本文主要是介绍mysql的group by是根据排序第一条来取数的,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天遇到一个问题,将MySQL的sql语句改为Oracle的语句时,MySQL的select的未聚合字段没有全部放在group by里面,这就导致跟Oracle查出来的数据不一致,实验 一: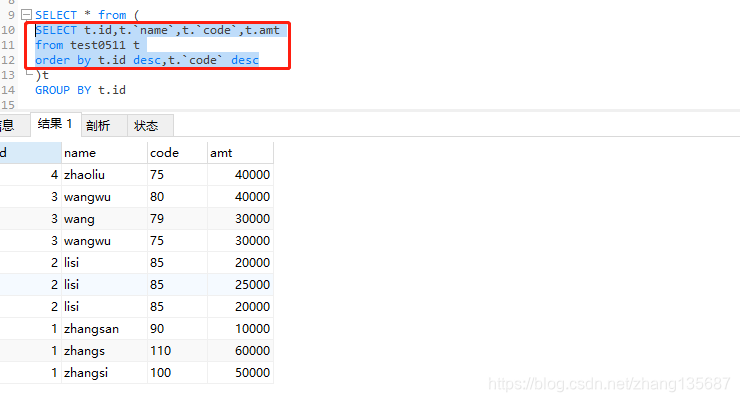
按照id,code的降序排列,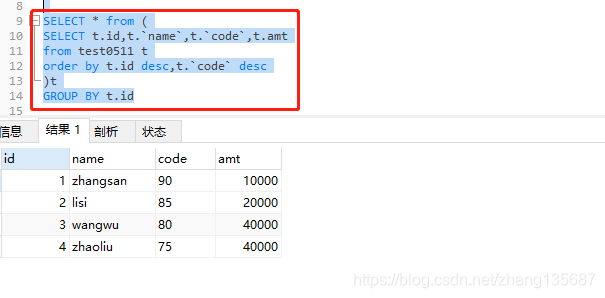
在group by的时候取的是每一组的第一条;
实验二: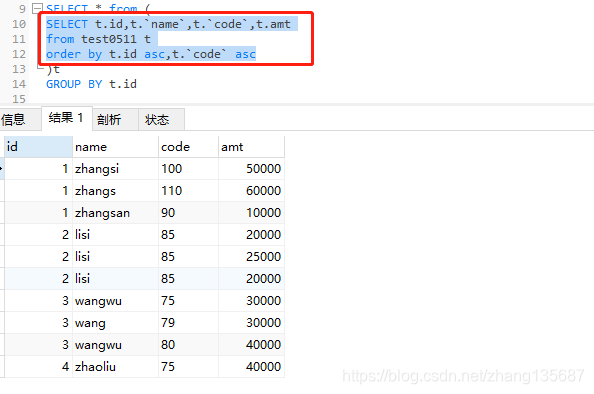
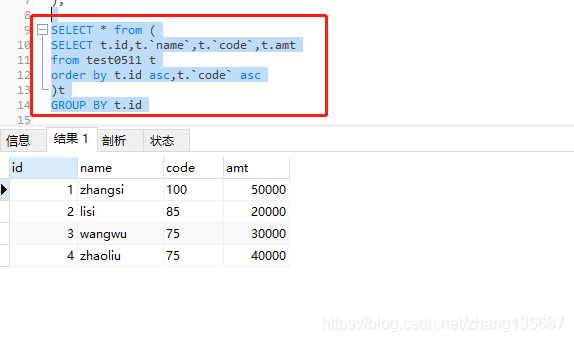
依旧是取的该组的第一条数据
测试代码如下:
DROP TABLE IF EXISTS `test0511`;
CREATE TABLE `test0511` (`id` int(11) NULL DEFAULT NULL,`code` varchar(30) CHARACTER SET latin1 COLLATE latin1_swedish_ci NULL DEFAULT NULL,`name` varchar(30) CHARACTER SET latin1 COLLATE latin1_swedish_ci NULL DEFAULT NULL,`amt` double NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Compact;-- ----------------------------
-- Records of test0511
-- ----------------------------
INSERT INTO `test0511` VALUES (1, '90', 'zhangsan', 10000);
INSERT INTO `test0511` VALUES (2, '85', 'lisi', 20000);
INSERT INTO `test0511` VALUES (4, '75', 'zhaoliu', 40000);
INSERT INTO `test0511` VALUES (1, '100', 'zhangsi', 50000);
INSERT INTO `test0511` VALUES (1, '110', 'zhangs', 60000);
INSERT INTO `test0511` VALUES (2, '85', 'lisi', 25000);
INSERT INTO `test0511` VALUES (2, '85', 'lisi', 20000);
INSERT INTO `test0511` VALUES (3, '80', 'wangwu', 40000);
INSERT INTO `test0511` VALUES (3, '79', 'wang', 30000);
INSERT INTO `test0511` VALUES (3, '75', 'wangwu', 30000);SELECT * from (
SELECT t.id,t.`name`,t.`code`,t.amt
from test0511 t
order by t.id asc,t.`code` asc
)t
GROUP BY t.id
这篇关于mysql的group by是根据排序第一条来取数的的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







