ATSS。所有激活函数都使用LeakyRelu。得到的mAP(0.5:0.95)为25.3%。可以看到PAN经过改进变成CSP-PAN后,性能提升很大。
3.2 与其他检测算法对比
与其他先进检测算法对比,作者使用NCNN库进行延迟测试,并为PP-PicoDet模型添加了Paddle Lite推理延迟,实验结果如下所示:
这篇关于目标检测——PP-PicoDet算法解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





