本文主要是介绍目标检测——PP-YOLOE算法解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PP-YOLO系列,均是基于百度自研PaddlePaddle深度学习框架发布的算法,2020年基于YOLOv3改进发布PP-YOLO,2021年发布PP-YOLOv2和移动端检测算法PP-PicoDet,2022年发布PP-YOLOE和PP-YOLOE-R。由于均是一个系列,所以放一起解读,方便对比前后改进地方。
PP-YOLO系列算法解读:
- PP-YOLO算法解读
- PP-YOLOv2算法解读
- PP-PicoDet算法解读
- PP-YOLOE算法解读
YOLO系列算法解读:
- YOLOv1通俗易懂版解读
- SSD算法解读
- YOLOv2算法解读
- YOLOv3算法解读
- YOLOv4算法解读
- YOLOv5算法解读
文章目录
- 1、算法概述
- 2、PP-YOLOE细节
- 3、实验
PP-YOLOE(2022.3.30)
论文:PP-YOLOE: An evolved version of YOLO
作者:Shangliang Xu, Xinxin Wang, Wenyu Lv, Qinyao Chang, Cheng Cui, Kaipeng Deng, Guanzhong Wang, Qingqing Dang, Shengyu Wei, Yuning Du, Baohua Lai
链接:https://arxiv.org/abs/2203.16250
代码:https://github.com/PaddlePaddle/PaddleDetection
1、算法概述
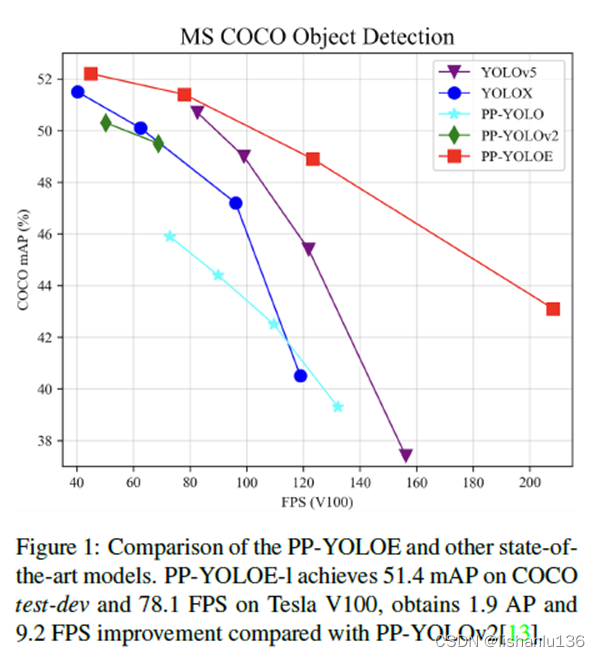
基于PP-YOLOv2进行改进,PP-YOLOE是一个anchor-free算法(受到YOLOX算法影响),用了更强的backbone,带CSPRepResStage的neck和ET-head,并且利用了TAL标签分配算法。为了更好的适配各种硬件平台,PP-YOLOE避免使用可变形卷积和Matrix NMS,而且PP-YOLOE提供s/m/l/x四个版本的网络模型以适应各个平台应用。PP-YOLOE-l在Tesla V100平台上实现了COCO test-dev集51.4%mAP和78.1FPS。若是将模型转换为TensorRT并且以FP16精度进行推理,可实现149.2FPS。与现如今最新算法的对比情况如下图所示:
2、PP-YOLOE细节
PP-YOLOE的整个网络框架如下所示,整个算法是anchor-free的,主干部分为CSPRepResNet,neck部分为PAN,head部分为ET-head(Efficient Task-aligned head)。
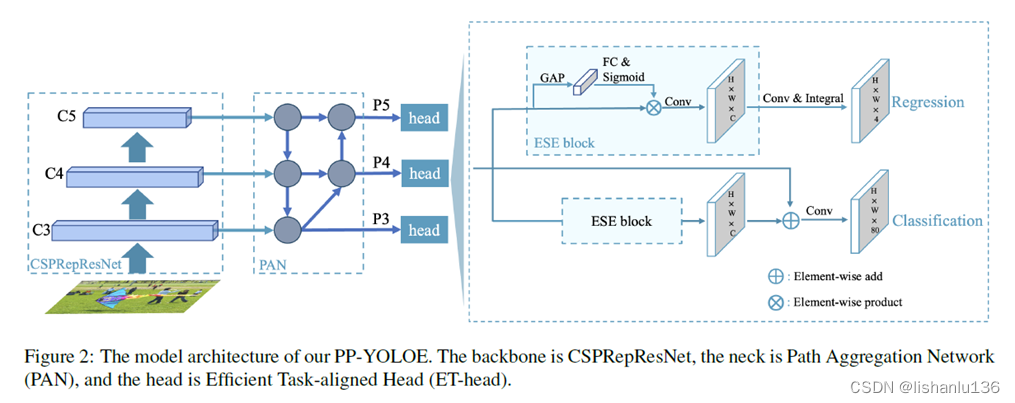
改进的地方:
- Anchor-free: 受到FCOS[1]算法的启发,PP-YOLOE将PP-YOLOv2的标签匹配规则替换为了anchor-free,这种改进使得模型更快但是掉了0.3%mAP。
- Backbone和Neck: 受到YOLOv5[2]和YOLOX[3]等网络借鉴CSPNet[4]带来的提升效果,作者也在backbone和neck中应用了RepResBlock。其结构如下图所示:
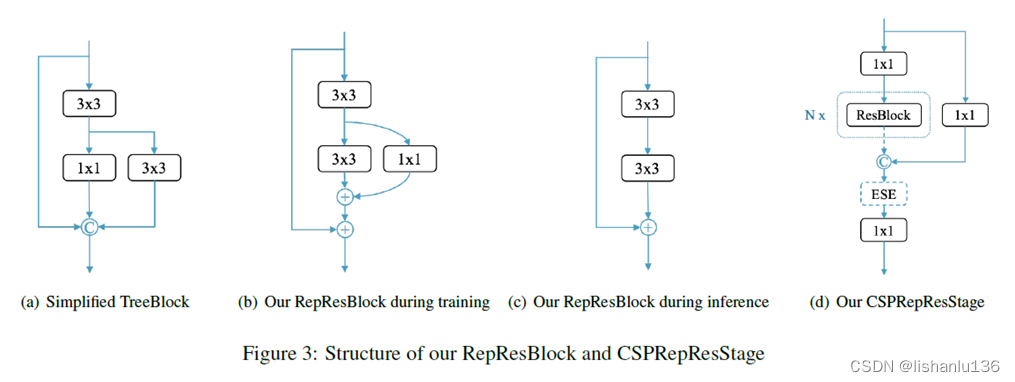
图(a)是TreeNet中的TreeBlock结构,图(b)是本文中RepResBlock在训练阶段的结构,图©是RepResBlock在推理阶段的结构,即该模块被重参数化后的样子,这来源于RepVGG[5],图(d)是CSPRepResStage的结构,将CSP与RepResBlock结合就是CSPRepResStage,作者将其应用在Backbone中,neck部分是RepResBlock和CSPRepResStage混合用的。
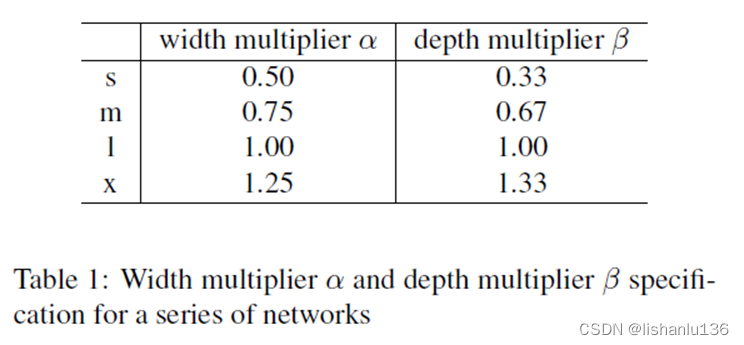
除此之外,作者根据网络宽度和深度设置不同比例得到不同规模的网络结构s/m/l/x,如下表:
- 任务一致性学习(Task Alignment Learning, TAL): YOLOX采用SimOTA来作为标签分配策略,为了进一步克服分类与定位的错位,TOOD[6]提出了任务一致性学习(TAL),它由动态标签分配和任务对齐损失组成的。多态标签分配意味着预测和当前损失是相关的,根据预测,为每个真值标签动态调整分配的正锚点个数。
通过显式地对齐这两个任务,TAL可以同时获得最高的分类分数和最精确的边界框。TAL示意图如下(图片来自TOOD论文):
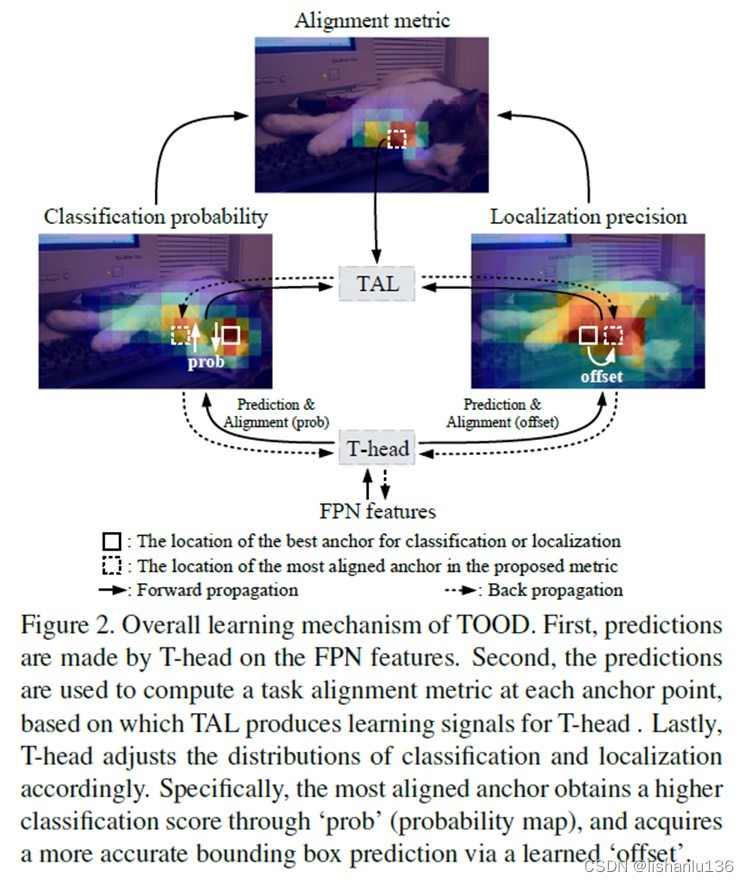
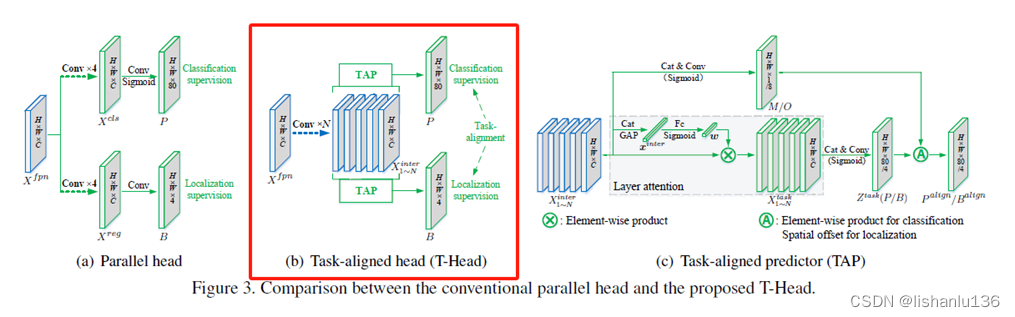
- 高效的任务一致检测头(Efficient Task-aligned Head, ET-head): YOLOX的方法,解耦头部提升了检测器性能,但解耦的头部可能会使分类和定位任务分离和独立,缺乏针对任务的学习。作者使用ESE模块来代替TOOD中的层注意力,TOOD论文提出的T-Head结构如下所示,详细结构见上面PP-YOLOE网络细节。
3、实验
与现如今最新检测算法在COCO2017 test-dev上的结果比较如下表所示:
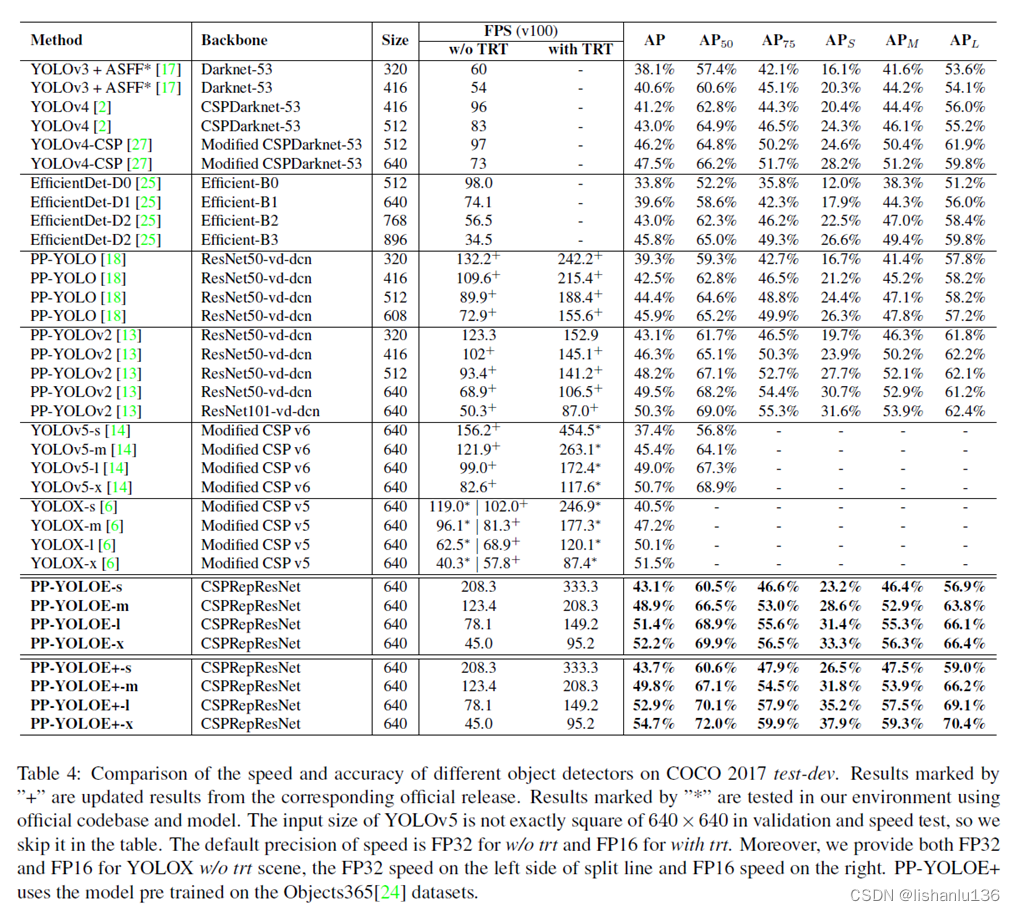
从表中可以看出,相同图片输入尺寸下,PP-YOLOE算法的AP指标要好于YOLOv5和YOLOX,且在没转TensorRT情况下速度相当,在转为TensorRT情况下,YOLOv5的FPS稍快,PP-YOLOE居中,YOLOX最慢。
参考文献:
[1] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9627–9636, 2019.2
[2] Glenn Jocher, Ayush Chaurasia, Alex Stoken, Jirka Borovec, NanoCode012, Yonghye Kwon, TaoXie, Jiacong Fang, imyhxy, Kalen Michael, Lorna, Abhiram V, Diego Montes, Jebastin Nadar, Laughing, tkianai, yxNONG, Piotr Skalski, Zhiqiang Wang, Adam Hogan, Cristi Fati, Lorenzo Mammana, AlexWang1900, Deep Patel, Ding Yiwei, Felix You, Jan Hajek, Laurentiu Diaconu, and Mai Thanh Minh. ultralytics/yolov5: v6.1 - TensorRT, TensorFlow Edge TPU and OpenVINO Export and Inference, Feb. 2022. 1, 2, 4, 5
[3] Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430, 2021. 1, 2, 4, 5
[4] Chien-Yao Wang, Hong-Yuan Mark Liao, Yueh-Hua Wu, Ping-Yang Chen, Jun-Wei Hsieh, and I-Hau Yeh. Cspnet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 390–391, 2020. 2
[5] Xiaohan Ding, Xiangyu Zhang, Ningning Ma, Jungong Han, Guiguang Ding, and Jian Sun. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13733–13742, 2021. 2
[6] Chengjian Feng, Yujie Zhong, Yu Gao, Matthew R Scott, and Weilin Huang. Tood: Task-aligned one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3510–3519, 2021. 3, 4
这篇关于目标检测——PP-YOLOE算法解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








