本文主要是介绍【ACL 2023获奖论文】再现奖:Do CoNLL-2003 Named Entity Taggers Still Work Well in 2023?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【ACL 2023获奖论文】再现奖:Do CoNLL-2003 Named Entity Taggers Still Work Well in 2023?
- 写在最前面
- 动机
- 主要发现和观点
- 总结
- 正文
- 1引言
- 6 相关工作
- 解读
- 2 注释一个新的测试集以度量泛化
- CoNLL++数据集的创建
- 数据集统计
- 注释质量与评估者间协议
- 目标与意义
- 3 实验装置
- 模型选择
- 实验设置
- 微调与评估
- 结果分析
- 4 好的泛化需要什么成分?
- 模型尺寸
- 模型架构
- 微调示例的数量
- 预训练语料库的时间跨度
- 总结
- 5 是什么导致了某些模型的性能下降?
- 自适应过拟合
- 时间漂移
- 解决方案和见解
- 总结
- 7 总结和未来发展方向
- 未来发展方向
- 总结
- 8 局限性
- 对未来研究的意义

前些天发现了一个人工智能学习网站,内容深入浅出、易于理解。如果对人工智能感兴趣,不妨点击查看。
写在最前面
在做论文工作时,发现一个问题:不清楚好的论文框架是什么样的,所以来拜读一下【ACL2023获奖论文】,提升一下品味
今天阅读的是【ACL 2023获奖论文】再现奖:Do CoNLL-2003 Named Entity Taggers Still Work Well in 2023?
标题:比你想的更弱:对弱监督学习的批判性审视
论文地址:https://aclanthology.org/2023.acl-long.796/
数据集地址:https://github.com/ShuhengL/acl2023_conllpp
没有搜到参考的论文解读,神奇
一些不成熟的想法
1、最好包含一些公式,简单的也行

2、图表包含的信息量很大
3、实验部分划分很清晰,标题有意思 --》
4 好的泛化需要什么成分?
4.1 模型尺寸
4.2 模型架构
4.3 微调示例的数量
5 是什么导致了某些模型的性能下降?
5.1 自适应过拟合
5.1.1 收益递减
5.1.2 测试重用
5.2 时间漂移
5.2.1 Flair和ELMo的时间漂移
5.2.2 RoBERTa的时间漂移
动机
我们研究了为什么有些模型对新数据的泛化能力很好,而另一些则不行,并试图解开由于测试重用而导致的时间漂移和过拟合的影响。
我们的分析表明,大多数恶化是由于时间不匹配之间预训练语料库和下游测试集。
我们发现有四个因素很重要良好的泛化:模型架构,参数数量,时间段预训练语料库,以及微调数据量。
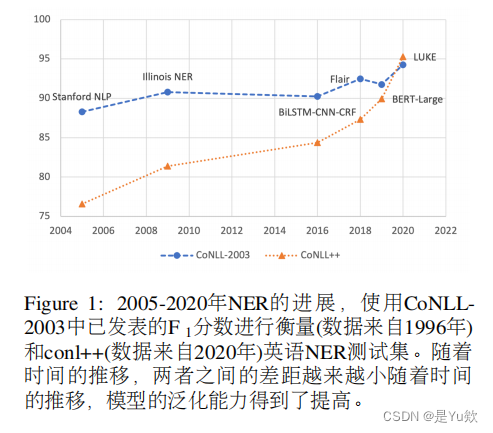
主要发现和观点
-
泛化能力的差异:研究显示,不同的NER模型在泛化到现代数据时显示出显著差异。值得注意的是,尽管使用了几十年前的数据进行微调,一些基于预训练transformer的模型(如RoBERTa和T5)并未表现出性能下降。
-
重要因素:文章分析了影响模型泛化能力的几个关键因素,包括模型架构、参数数量、预训练语料库的时间跨度,以及微调数据的量。发现这些因素对于模型在面对新数据时的适应性至关重要。
-
时间漂移的影响:大多数性能恶化似乎是由于预训练语料库和下游测试集之间时间不匹配造成的时间漂移。通过使用更新的预训练数据,一些模型展示了改善的泛化能力,表明时间漂移是影响NER模型性能的一个主要因素。
-
测试重用和过拟合:尽管存在测试重用的担忧,但本研究未发现证据表明预训练transformer模型性能下降与过拟合有关。这表明过去20年间在CoNLL-2003测试集上取得的进展主要不是由于模型过拟合。
总结
该研究提供了对NER模型泛化能力深入的理解,特别是在长时间跨度下的性能变化。通过创建CoNLL++测试集和对多个模型的评估,揭示了时间漂移对模型性能的影响及其与过拟合无关。
此外,研究还强调了模型架构、参数规模、预训练数据的时效性和微调数据量在模型泛化中的重要性。这些发现不仅为未来NER模型的开发提供了宝贵的见解,也对如何评估模型在面对新兴数据时的适应性提供了新的视角。
今天阅读的是【ACL 2023获奖论文】再现奖:4.Do CoNLL-2003 Named Entity Taggers Still Work Well in 2023?
标题:CoNLL-2003命名实体标注模型在2023年的表现如何?
论文地址:https://aclanthology.org/2023.acl-long.459/
内容:Named Entity Recognition(命名实体识别)是自然语言处理的一个重要而深入研究的任务。经典的CoNLL-2003英文数据集发布于近20年前,常被用来训练和评估命名实体标注模型。数据集的年代久远引发了模型在现代数据上的泛化能力的疑问。
本文提出了CoNLL++,这是仿照CoNLL-2003测试集标注流程生成的新测试集,区别在于使用了2020年的数据。利用CoNLL++,作者评估了20多个不同模型在现代数据上的泛化能力,发现不同模型的泛化表现差异很大。在最近数据上预训练的大型变压器基模型的F1分数下降较小,而使用静态词嵌入的模型下降较大,基于RoBERTa和T5的模型在CoNLL-2003和CoNLL++上的F1分数相当。
实验表明,获得良好的泛化能力需要结合开发较大模型和持续使用与领域相关的近期数据进行预训练。这些结果表明,标准评估方法可能低估了过去20年命名实体识别任务的进展,除了原数据集上的性能提升,作者还改进了模型对现代数据的泛化能力。
正文
为了深入理解命名实体识别(NER)模型在处理现代数据时的泛化能力,研究者创建了一个新的测试集,名为CoNLL++。该测试集的目的是衡量在CoNLL-2003数据集上训练的模型在面对更新的数据时的表现。CoNLL++紧密模仿了CoNLL-2003的结构和格式,但使用了2020年的新闻文章,而不是原始数据集中的1996年数据。通过这种方式,研究者旨在探讨模型在长时间跨度后对新数据的适应性。
1引言
本文从多个角度分析了命名实体识别(NER)在长时间跨度内的泛化能力和性能变化,特别是在经过近20年的时间演变后,使用CoNLL-2003数据集训练的模型在现代数据上的表现。
通过创建一个新的测试集CoNLL++,使用2020年的数据而非原始数据集中的1996年数据,作者们对20多个NER模型进行了评估,以探究这些模型的泛化能力。
6 相关工作
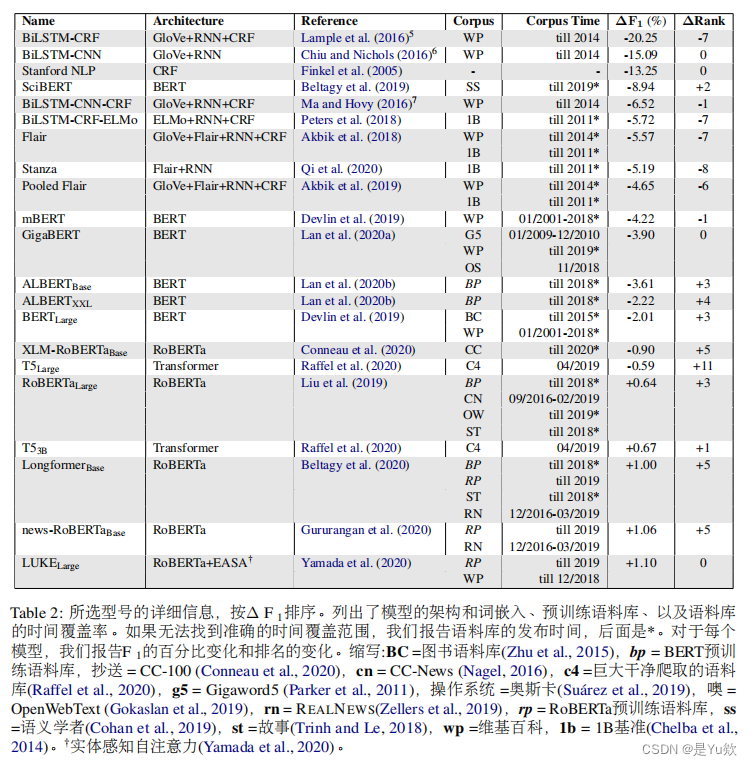
为了直观地呈现本研究与先前相关工作之间的关系和区别,下面以表格形式总结了几项关键的相关研究,并提供了对比分析。
| 研究 | 焦点 | 方法 | 关键发现 |
|---|---|---|---|
| 本研究 | NER模型的长期泛化能力 | 创建CoNLL++测试集,比较20年间的模型表现 | 时间漂移是性能下降的主要原因,而非自适应过拟合 |
| Agarwal & Nenkova (2022) | 预训练模型对语言处理任务的时间效应 | 分析Twitter NER数据集 | 使用基于RoBERTa的表示时,没有发现性能随时间退化 |
| Rijhwani & Preotiuc-Pietro (2020) | NER性能随时间的变化 | 使用新闻数据创建时间敏感的NER数据集 | GloVe和Flair嵌入的性能随时间距离增加而下降 |
| Lazaridou et al. (2021) | 语言模型对未来数据适应性 | 分析LM在不同时间数据上的表现 | LMs性能随训练和测试数据时间差异增加而下降 |
| Luu et al. (2022) | 模型在时间错位情况下的性能 | 分析各种任务的时间漂移影响 | 时间错位是多个NLP任务性能下降的原因 |
解读
本研究在命名实体识别(NER)领域内对模型长期泛化能力进行了深入分析,特别是通过创建CoNLL++测试集,提供了一种评估模型在时间跨度内对新数据适应性的方法。
与先前的工作相比,本研究更加专注于评估多个NER模型在长期内的泛化能力,尤其是分析时间漂移对性能影响的角度。其他相关研究,如Agarwal & Nenkova (2022)和Rijhwani & Preotiuc-Pietro (2020),虽然也触及了时间效应,但更多地聚焦于特定类型的数据集(如Twitter数据)或特定的模型表示(如RoBERTa)。Lazaridou et al. (2021)和Luu et al. (2022)的工作进一步扩展了对时间效应影响的理解,不仅仅限于NER任务,还涵盖了更广泛的NLP任务。
这些研究一起构建了对NLP模型在面对时间变化时性能影响的全面认识,本研究通过特定的数据集和细致的分析,进一步丰富了这一领域的知识库。
2 注释一个新的测试集以度量泛化
CoNLL++数据集的创建
-
数据收集:CoNLL-2003共享任务原先从路透社语料库中收集英语新闻文章(1996年8月至1997年8月)。研究者遵循这一策略,从Common Crawl Foundation收集了2020年12月5日至7日发布的路透社新闻文章,以匹配原始测试集中的token总数。
-
分词和注释:使用与CoNLL-2003相同的分词器对数据进行分词,并通过BRAT注释接口手动标注新数据集,将其命名为CoNLL++。在注释过程中,确保2020年的新文章与CoNLL-2003测试集的文章风格尽可能一致。
数据集统计
CoNLL++与CoNLL-2003测试集在多个方面进行了对比,包括文章发表时间、不同类型实体的数量、标记的数量、唯一标记和每个句子的平均标记数量。这些统计数据展示了两个测试集在结构和内容上的相似性与差异,特别是时间范围的更新为CoNLL++带来了新的挑战和机遇。
注释质量与评估者间协议
为确保注释质量,两位作者分别进行了标注,并交叉检查以评估注释一致性。通过将CoNLL-2003测试集中的标签视为标准,手动重新注释达到了95.46 F1分数,表明CoNLL++注释紧跟原始数据集的风格,并且注释质量高。
目标与意义
通过创建CoNLL++测试集,研究者旨在提供一个工具,用于评估NER模型在长时间跨度后对新数据的泛化能力。这项工作强调了考虑时间漂移影响的重要性,并为未来的NER研究提供了新的方向,特别是在探索模型在应对新兴数据时的适应性和持续性方面。通过对CoNLL++的深入分析,研究者得以揭示不同模型在泛化到新数据时的性能差异,从而为开发更具适应性的NER模型提供了宝贵的见解。
3 实验装置
为了深入探究命名实体识别(NER)模型在长时间跨度后对新数据的泛化能力,研究者设计了一系列实验装置,系统地评估了在CoNLL-2003数据集上训练的不同模型在新创建的CoNLL++测试集上的表现。这些实验不仅着眼于模型性能的直接比较,还旨在分析不同因素如何影响模型的泛化能力。
模型选择
实验包括了具有各种架构和预训练语料库的多个模型,旨在覆盖广泛的技术和方法,从而提供关于NER模型泛化能力的全面视角。这些模型中既包括传统的基于循环神经网络(RNN)的模型,也包括基于Transformer的模型,如BERT和RoBERTa。所有选中的模型都没有使用与CoNLL++时间上重叠的预训练数据,以确保评估结果的公正性。
实验设置
实验中采用了严格的训练和评估流程。对于每个模型,研究者进行了超参数搜索,以找到最佳的训练设置。模型在CoNLL-2003训练集上训练,使用开发集(dev set)来选择最佳的epoch和其他超参数。为了保证结果的可靠性和准确性,每个模型都在CoNLL-2003测试集和CoNLL++上进行了多次评估,以获得平均F1分数。这样的设置旨在确保评估过程既系统又公平,能够准确反映模型的真实泛化能力。
微调与评估
实验中还特别关注了模型微调的过程。研究者探讨了不同的微调策略,包括微调时使用的数据量,以及预训练语料库与测试数据之间时间差异的影响。此外,实验通过对比不同模型在CoNLL-2003和CoNLL++测试集上的性能变化(ΔF1),进一步分析了模型泛化能力的细微差异。
结果分析
通过这些精心设计的实验装置,研究者能够系统地分析和理解NER模型在面对新数据时的泛化表现。实验结果不仅揭示了模型架构、参数数量、预训练数据的时间跨度和微调数据量等因素对泛化能力的影响,还提供了关于时间漂移和测试重用对模型性能影响的重要见解。
总体而言,这些实验装置为评估NER模型的泛化能力提供了一套全面且严谨的方法论,使得研究者能够深入理解不同模型在应对长时间跨度后的新数据时的性能和挑战,从而为未来模型的开发和优化提供了宝贵的指导。
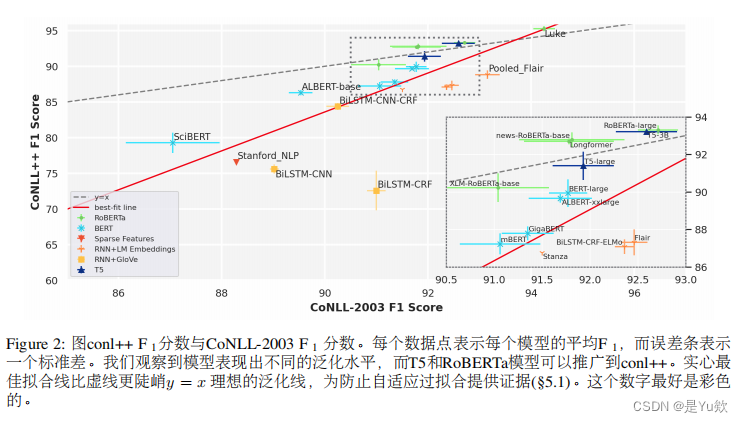
4 好的泛化需要什么成分?
本节探讨了NER模型良好泛化能力的关键成分,基于对20多个不同模型在CoNLL-2003数据集上训练后在新的CoNLL++测试集上的性能评估。研究揭示了影响模型泛化能力的几个重要因素,包括模型架构、参数数量、预训练语料库的时间跨度,以及微调数据量。这些因素共同决定了模型在面对时间漂移和新兴数据时的适应性和效能。
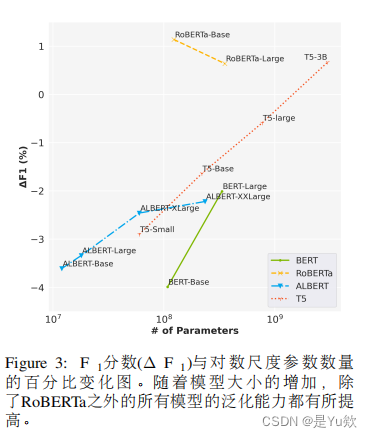
模型尺寸
研究表明,预训练模型的大小对其性能有显著影响。更大的模型通常表现出更好的泛化能力,这可能是因为它们有更强的表示能力和更高的参数效率。在评估中,随着模型参数量的增加,其在CoNLL++上的性能下降减小,甚至在某些情况下消失,特别是对于基于RoBERTa的模型而言。
模型架构
模型架构是影响泛化能力的另一个关键因素。基于transformer的模型(如BERT、RoBERTa和T5)在CoNLL++上表现出较小的性能下降,说明预训练的transformer模型具有更好的新数据泛化能力。这可能是由于transformer架构的自注意力机制能够更有效地捕捉长距离依赖和复杂的上下文关系。
微调示例的数量
微调过程中使用的示例数量也对模型的泛化能力有重要影响。实验表明,使用更多训练示例进行微调可以显著提高模型在CoNLL++测试集上的泛化性能。这强调了充分利用可用训练数据的重要性,以提高模型对新数据的适应性。
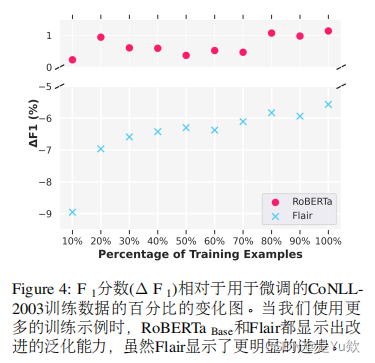
预训练语料库的时间跨度
预训练语料库与测试数据之间的时间跨度是影响模型泛化能力的一个关键因素。时间漂移,即训练数据和测试数据之间的时间差异,可能导致性能下降。研究发现,使用时间上更接近测试集的预训练数据可以减轻这种影响,提高模型的泛化能力。
总结
这些发现强调了在开发NER模型时需要考虑的几个关键因素,以确保模型不仅在原始测试集上表现良好,而且能够有效地泛化到新数据。特别是,选择合适的模型架构、增加模型大小、优化微调过程,并使用更新的预训练数据,是提高模型泛化能力的重要策略。这些成分的综合考量有助于开发出在长时间跨度后依然能够有效应对新兴数据挑战的NER模型。
5 是什么导致了某些模型的性能下降?
在研究中,对于某些模型在CoNLL++测试集上性能下降的原因进行了详细的分析。性能下降被认为可能由两个主要因素导致:自适应过拟合和时间漂移。通过一系列的实验和分析,研究者探讨了这些因素如何影响模型的泛化能力,并提出了相应的见解。
自适应过拟合
自适应过拟合是指模型对于重复使用的测试集过度优化的现象。在长期使用同一测试集的情况下,模型可能无意中学会了测试集的特定特征,而不是泛化到新的数据。研究中通过测量CoNLL-2003和CoNLL++测试集上的性能变化,探讨了自适应过拟合的影响。通过比较模型在两个测试集上的性能,研究者发现没有明显证据表明性能下降是由于自适应过拟合造成的。
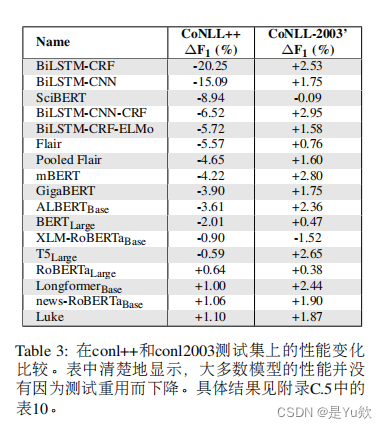
时间漂移
时间漂移是由于训练数据和测试数据之间存在时间上的差异导致的性能下降。随着时间的推移,文本数据中的语言使用、命名实体的出现频率和上下文环境可能会发生变化,导致模型无法有效地识别和处理新数据中的实体。研究通过对不同预训练语料库和模型架构的分析,发现时间漂移是导致某些模型在CoNLL++上性能下降的主要原因。特别是,使用较新的预训练数据可以显著提高模型的泛化能力,减少由于时间漂移导致的性能损失。
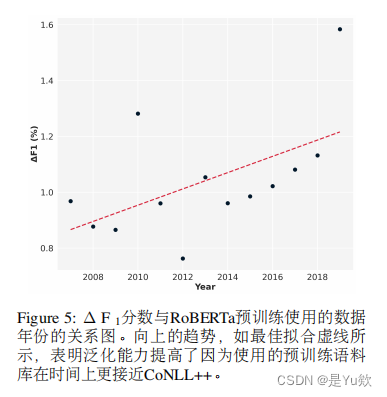
解决方案和见解
针对时间漂移的影响,研究者提出了几种可能的解决方案,包括使用更新的预训练语料库进行模型预训练,以及在模型训练过程中加入时间相关的信息。此外,研究也强调了开发更具鲁棒性的模型架构和训练策略的重要性,以提高模型对时间变化的适应性。
总结
研究结果表明,虽然自适应过拟合对模型性能的影响不明显,但时间漂移是导致某些模型在面对新数据时性能下降的关键因素。通过采取适当的策略来减轻时间漂移的影响,可以显著提高NER模型的泛化能力和在现代数据上的表现。这些发现为未来的NER模型开发提供了重要的指导,强调了考虑时间因素和持续更新模型以适应语言变化的重要性。
7 总结和未来发展方向
本研究通过创建CoNLL++测试集,对20多个在CoNLL-2003数据集上训练的命名实体识别(NER)模型的泛化能力进行了系统评估,揭示了模型在长时间跨度后对新数据的适应性和性能变化。主要发现包括时间漂移是导致模型性能下降的主要原因,而不是自适应过拟合,以及模型架构、参数规模、预训练数据的时效性和微调数据量等因素对模型泛化能力的显著影响。
未来发展方向
-
持续更新的预训练模型:随着时间的推移,语言使用习惯和实体的出现可能会发生变化。因此,定期更新预训练模型,以包含最新的语言使用数据,可能有助于提高模型的泛化能力和适应性。
-
时间敏感的模型训练:开发模型时,考虑引入时间敏感性,例如通过训练数据的时间标签,使模型能够更好地理解和适应时间上的变化。
-
跨域和跨时代的泛化性研究:除了时间跨度的影响,研究模型在不同领域和时代背景下的泛化能力也很重要。这包括对于特定历史时期或特殊领域语言使用习惯的适应性。
-
自动化模型评估和更新机制:随着时间的推移自动监测模型性能,并在检测到性能下降时自动引入新数据进行微调或更新模型,以保持模型的最新性和高性能。
-
深入探索时间漂移的影响因素:进一步研究哪些具体因素导致时间漂移,例如新出现的实体、语言习惯的变化等,并探索针对这些因素的适应性策略。
总结
本研究提供了对NER模型在长时间跨度内泛化能力的深入见解,强调了时间漂移对模型性能的显著影响,并探讨了提高模型适应性的潜在方法。通过持续更新和适应时间变化,未来的NER模型可以更好地应对新兴数据,提高其实用性和准确性。此外,本研究的方法和发现也为其他NLP任务提供了宝贵的参考,有助于推动NLP模型在面对不断变化的语言环境时的发展和优化。
8 局限性
本研究虽然在评估命名实体识别(NER)模型的长期泛化能力方面取得了重要进展,但也存在一些局限性,这些局限性可能影响结果的解读和未来研究的方向。
-
预训练语料库的时间范围不明确:由于一些模型的开发者未公布所使用预训练语料库的确切时间范围,这限制了对时间漂移影响的精确分析。这种不透明性可能掩盖了模型泛化能力与预训练数据时间相关性之间的关系。
-
计算资源的限制:由于计算资源有限,研究中只能在一个新的训练/开发/测试划分上进行实验,可能无法完全捕捉模型性能的变化范围。更多的数据划分可能会提供更全面的性能评估。
-
域内外数据的泛化能力未考虑:本研究主要关注时间跨度对模型性能的影响,而对于模型在不同域(领域)之间的泛化能力的研究相对较少。域内外的泛化是NLP模型面临的另一个重要挑战。
-
依赖特定的测试集(CoNLL++):尽管CoNLL++测试集为本研究提供了一个有用的工具,但它也是一个特定的数据集。模型在CoNLL++上的表现可能不完全代表其在其他现代或未来数据集上的泛化能力。
-
新兴文本类型和语言变化的考虑不足:随着社交媒体和网络语言的迅速发展,文本数据中出现了许多新的类型和用法。本研究可能未能充分考虑这些新兴文本类型对模型泛化能力的影响。
对未来研究的意义
这些局限性不仅指出了本研究的潜在改进方向,也为未来的研究提供了新的问题和挑战。例如,未来的研究可以探索更多关于模型泛化能力的因素,包括不同域的数据、新兴文本类型的适应性,以及在更广泛数据集上的性能评估。此外,透明化模型预训练数据的时间范围和来源,以及开发能够自动适应时间变化的模型,将是未来研究的重要方向。通过克服这些局限性,可以进一步推动NER模型乃至更广泛NLP模型的发展,使其更加鲁棒、适应性强,能够有效应对语言的快速变化和多样性。
这篇关于【ACL 2023获奖论文】再现奖:Do CoNLL-2003 Named Entity Taggers Still Work Well in 2023?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









