本文主要是介绍【论文】OSS-Instruct——EvalPlus榜单SOTA模型Magicoder,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
arxiv论文地址
EvalPlus Leaderboard
GitHub - ise-uiuc/magicoder: Magicoder: Source Code Is All You Need
目录
编辑
背景
OSS-Instruct
具体例子
数据处理
实验
python代码生成
小语种生成
deepseek做base
语言分布的消融实验
直接用开源代码进行fine-tune
背景
现有的数据生成办法可以有效地提高LLM的指令跟踪能力,但它们依赖于小范围的预定义任务或启发式方法。而这样的方法会显著地继承LLMs和预定义任务中固有的系统偏差。
Self-Instruct仅依靠21个种子任务,使用相同的提示模板生成新的代码指令。
Evol-Instruct 以Code Alpaca为种子,仅依靠5种启发式算法对数据集进行演化。
OSS-Instruct

如图所示,OSS - INSTRUCT利用强大的LLM,通过从开源中收集的任意随机码片段中获得灵感,自动生成新的编码问题。【直接用开源代码进行fine-tune会对模型性能产生负面影响】在这个例子中,LLM从来自不同功能的两个不完整的代码片段中得到启发,并设法将它们联系起来,形成一个现实的机器学习问题。得益于"无限"的开源代码,OSS - INSTRUCT可以通过提供不同的种子代码片段直接产生多样化、逼真和可控的代码指令。
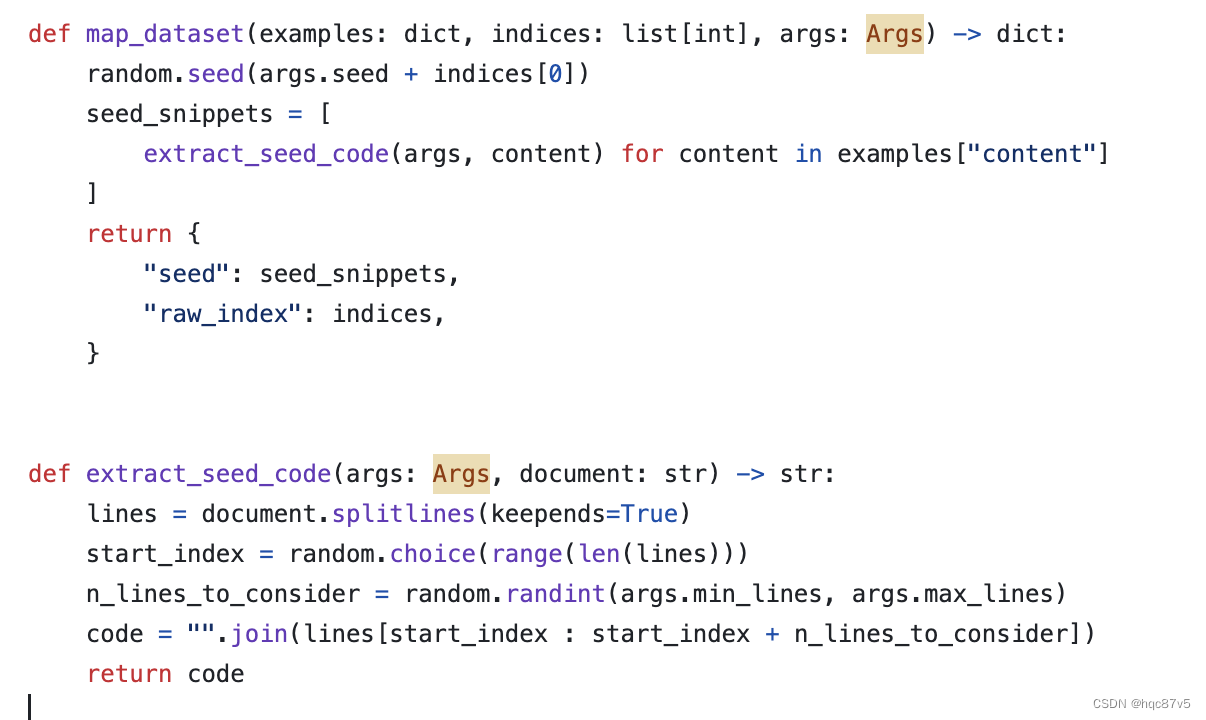
根据从GitHub中收集到的一些种子代码段,提示一个LLM (例如, ChatGPT)产生一个编码问题及其解决方案。种子片段提供了生成的可控性,并鼓励LLM创建能够反映真实世界编程场景的多样化编码问题。
源码中提取种子片段的代码
具体例子




shell脚本示例展示了LLM如何仅用一行shell脚本处理Python编码问题。库导入实例演示了一个LLM如何只用几个导入语句就可以创建一个现实的机器学习问题。同时,类签名实例说明了LLM从一个包含SpringBootApplication等注释和bank等关键字的不完整类定义中汲取灵感的能力。由此,LLM产生了一个问题,即需要基于Spring Boot实现一个完整的银行系统!
数据处理
选择StarCoder的语料库生成种子代码片段,因为是过滤版本,已经进行后处理,是高质量的
对于每一个code 文档,随机提取1~15个连续的行,从80K篇文档中提取80K的初始种子判断,python40K,C++, Java, TypeScript, Shell, C#, Rust, PHP, and Swift 各5K。为防止数据泄露,和评测数据集进行去重,最后剩75K种子数据
手工设计了10个coding的类别,计算每个样本在OSS-Instruct 的嵌入和10个类别之间的cosine相似度
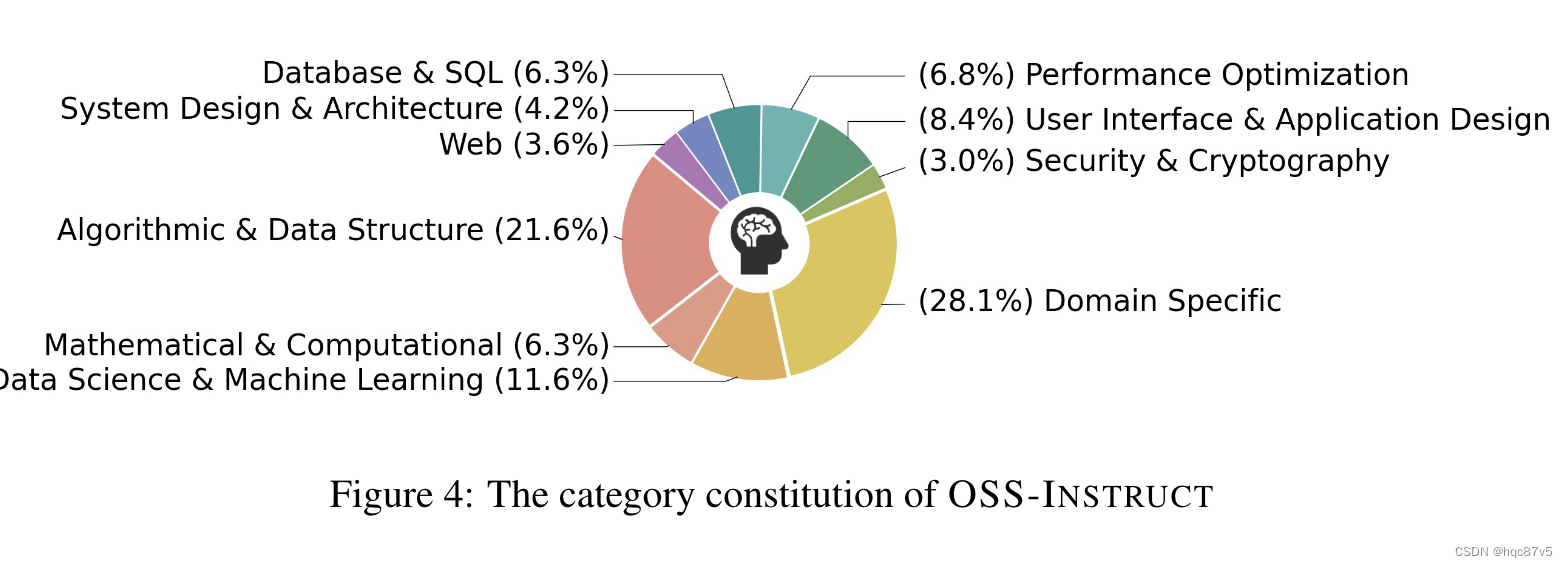
创建多样化的编码任务,包括算法挑战、现实问题、单功能代码生成、基于库的程序补全、全程式开发,甚至整个应用程序的构建。
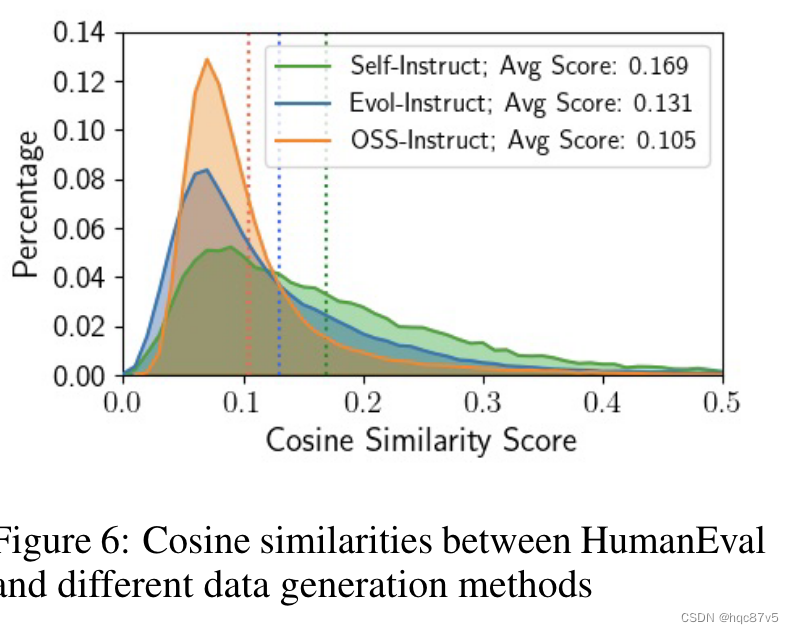
再计算OSS-Instruct 75K数据集以及self-instruct方法以及Evol-instruct与HumanEval 之间的相似性,self最高
实验
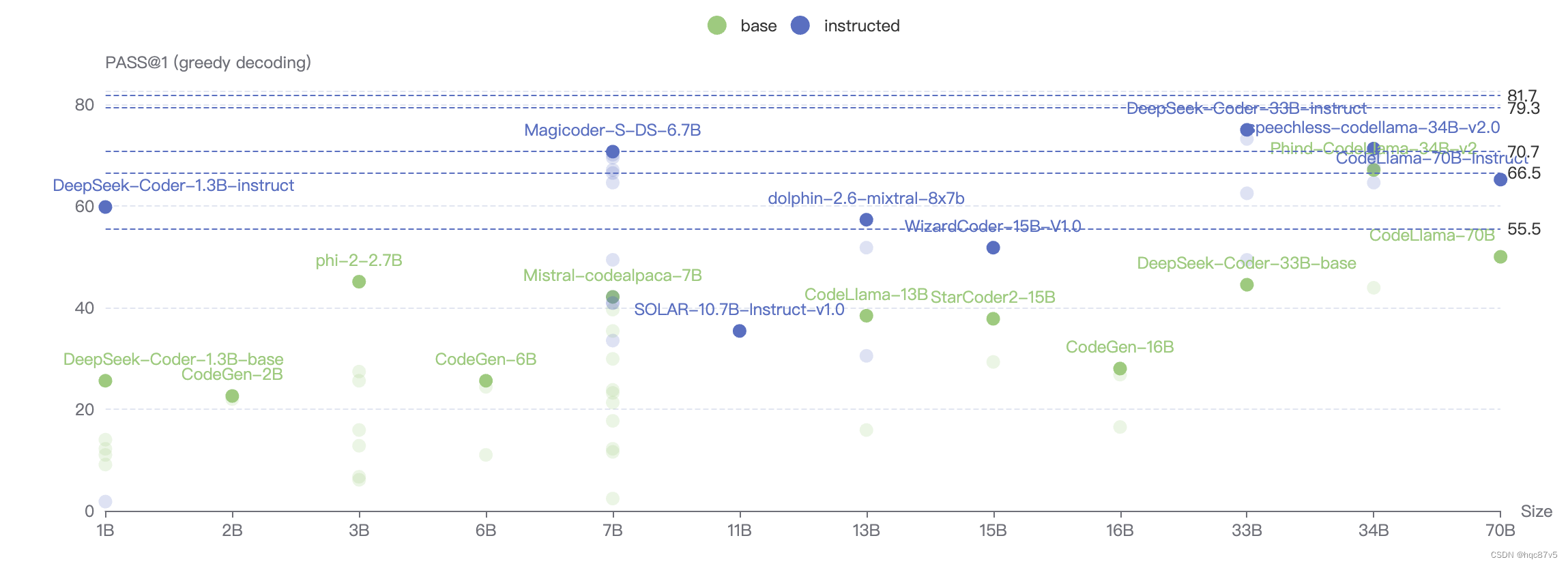
python代码生成
分别在CodeLLaMa-python-7B基础上用75K的OSS instruct数据集fine-tune得到Magicoder-CL和Magicoder-DS;继续evol-instruct方法训练得到MagicoderS-CL和MagicoderS-DS
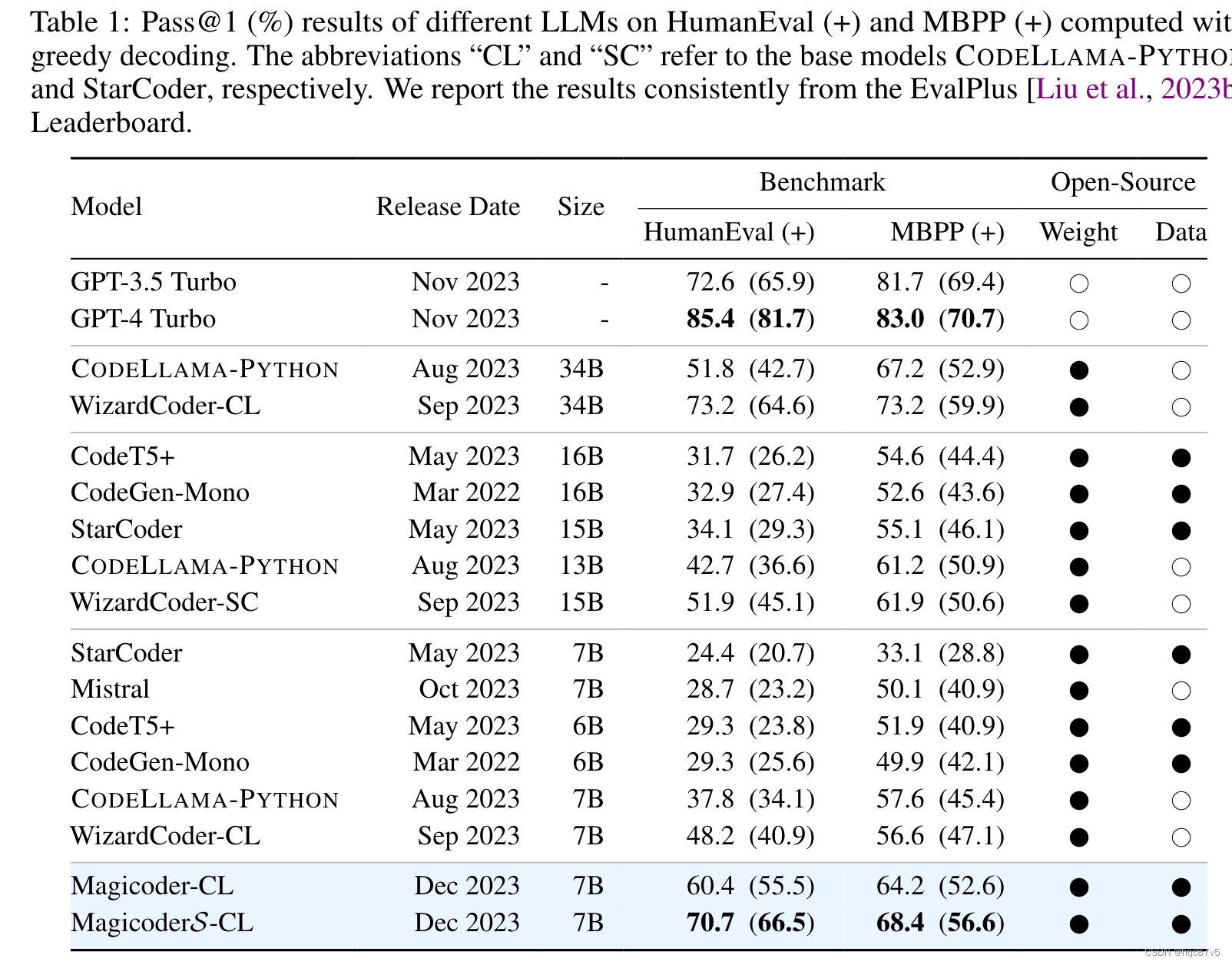
虽然MagicoderS - CL在HumanEval上的得分略低于WizardCoder - CL - 34B和ChatGPT,但在更严格的HumanEval +数据集上,MagicoderS - CL的得分超过了WizardCoder - CL - 34B和ChatGPT,表明MagicoderS - CL可能产生更健壮的代码。
小语种生成
用MultiPL-E进行测评
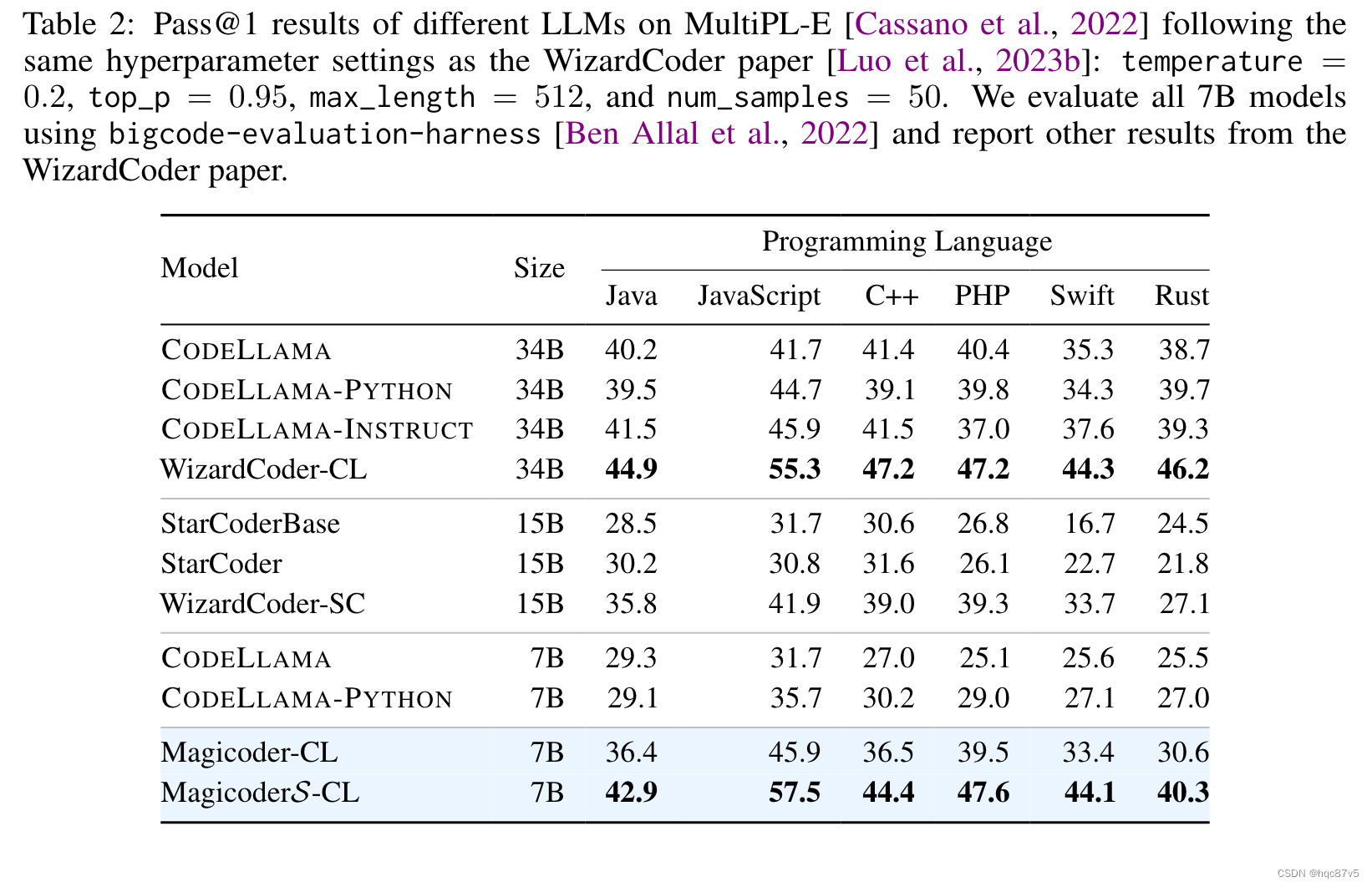
在所研究的编程语言中,Magicoder - CL对CODELLAMA - PYTHON - 7B的改进幅度较大。此外,在一半的编程语言中,Magicoder - CL也取得了比SOTA 15B WizardCoder - SC更好的结果。此外,MagicoderS - CL在所有编程语言上都比Magicoder - CL有了进一步的改进,在仅有7B个参数的情况下达到了与WizardCoder - CL - 34B相当的性能。
而且MultiPL-E以代码补全格式评估模型,但 Magicoders 仍显示出显著的改进,尽管仅进行了指令调整。这意味着LLM可以从超出其格式的数据中学习知识。
deepseek做base
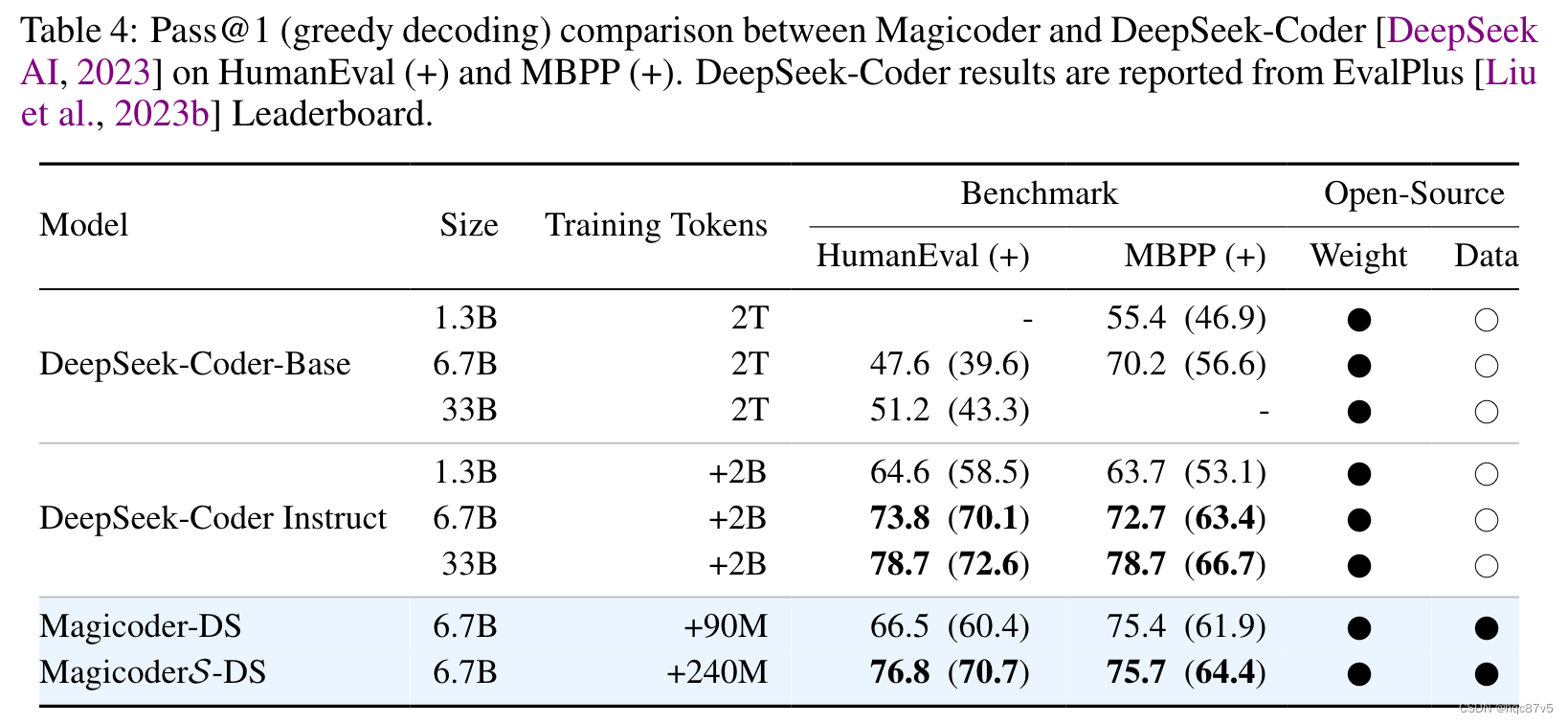
我们在 DeepSeek-Coder-Base-6.7B 用75K的OSS instruct数据集fine-tune得到 Magicoder-DS ;继续evol-instruct方法训练得到 MagicoderS-DS。值得注意的是,MagicoderSDS 变体在所有基准测试中都超越了 DeepSeek-Coder-Instruct-6.7B,训练token数量减少了 8 倍,并且在这些数据集上也与 DeepSeek-Coder-Instruct-34B 非常接近!
语言分布的消融实验
语种不是按种子的语言分类,而是按照生成出来的代码语言分;因为OSS-Instruct有可能生成和种子不同语言的代码。75K里面有43K的python数据和32K的其他语种数据
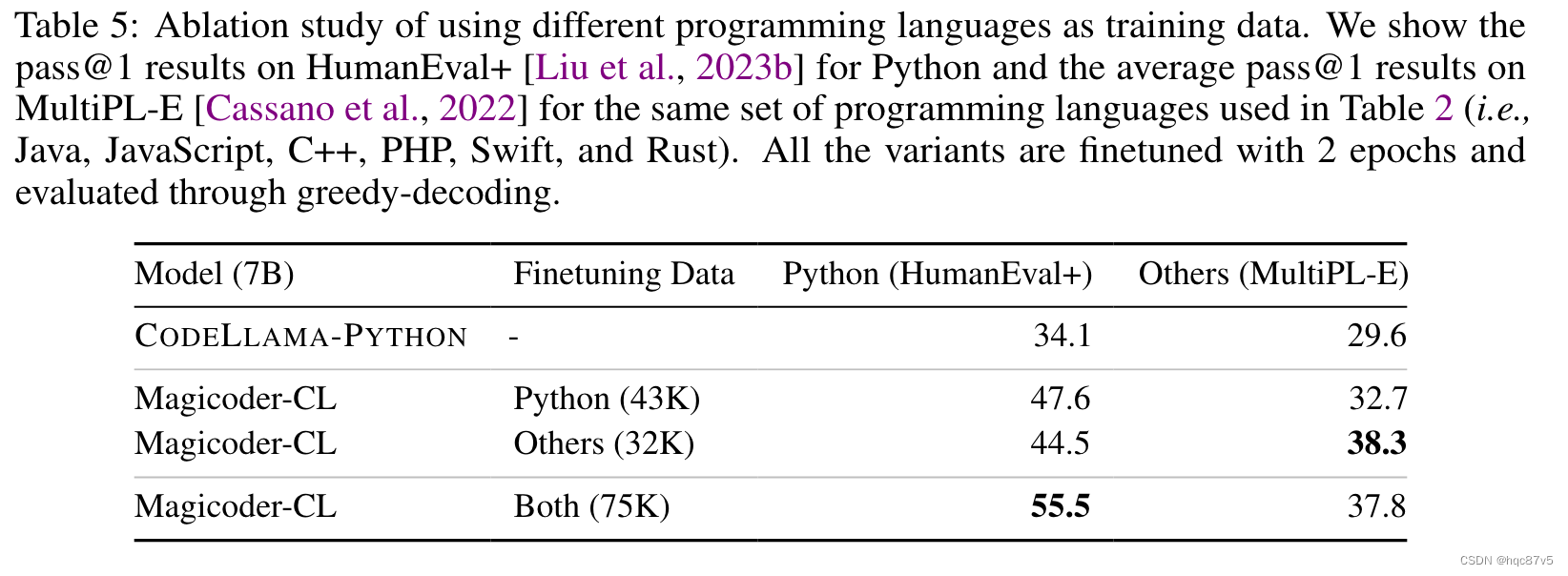
当仅使用 非 Python 数据进行训练时,Magicoder-CL 在仅使用 Python 的评估中仍然比基本模型提高了 10.4 个百分点。这意味着法学硕士可以在不同编程语言之间建立关联,并对更深层次的代码语义进行迁移学习。最后,混合语言的在python的评估上更高,但是在其他语言的表现上下降了,我们归因于指令调优期间 Python 数据的主导量(约 57%)。
直接用开源代码进行fine-tune
用产生OSS-instruct75K数据集来源的StarCode,提取comment-function对,让模型用function signatures和comments来预测函数体。
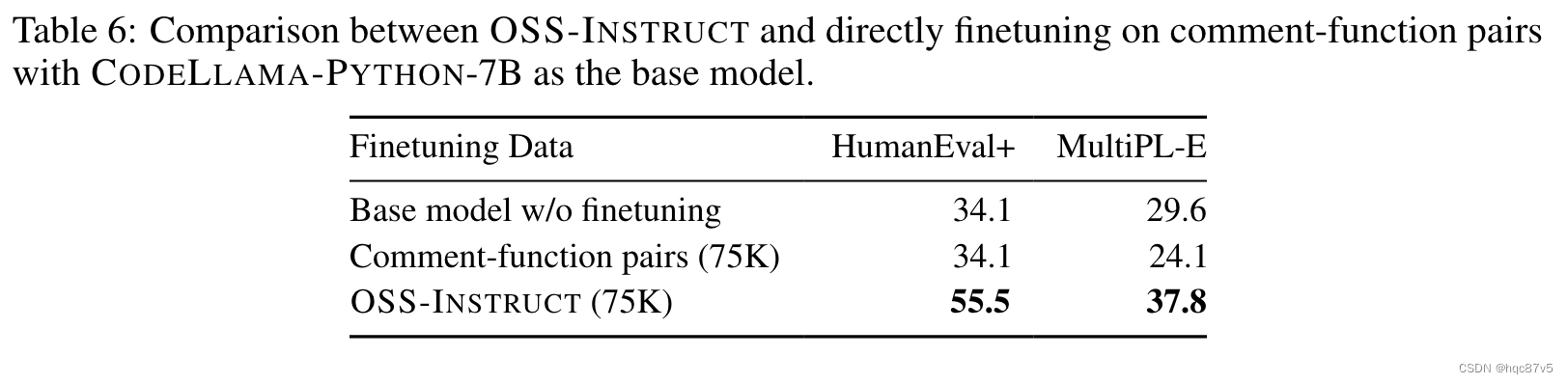
我们观察到对 75K coment-function 数据的微调甚至使基本模型变得更糟,而 OSS-INSTRUCT 有助于引入显著的提升。我们推测,退化是由于数据对本身存在的大量噪声和不一致造成的,尽管这些配对数据表现出与 HumanEval 或 MultiPL-E 问题非常相似的格式。这进一步表明,数据的真实性,而不是格式,对于代码指令调整至关重要。
这也表明了OSS-INSTRUCT可以将这些松散相关的代码片段转换为语义一致的指令调优数据。
这篇关于【论文】OSS-Instruct——EvalPlus榜单SOTA模型Magicoder的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







