本文主要是介绍【视觉语言大模型+LLaVA1.0】大语言模型视觉助手(视觉指令调优)GPT4-Vision丐版,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
官方资源汇总: 项目主页 || https://huggingface.co/liuhaotian
23.04.LLaVA1.论文: Large Language and Vision Assistant(Visual Instruction Tuning)
23.10 LLaVA-1.5论文: Improved Baselines with Visual Instruction Tuning
23.11 LLaVA-Plus项目:LLaVA-Plus: Large Language and Vision Assistants that Plug and Learn to Use Skills
24.01 LLaVA-1.6 博客(论文还未出): LLaVA-NeXT: Improved reasoning, OCR, and world knowledge
本地部署参考:https://blog.csdn.net/zhzxlcc/article/details/133773891
其他: 23.02.大语言模型LLaMA项目: Open and Efficient Foundation Language Models
文章目录
- 一、简介
- 1.0 为什么要学习LLaVA? (开源+性能好+多模态+持续更新)
- 1.1 基本术语
- 1.1.1 什么是LLaVA ? (大语言模型视觉助手)
- 1.1.2 语言视觉特征对齐? (将图片视觉特征映射到文本特征层)
- *1.2 能干什么?(实现部分-GPT4Vision的能力)
- 1.2.1 `草图生成网页`相关的 html / js代码 (原图2)(同时能识别字符的能力)
- 1.2.2 无需提示内容,能够识别用户意图(根据冰箱内图片提供菜谱)
- 1.2.3 继承大语言模型的知识 (图4)
- 1.2.4 能识别名画 (原图5)
- 1.2.5-LLaVa 本身没有训练马斯克的图片,继承了CLIP的先验学习过 (原图6)
- 1.2.6 图片中字符的识别与读取能力
- 1.3 LLaVA1.0 原文摘要 : 23.04 Visual Instruction Tuning
- 1.3.1 **贡献**:
- 二、如何`训练`?
- 2.0 数据集
- 2.0.1 指令跟踪数据的一个示例
- 2.1 对齐图像和语言特征 (将图片特征映射到语言模型的特征层)
- 2.1.1 数据集相关
- 2.1.2 训练基础模型+时间
- 2.1.3 训练脚本
- 2.2 视觉指令微调 (Visual Instruction Tuning)
- 2.2.1 准备数据集 ([LLaVA-Instruct-150K](https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/tree/main) + [COCO train2017 images](https://cocodataset.org/#download) )
- 2.2.2 原始的训练脚本:[3-epoch schedule on the LLaVA-Instruct-158K datase](https://github.com/haotian-liu/LLaVA/blob/main/scripts/finetune_full_schedule.sh)
- 三、本地部署 (linux服务器,未压缩时GPU约13G显存 )
- 3.1 环境相关 (需要安装好cuda驱动)
- 3.1.1 pip安装其他依赖
- 3.2 下载模型
- 3.2.1下载 llavav1.5模型
- 3.2.2 下载视觉编码器
- 3.3 运行 服务后台端、模型端、ui界面
一、简介
1.0 为什么要学习LLaVA? (开源+性能好+多模态+持续更新)
它对标的是 GPT4-Vison模型,使聊天助手,具备了解析图片的能力
生态好,一直在更新!
开源了模型、数据、论文也写的贼好! 图from 多模态综述

1.1 基本术语
1.1.1 什么是LLaVA ? (大语言模型视觉助手)
LLaVA: Large Language and Vision Assistant
一个端到端训练的大型多模态模型,将视觉编码器(vision encoder)和LLM(large language model ,大语言模型)连接起来,
用于通用的视觉和语言理解 (general-purpose visual and language understanding)
就是将图片的视觉特征,映射到了预训练的LLMs中embdding向量,通过2轮的训练,实现对图片理解,并继承大模型能力。
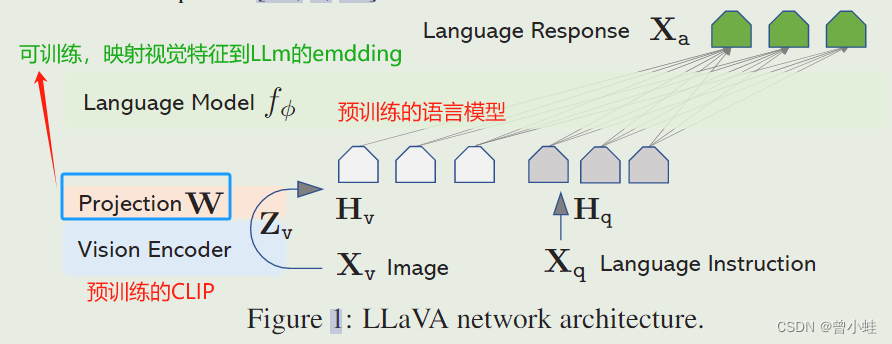
1.1.2 语言视觉特征对齐? (将图片视觉特征映射到文本特征层)
特征对齐是一种在多模态模型中训练视觉和语言编码器以便在共享空间中表示图像和文本的方法。
在视觉指令调整(Visual Instruction Tuning)中,特征对齐是通过预训练的视觉编码器(如CLIP的ViT-L/14)提取图像特征,并使用简单的线性层将这些特征连接到语言模型的词嵌入空间来实现的。
这样,图像特征可以与预训练语言模型(LLM)的词嵌入对齐。这个阶段可以理解为训练一个与冻结LLM兼容的视觉分词器。
*1.2 能干什么?(实现部分-GPT4Vision的能力)
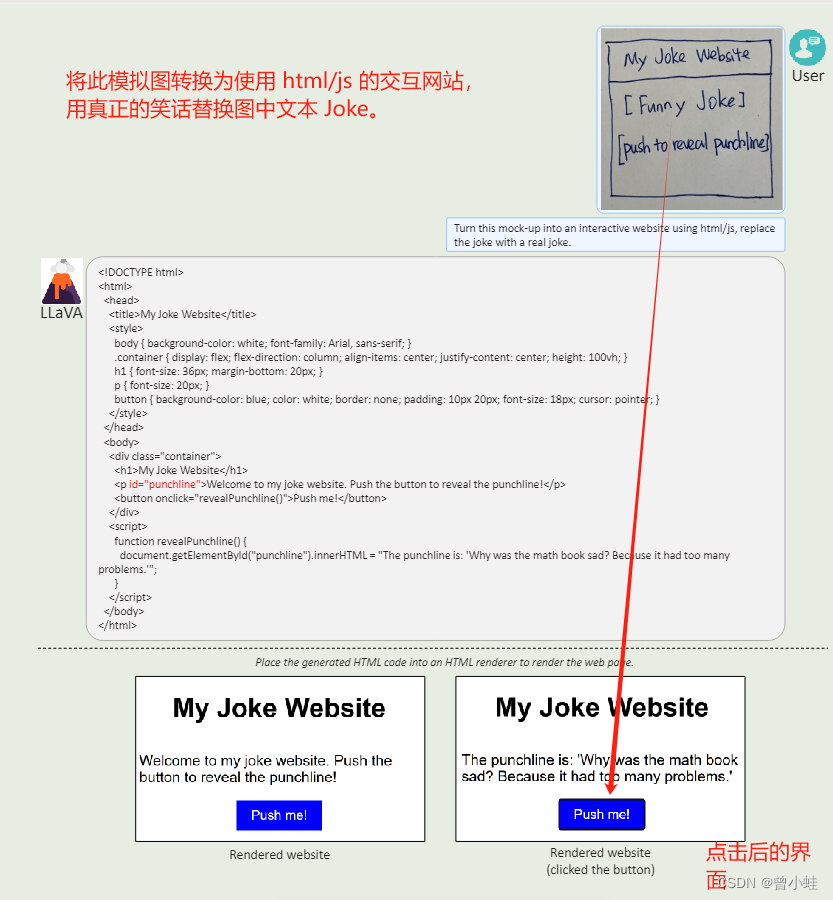
1.2.1 草图生成网页相关的 html / js代码 (原图2)(同时能识别字符的能力)
Turn this mock-up into an interactive website using html/js, replacethe joke with a real joke.
将此模型转换为使用 html/js 的交互网站,用真正的笑话替换文本joke (点击后)。
1.2.2 无需提示内容,能够识别用户意图(根据冰箱内图片提供菜谱)
提问:图片+文字:我能用这些做什么饭?
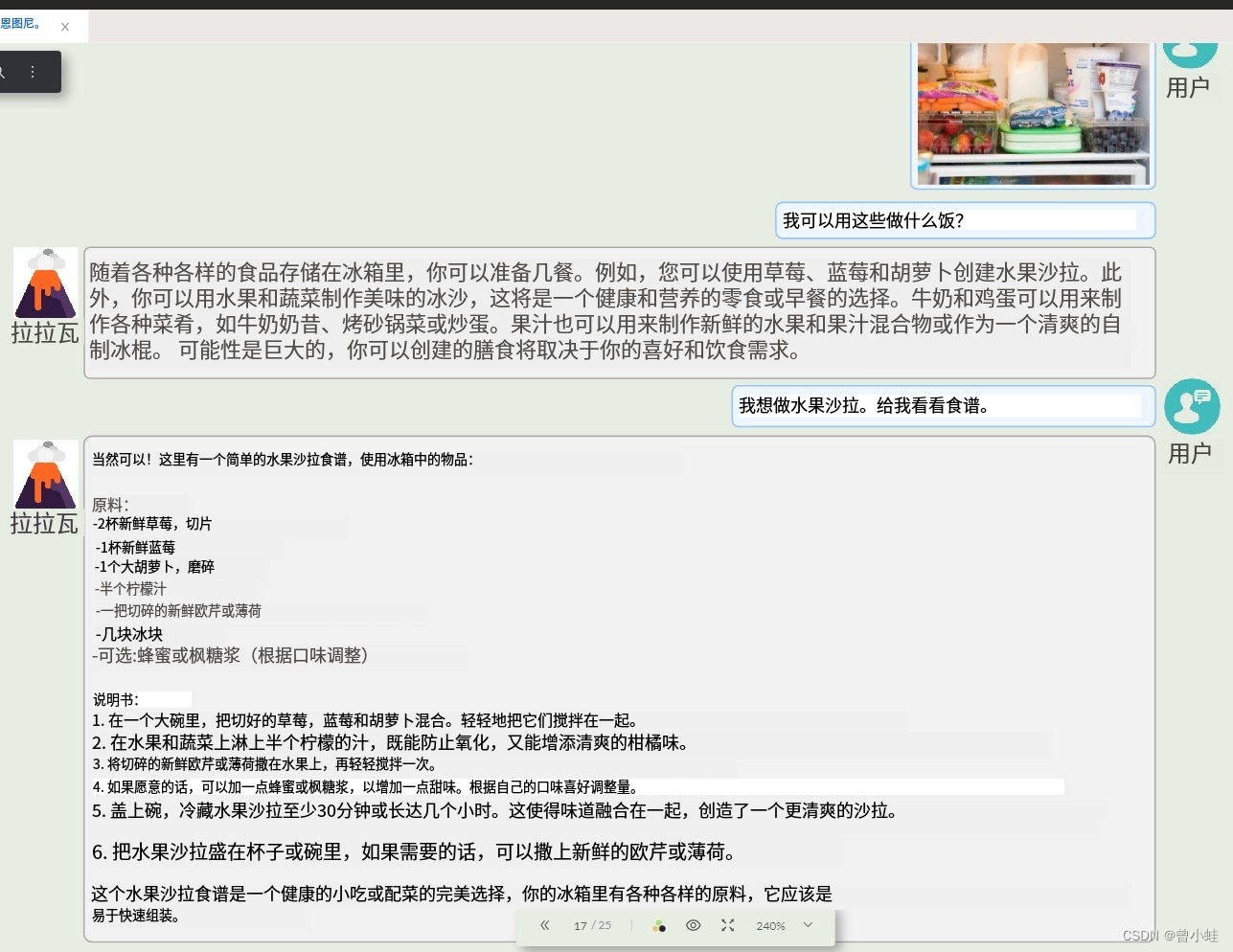
回应原文
Certainly! Here’s a simple fruit salad recipe using the items in your refrigerator:
Ingredients:
- 2 cups fresh strawberries, sliced
- 1 cup fresh blueberries
- 1 large carrot, grated
- Juice of half a lemon
- A handful of chopped fresh parsley or mint- A few ice cubes
- Optional: honey or maple syrup (adjust to taste)
Instructions:1. In a large bowl, combine the sliced strawberries, blueberries, and carrot. Gently toss them together to mix.2. Drizzle the juice of half a lemon over the fruit and vegetables to prevent them from oxidizing and add a refreshing citrus flavor.3. Sprinkle the chopped fresh parsley or mint over the fruit and gently toss once more.4. If desired, add a drizzle of honey or maple syrup for a touch of sweetness. Adjust the amount according to your taste preferences.5. Cover the bowl and refrigerate the fruit salad for at least 30 minutes or up to a few hours. This allows the flavors to meld and creates amore refreshing salad.6. Serve the fruit salad in cups or bowls, garnished with a sprinkle of fresh parsley or mint, if desired.This fruit salad recipe is perfect for a healthy snack or side dish, and with the variety of ingredients available in your refrigerator, it should beeasy to put together quickly.
1.2.3 继承大语言模型的知识 (图4)

1.2.4 能识别名画 (原图5)
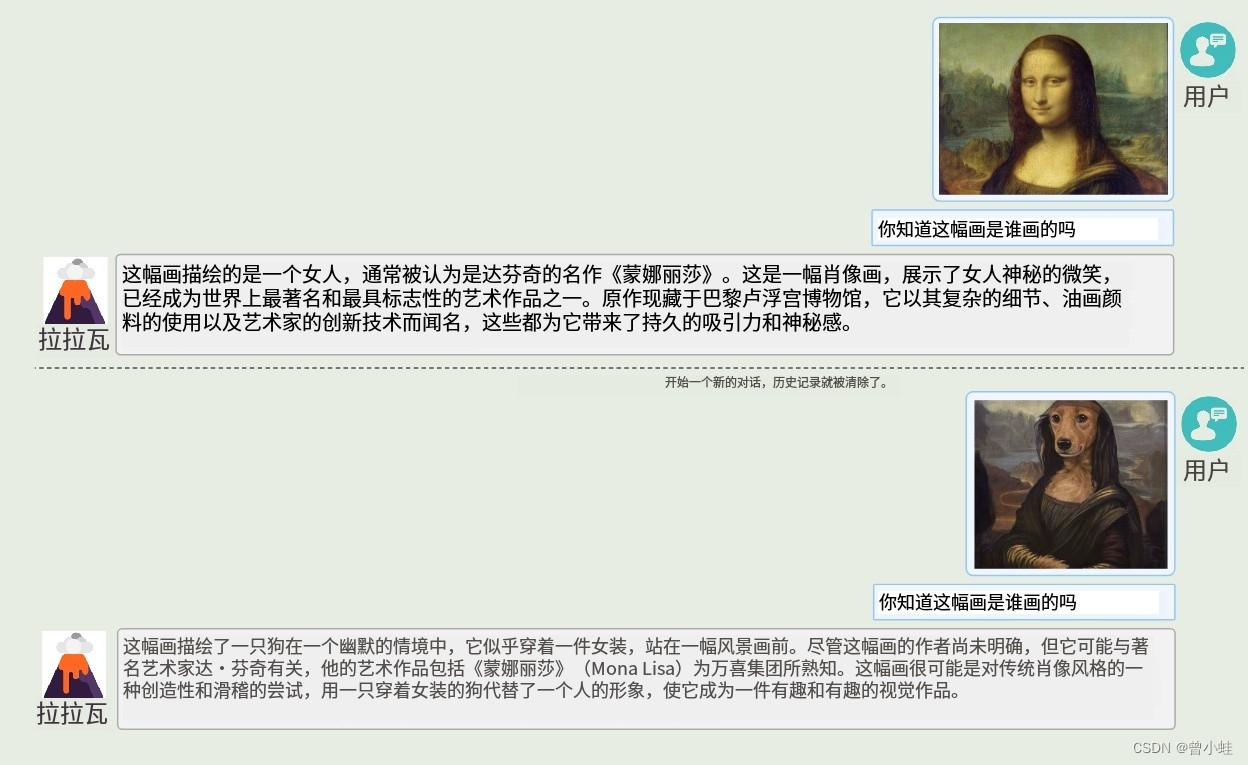
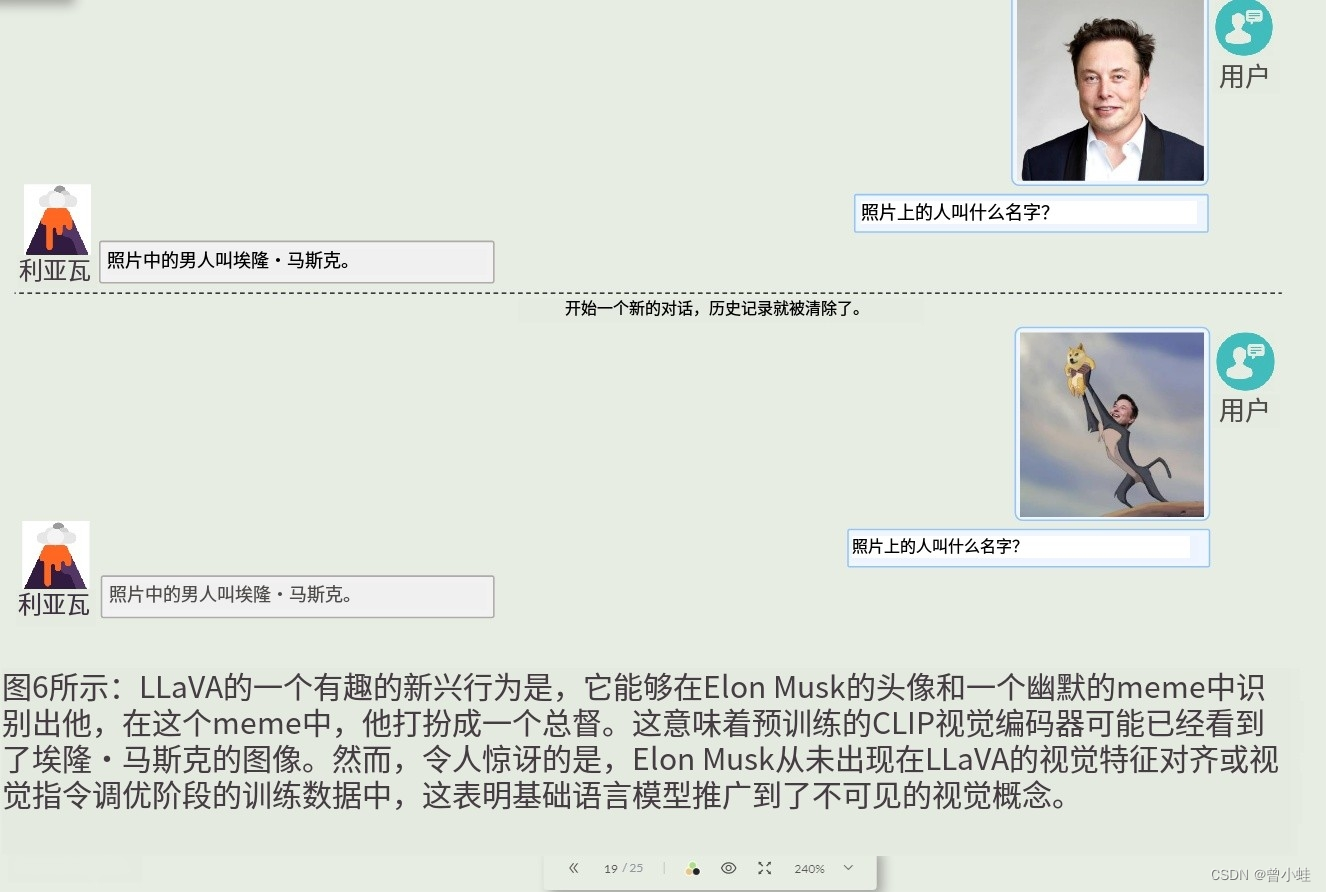
1.2.5-LLaVa 本身没有训练马斯克的图片,继承了CLIP的先验学习过 (原图6)
An interesting emergent behavior of LLaVA is its ability to recognize Elon Musk both in a headshot and in a humorous meme where he is dressed as a doge. This implies that the pre-trained CLIP vision encoder may have seen images of Elon Musk. However, it is still surprising because Elon Musk
never appearsin the training data for either the visual feature alignment or visual instruction tuning stages of LLaVA, which indicates that the base language model generalizes tounseen visual concepts(识别没有对齐过的图像).
1.2.6 图片中字符的识别与读取能力
输入图片

原文是英语(翻译为中文了)

1.3 LLaVA1.0 原文摘要 : 23.04 Visual Instruction Tuning
论文: Large Language and Vision Assistant(Visual Instruction Tuning)
具有多模态聊天能力(multimodal chat abilities),有时在看不见的图像/指令上表现出多模态GPT-4类似能力,与GPT-4在合成的多模态指令遵循数据集上相比,产生了85.1%的相对分数。
当在Science QA上进行微调时,LLaVA和GPT-4的协同作用(synergy)达到了92.53%的最新水平.
在1.0中,我们提出了**视觉指令调整**(visual instruction-tuning),这是将指令微调(instruction-tuning)扩展到语言-图像多模态空间的首次尝试,为构建通用视觉助手铺平了道路。
做出了以下
1.3.1 贡献:
- 多模态遵循指令数据(Multimodal instruction-following data)。一项关键挑战是缺乏视觉语言指令跟踪数据。我们提出了一种数据重组视角和方法(pipeline),使用 ChatGPT/GPT-4,
将图像文本对转换为适当的指令遵循格式(instruction-following format)。 - 大型多模态模型(Large multimodal models)。我们通过将 CLIP 的开放集视觉编码器与语言解码器Vicuna 连接起来,开发了一个大型多模态模型(LMM),并对我们生成的教学视觉语言数据进行端到端微调。我们的实证研究验证了使用生成的数据进行 LMM 指令调整的有效性,并提出了构建通用指令跟踪视觉代理的实用技巧。当与 GPT-4 集成时,我们的方法在 Science QA [34] 多模态推理数据集上实现了 SoTA。
- 多模式指令遵循基准。我们向 LLaVA-Bench 提供了两个具有挑战性的基准,以及多种配对图像、说明和详细的标注。
- 开源。我们向公众发布以下资源:生成的多模式指令数据、代码库、可视化聊天的示例交互程序。
二、如何训练?
训练文档:https://github.com/haotian-liu/LLaVA/tree/v1.0.1?tab=readme-ov-file#train
二阶段训练 (Feature Alignment + 视觉微调)
2.0 数据集
** GPT-4 扩展**
输入收集到的图片简单本文(caption),以及图片中主体的位置(box),输入到纯文本的gpt4模型中(不输人图片)
2.0.1 指令跟踪数据的一个示例
顶部块显示了用于提示 GPT 的字幕和框等上下文,
底部块显示了三种类型的响应。
请注意,视觉图像不用于提示 GPT,我们仅将其此处显示为参考。

Table 1: One example to illustrate the instruction-following data. The top block shows the contexts such as captions and boxes used to prompt GPT, and the bottom block shows the three types of responses. Note that the visual image is not used to prompt GPT, we only show it here as a reference.
2.1 对齐图像和语言特征 (将图片特征映射到语言模型的特征层)
2.1.1 数据集相关
过滤 **CC3M**数据集选出 595K image-text 对 : 下载地址-LLaVA-CC3M-Pretrain-595K
2.1.2 训练基础模型+时间
在基础大语言模型(LLMs) Vicuna 上进行训练,推荐使用DeepSpeed框架训练
在8x A100(80G)上,LLAVA-13B大约需要4个小时。 7B检查点大约需要2个小时
1x A100 (80G): LLaVA-13B,. Time: ~33 hours. (也可以)
2.1.3 训练脚本
https://github.com/haotian-liu/LLaVA/blob/main/scripts/pretrain.sh
#!/bin/bash# IMPORTANT: this is the training script for the original LLaVA, NOT FOR LLaVA V1.5!# Uncomment and set the following variables correspondingly to run this script:# MODEL_VERSION=vicuna-v1-3-7b
# MODEL_VERSION=llama-2-7b-chat########### DO NOT CHANGE ###########
########### USE THIS FOR BOTH ###########
PROMPT_VERSION=plain
########### DO NOT CHANGE ###########deepspeed llava/train/train_mem.py \--deepspeed ./scripts/zero2.json \--model_name_or_path ./checkpoints/$MODEL_VERSION \--version $PROMPT_VERSION \--data_path /path/to/pretrain_data.json \--image_folder /path/to/images \--vision_tower openai/clip-vit-large-patch14 \--tune_mm_mlp_adapter True \--mm_vision_select_layer -2 \--mm_use_im_start_end False \--mm_use_im_patch_token False \--bf16 True \--output_dir ./checkpoints/llava-$MODEL_VERSION-pretrain \--num_train_epochs 1 \--per_device_train_batch_size 16 \--per_device_eval_batch_size 4 \--gradient_accumulation_steps 1 \--evaluation_strategy "no" \--save_strategy "steps" \--save_steps 24000 \--save_total_limit 1 \--learning_rate 2e-3 \--weight_decay 0. \--warmup_ratio 0.03 \--lr_scheduler_type "cosine" \--logging_steps 1 \--tf32 True \--model_max_length 2048 \--gradient_checkpointing True \--dataloader_num_workers 4 \--lazy_preprocess True \--report_to wandb
2.2 视觉指令微调 (Visual Instruction Tuning)
总是保持视觉编码器的权重冻结,并继续更新LLaVA中投影层(特征对齐)和LLM的预训练模型权重;即(3)中的可训练参数为θ = {W, φ}。我们考虑两种特定的用例场景:
2.2.1 准备数据集 (LLaVA-Instruct-150K + COCO train2017 images )
总共收集了 158K 个遵循指令的数据(instruction-following data)语言-图像:
包括关于图像内容的对话中的 58K、详细描述 23K 复杂推理 77k。
2.2.2 原始的训练脚本:3-epoch schedule on the LLaVA-Instruct-158K datase
deepspeed llava/train/train_mem.py \--deepspeed ./scripts/zero2.json \--model_name_or_path ./checkpoints/$MODEL_VERSION \--version $PROMPT_VERSION \--data_path ./playground/data/llava_instruct_158k.json \--image_folder /path/to/coco/train2017 \--vision_tower openai/clip-vit-large-patch14 \--pretrain_mm_mlp_adapter ./checkpoints/llava-$MODEL_VERSION-pretrain/mm_projector.bin \--mm_vision_select_layer -2 \--mm_use_im_start_end False \--mm_use_im_patch_token False \--bf16 True \--output_dir ./checkpoints/llava-$MODEL_VERSION-finetune \--num_train_epochs 3 \--per_device_train_batch_size 16 \--per_device_eval_batch_size 4 \--gradient_accumulation_steps 1 \--evaluation_strategy "no" \--save_strategy "steps" \--save_steps 50000 \--save_total_limit 1 \--learning_rate 2e-5 \--weight_decay 0. \--warmup_ratio 0.03 \--lr_scheduler_type "cosine" \--logging_steps 1 \--tf32 True \--model_max_length 2048 \--gradient_checkpointing True \--dataloader_num_workers 4 \--lazy_preprocess True \--report_to wandb
三、本地部署 (linux服务器,未压缩时GPU约13G显存 )
官网参考:https://github.com/haotian-liu/LLaVA
可参考:https://blog.csdn.net/zhzxlcc/article/details/133773891
3.1 环境相关 (需要安装好cuda驱动)
根据自己显卡驱动,在pytorch官方选择对应的版本: https://pytorch.org/get-started/previous-versions/
conda create -n llava python=3.10 -yconda activate llava
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=11.8 -c pytorch -c nvidia3.1.1 pip安装其他依赖
根据 LLaVA/pyproject.toml 建立其他依赖环境
pip install -r install.txt
install.txt的内容 (自己新建)
torch==2.1.2
torchvision==0.16.2
transformers==4.37.2
tokenizers==0.15.1
sentencepiece==0.1.99
shortuuid
accelerate==0.21.0
peft
bitsandbytes
pydantic
markdown2
numpy
scikit-learn==1.2.2
gradio==4.16.0
gradio_client==0.8.1
requests
httpx==0.24.0
uvicorn
fastapi
einops==0.6.1
einops-exts==0.0.4
timm==0.6.13
deepspeed==0.12.6
ninja
wandb
3.2 下载模型
配置官方下载工具包
pip install -U huggingface_hub hf-transfer
export HF_ENDPOINT=https://hf-mirror.com # linux
# $env:HF_ENDPOINT = "https://hf-mirror.com" # windows
export HF_HUB_ENABLE_HF_TRANSFER=1 # 官方加速报错,就关了3.2.1下载 llavav1.5模型
huggingface-cli download --resume-download liuhaotian/llava-v1.5-7b --local-dir ./weights/llava-v1.5-7bhuggingface-cli download --resume-download liuhaotian/llava-v1.5-13b --local-dir ./weights/llava-v1.5-13b
3.2.2 下载视觉编码器
huggingface-cli download --resume-download openai/clip-vit-large-patch14-336 --local-dir ./models/clip-vit-large-patch14-336
3.3 运行 服务后台端、模型端、ui界面
其中 CUDA_VISIBLE_DEVICES=0 表示选择哪个显卡进行运行,值可为0,1,2
# service
conda activate llava
cd ~/code/LLaVA # 你的llava项目位置
CUDA_VISIBLE_DEVICES=0 python -m llava.serve.controller --host 0.0.0.0 --port 10000# model
CUDA_VISIBLE_DEVICES=0 python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 2006 --worker http://localhost:2006 --model-path /data/zengxingyu/code/LLaVA/weights/llava-v1.5-7b/
#
CUDA_VISIBLE_DEVICES=0 python -m llava.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload
这篇关于【视觉语言大模型+LLaVA1.0】大语言模型视觉助手(视觉指令调优)GPT4-Vision丐版的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








