本文主要是介绍leetcode106从中序与后序遍历序列构造二叉树,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 1.解题关键
- 2.思路
- 3.变量名缩写与英文单词对应关系
- 4.算法思路图解
- 5.代码
本文针对原链接题解的比较晦涩的地方重新进行说明解释
原题解链接:https://leetcode.cn/problems/construct-binary-tree-from-inorder-and-postorder-traversal/solutions/50561/tu-jie-gou-zao-er-cha-shu-wei-wan-dai-xu-by-user72
1.解题关键
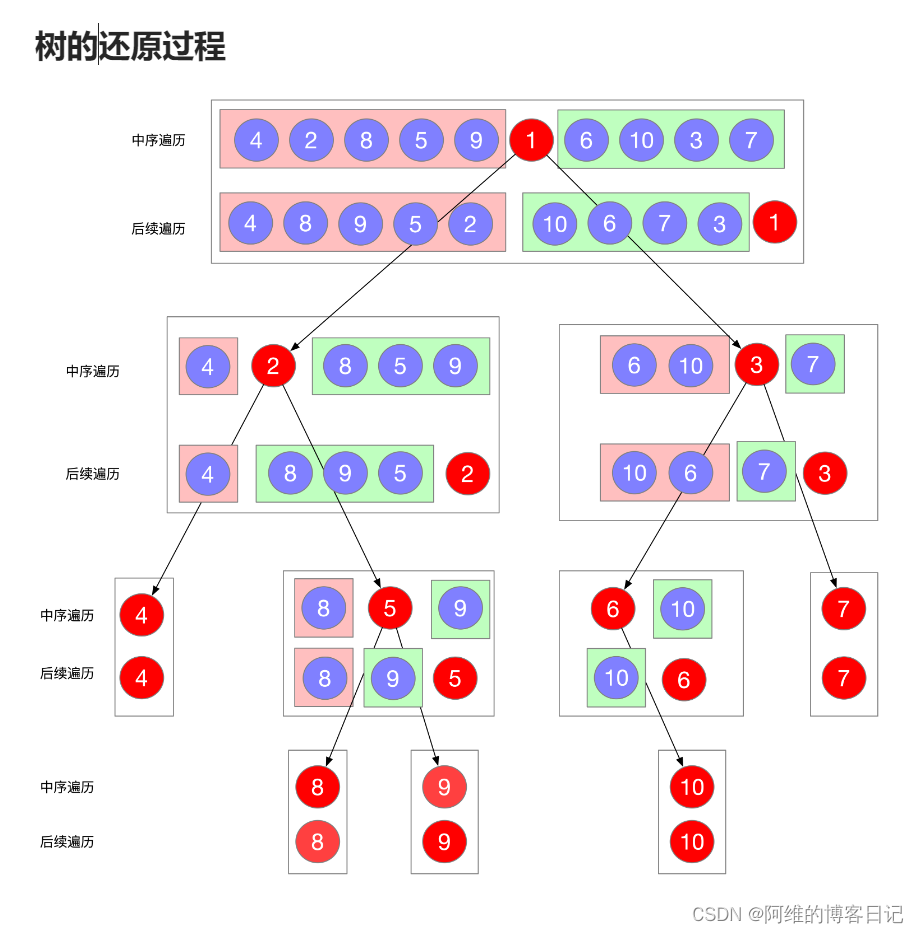
后序遍历序列的最后一个元素一定是root节点,中序遍历序列里面,root左边的是左子树,root节点右边的是右子树,接着可以递归处理。
依次把数组分为
2.思路
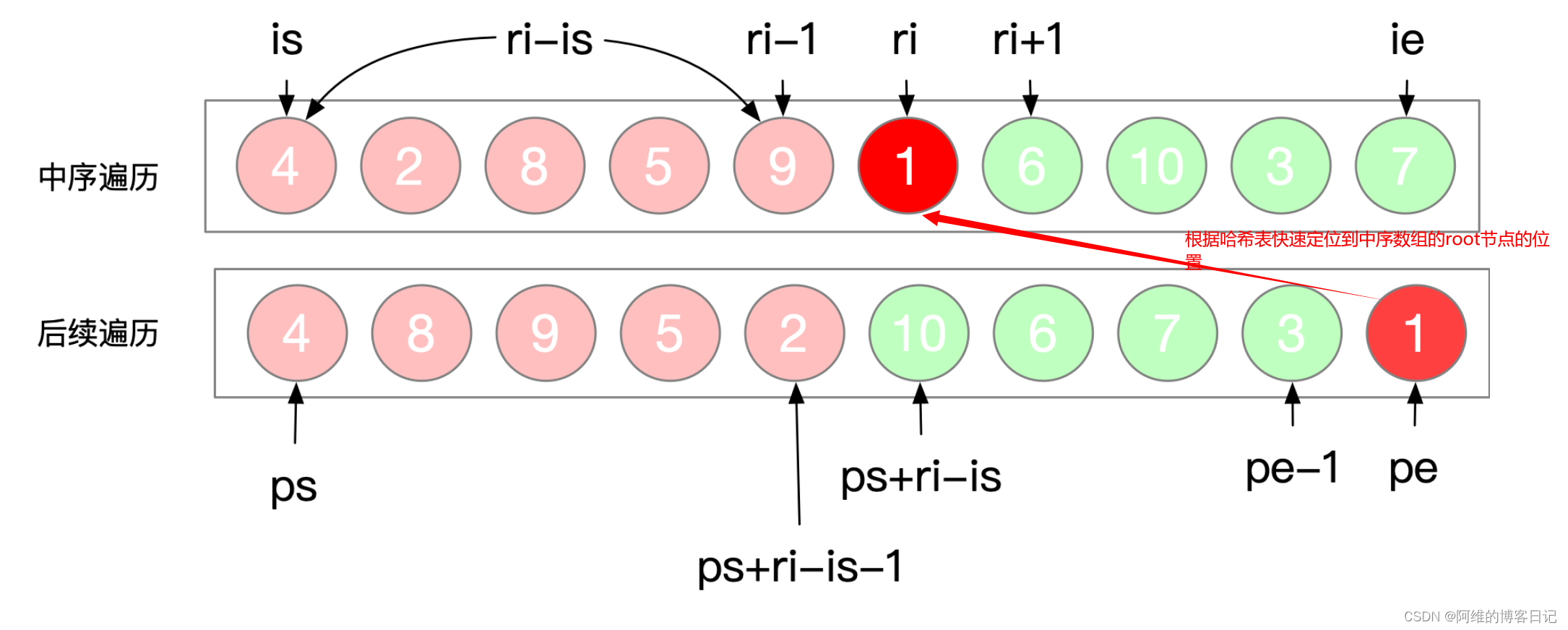
先使用哈希表记录整个中序序列的数组元素与下标的关系,目的是为了后续直接获取后序遍历序列vector最后一个元素之后直接得到中序里面的root节点的下标,加快算法速度!
3.变量名缩写与英文单词对应关系
| 变量名缩写 | 变量名单词 |
|---|---|
| is | inorder_start(中序遍历数组-起始下标) |
| ie | inorder_end(中序遍历数组-末尾下标) |
| ps | poster_start(后序遍历数组-起始下标) |
| pe | poster_end(后序遍历数组-末尾下标) |
| ri | root_index(根节点的下标) |
4.算法思路图解
5.代码
class Solution {
public:unordered_map<int,int> map;vector<int>* post;TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) { for(int i=0;i<inorder.size();++i){map[inorder[i]]=i;}post=&postorder;TreeNode* root=dfs(0,inorder.size()-1,0,post->size()-1);return root;}TreeNode* dfs(int is,int ie,int ps,int pe){if(ie<is||pe<ps){return nullptr;}int root = (*post)[pe];int ri=map[root];TreeNode* node=new TreeNode(root);node->left=dfs(is,ri-1,ps,ri-is-1+ps);node->right=dfs(ri+1,ie,ri-is+ps,pe-1);return node;}
};
这篇关于leetcode106从中序与后序遍历序列构造二叉树的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





