本文主要是介绍OCP NVME SSD规范解读-13.Self-test自检要求,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

4.10节Device Self-test Requirements详细描述了数据中心NVMe SSD自检的要求,这一部分规范了设备自身进行各种健康检查和故障检测的过程。自检对于确保SSD的正常运行和提前预防潜在故障至关重要。
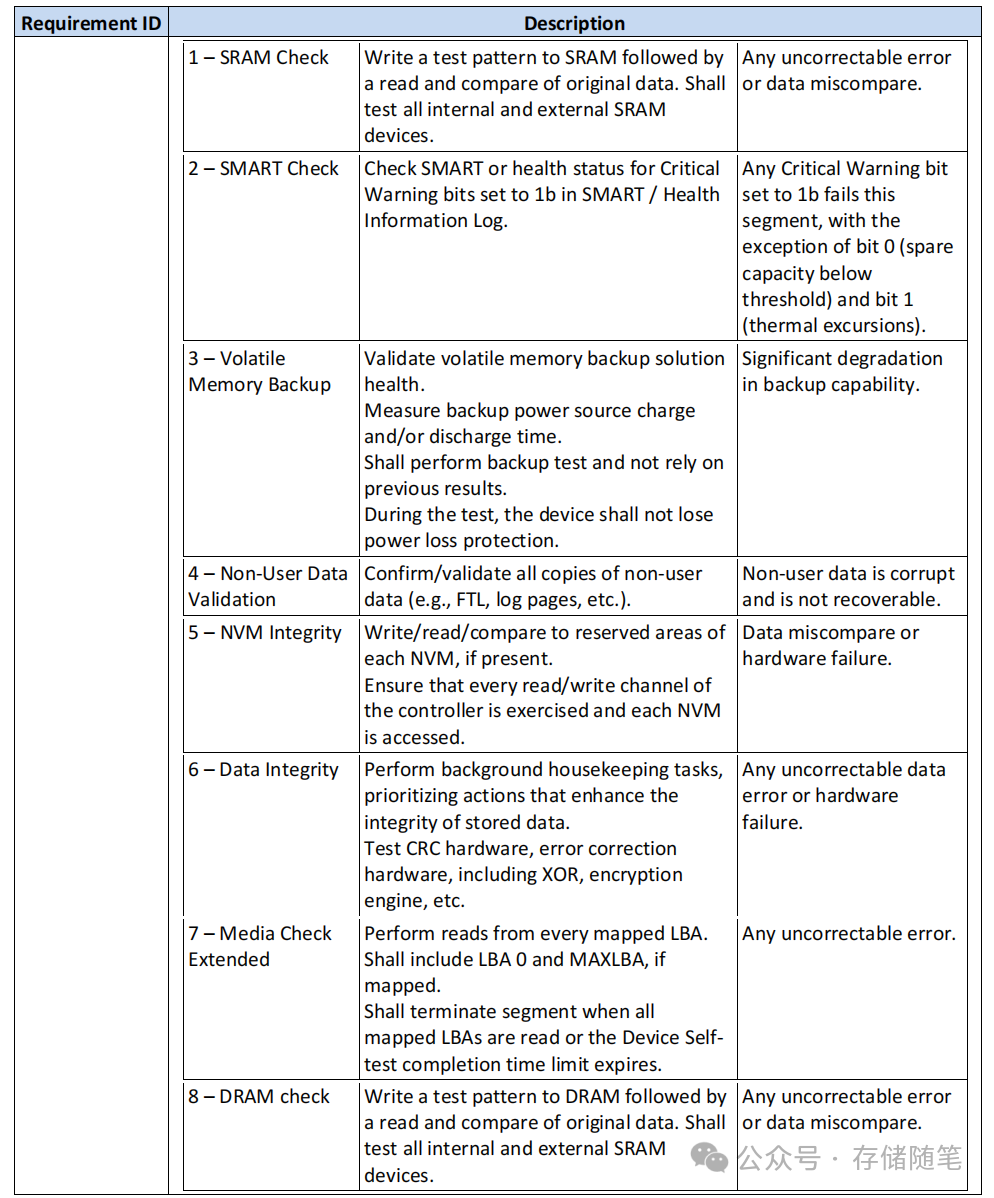
在进行设备自检时,设备应当确保不对用户数据造成破坏,即除了读取用户数据外,自检过程不会导致数据丢失或损坏。例如,即使在进行读取操作时产生轻微的读取干扰,只要这种影响极小,就不被视为破坏性行为。
此外,针对设备自检(Device Self-test)的重新执行情况,规范做出了特别说明。例如,在连续两次执行自我测试时,如果第二次测试发生在第一次成功完成后不久,则第二次的Media Check Extended应当检查不同的逻辑块地址(LBAs),并在必要时进行循环扫描,以覆盖尽可能多的存储区域,避免每次测试重复同一部分而导致某些潜在问题遗漏。
具体来说,如果一个设备拥有10000h分配的LBAs(即总共有10000个逻辑块地址),但在指定的设备自检完成时间内只能扫描到其中的6000h(即6000个逻辑块地址),那么设备自检的执行将采取分批扫描的方式。
-
首次设备自我测试运行时,将扫描从LBAs 0h到5FFFh的部分;
-
紧接着下一次运行时,将接着扫描从LBAs 6000h到BFFFh的部分;
-
随后的下一轮测试将开始于C000h的LBAs,并在达到地址上限后,循环回到0h继续扫描直到1FFFh,然后依次类推。
这样做的目的在于,即使在有限的测试时间内无法一次性扫描完全部的LBAs,也能确保每次执行都能检查到新的、尚未被上次测试覆盖到的存储区域,从而逐步全面地检测存储设备的健康状况。通过这种循环交错的扫描方式,设备自我测试能够实现对存储介质的有效分段式检查,有利于早期发现潜在故障,确保数据的安全性和存储系统的稳定性。
对于SMART/Health Information的检查,规定在自检中,如遇到温度阈值超标的情况,不应导致测试失败,因为这通常是风扇或系统故障引起的,而非SSD本身的问题。在自检操作中,将忽略SMART/Health Information日志页面中Critical Warning bit 1(温度警告位)的影响。
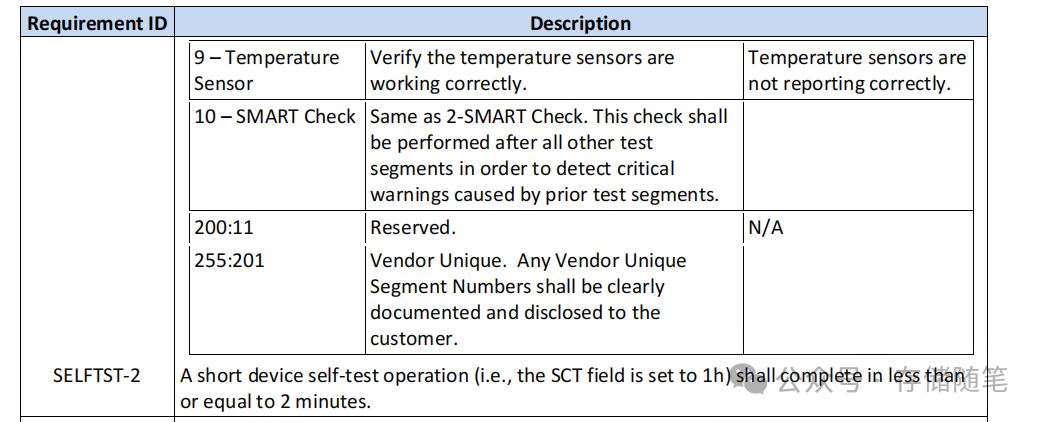
在进行扩展设备自检时,设备制造商需要提供一个最小的逻辑块地址(LBA)数量要求,以便主机写入足够的数据,以促使设备自检操作能读取到所有物理非易失性存储单元(如NAND闪存芯片)。
最后,针对特定的设备自自检代码(Device Self-test Code, STC),规范规定了设备在给定时间内至少要完成哪些测试段。例如,对于STC为1h或Eh的设备自检操作,至少需要包括segments 1到3和8的测试,并尽可能在指定完成时间内完成segments 4到7的测试。

当设备正在进行自检的过程中,如果由于同时存在的主机IO活动等原因导致未能在指定的完成时间内完成整个自检操作,设备不应因此报错或终止测试。相反,设备应尽可能在分配的完成时间内完成尽可能多的自检部分(device self-test segments)。
这意味着在并发I/O活动或其他资源竞争条件下,即使无法在预定的时间内彻底完成所有的测试内容,SSD也要尽力去执行尽可能多的测试环节,而不是立即放弃测试。这样的设计确保了在实际运行环境中的自检能够具有更强的鲁棒性和实用性。
-
鲁棒性指的是一个系统在面对内部错误、外部干扰、边界条件、异常输入或不利环境条件时,仍然能够保持稳定运行并维持预期功能的能力。在数据中心NVMe SSD的语境下,鲁棒性表现为即便在复杂的、高负载的服务器环境中(如存在大量并发的I/O活动),设备的自检功能也能够在各种不利条件下坚持执行,并不会因为未能在规定的完成时间内完成全部测试就失效或崩溃。这种设计确保了SSD在实际运用中能够应对不可预测的挑战,保持稳定性和可靠性。
-
实用性则反映了设备或系统在现实场景中能够有效解决问题和满足用户需求的程度。对于数据中心NVMe SSD的自检功能来说,实用性强意味着即使在理想测试条件不具备的情况下(如受到并发I/O活动影响),设备仍能够部分执行自我测试,尽可能多地获取到有价值的信息。这样一来,即便在繁忙的生产环境中,系统管理员也可以通过执行自我测试得到关于SSD健康状况的部分反馈,从而做出及时的决策和维护措施。
结合这两点来看,数据中心NVMe SSD的自检功能设计既要确保在复杂、动态的IT环境中保持稳健运行,不受临时条件约束,又要能够提供实际可用的、有助于系统运维的测试结果。
小编每日撰文不易,如果您看完有所受益,欢迎点击文章底部左下角“关注”并点击“分享”、“在看”,非常感谢!
精彩推荐:
-
如何突破SSD容量提升的瓶颈?
-
固态存储是未来|浅析SSD架构的演进与创新技术
-
论文解读:NAND闪存中读电压和LDPC纠错码的高效设计
-
华为新发布磁电存储“王炸”,到底是什么?
-
关于SSD LDPC纠错能力的基础探究
-
存储系统如何规避数据静默错误?
-
PCIe P2P DMA全景解读
-
深度解读NVMe计算存储协议
-
对于超低延迟SSD,IO调度器已经过时了吗?
-
浅析CXL P2P DMA加速数据传输的原理
-
HDD回暖于2024,与SSD决战于2028
-
SSD固态硬盘的黄金原则:抱最高的希望,做最坏的打算
-
PCIe 6.0生态业内进展分析总结
-
详细解读QLC SSD无效编程问题
-
NVMe SSD IO压力导致宕机案例解读
-
浅析PCIe 6.0功能更新与实现的挑战
-
过度加大SSD内部并发何尝不是一种伤害
-
FIO测试参数与linux内核IO栈的关联分析
-
PCIe surprise down异常与DPC功能分析
-
过度加大SSD内部并发何尝不是一种伤害
-
NVMe over CXL技术如何加速Host与SSD数据传输?
-
为什么QLC NAND才是ZNS SSD最大的赢家?
-
SSD在AI发展中的关键作用:从高速缓存到数据湖
-
浅析不同NAND架构的差异与影响
-
SSD基础架构与NAND IO并发问题探讨
-
字节跳动ZNS SSD应用案例解析
-
SSD数据在写入NAND之前为何要随机化?
-
深度剖析:DMA对PCIe数据传输性能的影响
-
NAND Vpass对读干扰和IO性能有什么影响?
-
HDD与QLC SSD深度对比:功耗与存储密度的终极较量
-
NVMe SSD:ZNS与FDP对决,你选谁?
-
如何通过优化Read-Retry机制降低SSD读延迟?
-
关于硬盘质量大数据分析的思考
-
存储系统性能优化中IOMMU的作用是什么?
-
全景解析SSD IO QoS性能优化
-
NVMe IO数据传输如何选择PRP or SGL?
-
浅析nvme原子写的应用场景
-
多维度深入剖析QLC SSD硬件延迟的来源
-
浅析PCIe链路LTSSM状态机
-
浅析Relaxed Ordering对PCIe系统稳定性的影响
-
实战篇|浅析MPS对PCIe系统稳定性的影响
-
浅析PCI配置空间
-
浅析PCIe系统性能
-
存储随笔《NVMe专题》大合集及PDF版正式发布!

如果您也想针对存储行业分享自己的想法和经验,诚挚欢迎您的大作。
投稿邮箱:Memory_logger@163.com (投稿就有惊喜哦~)
《存储随笔》自媒体矩阵

更多存储随笔科普视频讲解,请移步B站账号:
这篇关于OCP NVME SSD规范解读-13.Self-test自检要求的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





