本文主要是介绍带有GUI界面的电机故障诊断(MSCNN-BILSTM-ATTENTION模型,TensorFlow框架,有中文注释,带有六种结果可视化),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本次创作最主要是在MSCNN-BILSTM-ATTENTION模型(可轻松替换为其它模型)基础上,搭建GUI测试界面,方便对你想要测试的数据的进行测试,同时进行了全面的结果可视化:1.训练集和测试集的准确率曲线,2.训练集和测试集的损失曲线,3.测试集的混淆矩阵,4.测试集的特征可视化,5.测试集的预测标签与真实标签梯形图,6.测试集的分类报告。
数据集替换提示:本次使用的数据集形式在1.2.小结中有详细介绍,利用一个通道采集的数据,通过1024的长度切割为一个个样本,是故障诊断领域常用的样本形式,如有类似,可轻易替换。
先对大家比较关心的GUI界面进行调用测试样本说明(视频链接:带有GUI界面的电机故障诊断(MSCNN-BILSTM-ATTENTION模型,TensorFlow框架,有中文注释,带有六种结果可视化)_哔哩哔哩_bilibili)

第一个文件夹是测试样本
第二个文件夹是对应的测试样本真实标签类别,方便你核对模型判断结果是否正确
第一个文件夹如下图所示,每个样本就是一个表格。
每个表格里就是1024个数据,如下图所示 ,也就是说只要你随表建立一个表格,里面放相关数据的1024个数据,就可以诊断出类别。


关于背景图片和按钮框等选项都可以任意修改,已经添加中文注释,如果感觉画面布局一般,可以自己优化。

对项目感兴趣,可以关注代码框内最后一行
import pandas as pd
import numpy as np
from keras.utils import np_utils
from sklearn import preprocessing
import tensorflow as tf
from matplotlib import pyplot as plt
from MSCNN_lstm_attention import MSCNN_lstm_attention
#代码和数据集压缩包:https://mbd.pub/o/bread/ZZybk5tw一.数据集介绍:
1.1.电机常见的故障类型有以下几种:
-
轴承故障:轴承是电机运转时最容易受损的部件之一。常见故障包括磨损、疲劳、过热和润滑不良,这些问题可能导致噪音增加和电机性能下降。
-
绝缘老化:电机绝缘材料随着使用时间的增加会老化,失去绝缘性能,导致绝缘击穿和电机短路。
-
绕组故障:电机的绕组可能出现短路、开路或者匝间故障,这些故障会导致电机失去正常运转能力。
-
电刷磨损:对于一些直流电机,电刷是关键部件,其磨损会导致电刷与集电环之间的接触不良,影响电机性能。
-
过载和过热:电机长时间运行在超过额定负载或者额定温度的情况下,会导致电机过热,进而加速其它故障的发生。
-
风扇故障:风扇是电机散热的重要组成部分,若风扇故障导致散热不良,电机温度升高,从而加剧其它故障。
-
不良环境:如果电机运行环境恶劣,如潮湿、灰尘多、腐蚀性气体等,会加速电机故障的发生。
-
频率变化:对于变频驱动的电机,频率的变化可能导致电机在某些转速下共振,损坏电机。
以上仅列举了一些常见的电机故障类型,实际情况还可能会更加复杂。
1.2.数据集介绍(经过上面的电机常见故障分析,这里针对轴承部位故障,绕组故障等情况采集数据)

正常电机的采集数据:(3个通道采集振动信号,3个通道采集电压信号)
正常电机下一共采集362941行数据

其它故障状态下分别采集了140801行数据左右 ,因为现实中故障数据相比正常数据难以获得,所以实验室里采集的正常电机的信号比故障下的信号要多。

2.模型
首先经过尝试,发现第3个振动通道采集的数据对故障更加敏感,这里只选用了第3个振动通道采集的数据作为特征信号。经过不重叠样本(1024的长度)切割,生成样本个数如下
正常:354个样本。
断条:137个样本
偏心:113个样本
匝间短路:105个样本
轴承内圈:118个样本
轴承外圈:104个样本
模型打印

3.结果可视化
3.1.训练集和测试集的准确率曲线,
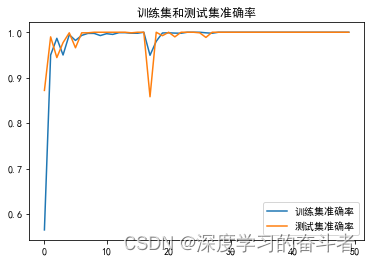
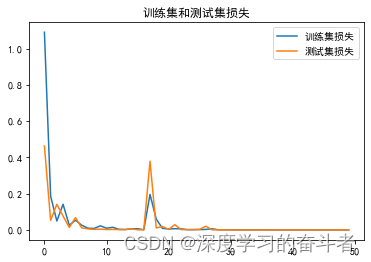
3.2.训练集和测试集的损失曲线,
3.3.测试集的混淆矩阵(以准确率形式呈现)

3.4.测试集的特征可视化,
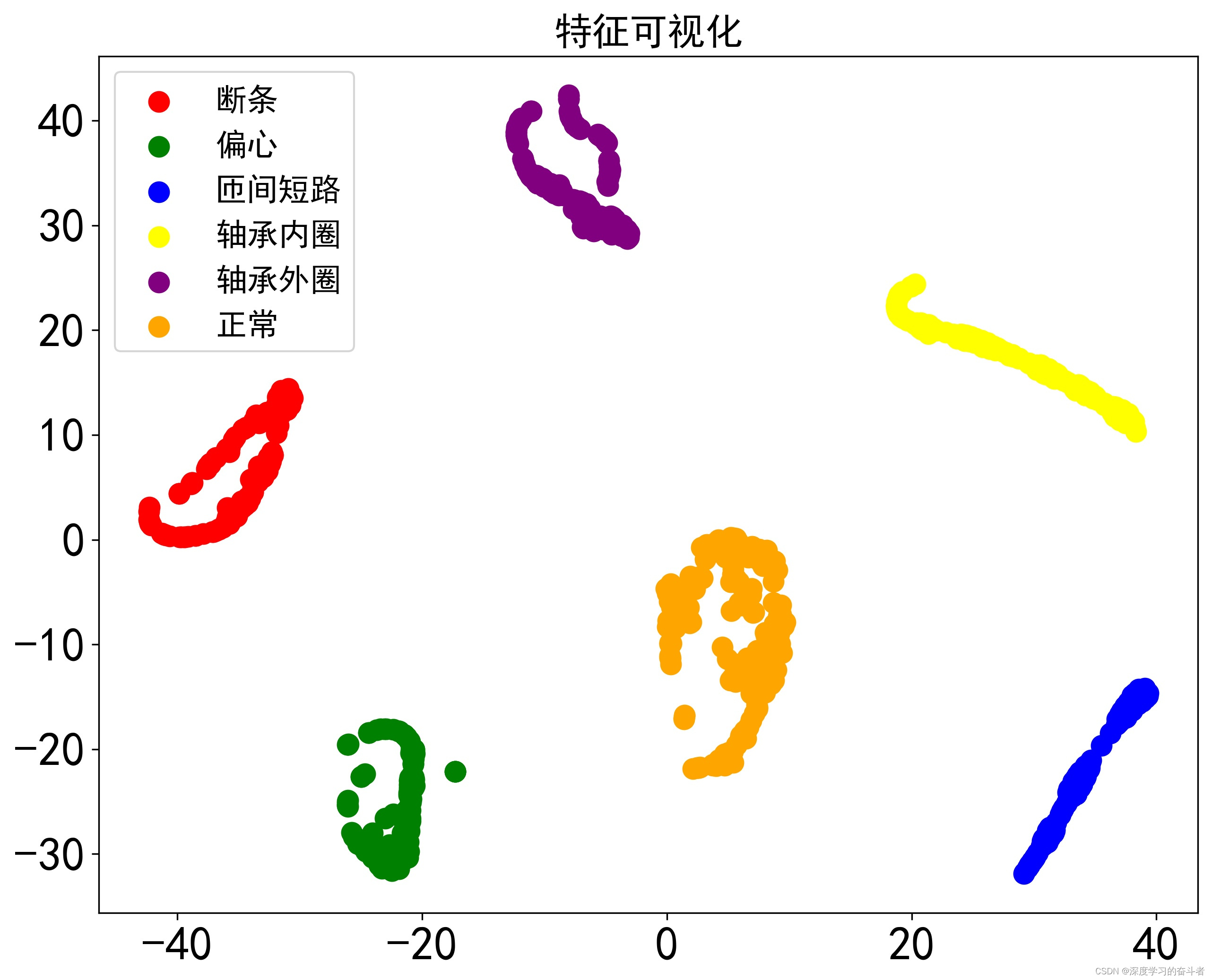
3.5.测试集的预测标签与真实标签梯形图,

3.6.测试集的分类报告。
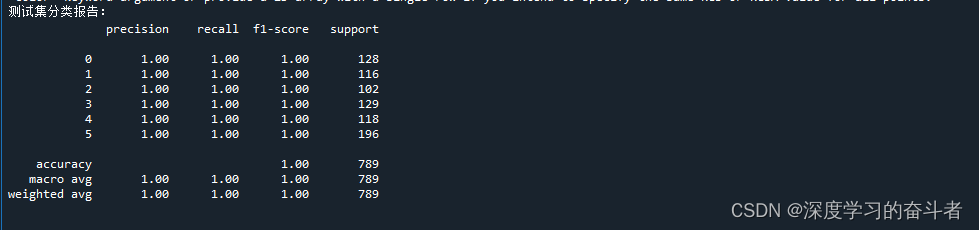
这篇关于带有GUI界面的电机故障诊断(MSCNN-BILSTM-ATTENTION模型,TensorFlow框架,有中文注释,带有六种结果可视化)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








