本文主要是介绍python爬虫scrapy框架,对于智联招聘职位进行抓取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
源码下载:http://download.csdn.net/download/adam_zs/10166296
1.先看项目结构和mongodb保存的职位结果
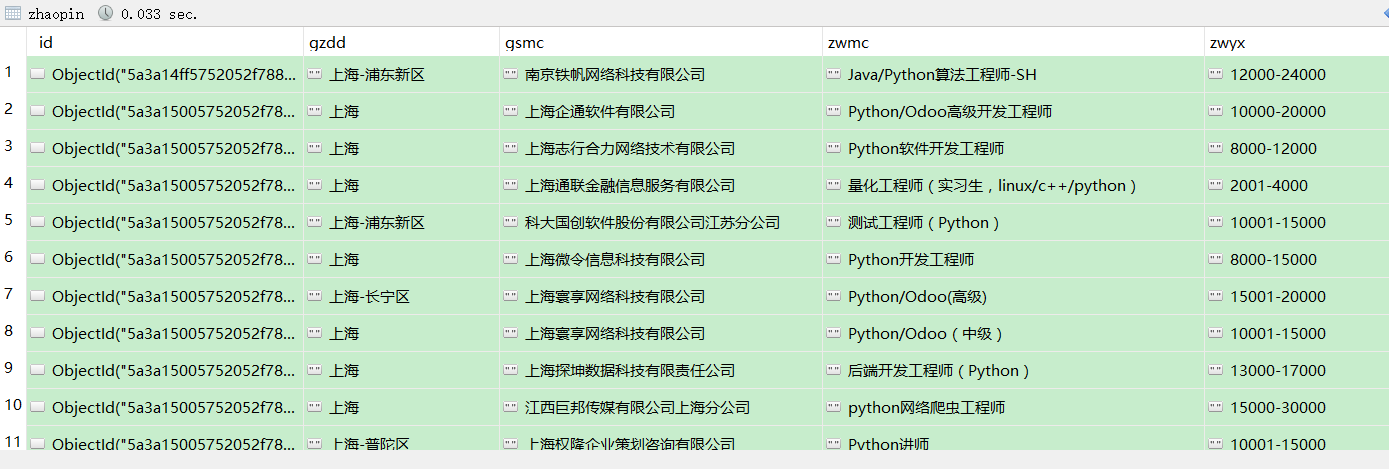
2.项目介绍
在爬虫中设置爬取首页,并自动爬取下一页: 首页:http://sou.zhaopin.com/jobs/searchresult.ashx?kw=python&p=1 下一页:next_page = "http://sou.zhaopin.com/jobs/searchresult.ashx?kw=python&p=" + str(self.page_num)
下一页:next_page = "http://sou.zhaopin.com/jobs/searchresult.ashx?kw=python&p=" + str(self.page_num)
class DmozSpider(scrapy.Spider):def __init__(self):self.page_num = 1name = "zhaopin"allowed_domains = ["zhaopin.com"]start_urls = ["http://sou.zhaopin.com/jobs/searchresult.ashx?kw=python&p=1"]def parse(self, response):table_list = response.xpath('//table[@class="newlist"]')for table in table_list:zwmc = table.xpath('string(.//td[@class="zwmc"]//a[1])').extract() # 职位名称gsmc = table.xpath('.//td[@class="gsmc"]/a//text()').extract() # 公司名称zwyx = table.xpath('.//td[@class="zwyx"]//text()').extract() # 职位月薪gzdd = table.xpath('.//td[@class="gzdd"]//text()').extract() # 工作地点item = ZhaopinspiderItem(zwmc=zwmc, gsmc=gsmc, zwyx=zwyx, gzdd=gzdd)yield itemself.page_num = self.page_num + 1next_page = "http://sou.zhaopin.com/jobs/searchresult.ashx?kw=python&p=" + str(self.page_num)print("******next_page******" + next_page)if next_page:yield scrapy.Request(url=next_page, callback=self.parse)数据清理Pipeline,清理职位中不包括python的职位
class DataCleaningPipeline(object):def process_item(self, item, spider):zwmc = ''.join(item['zwmc'])if "PYTHON" in zwmc.upper():return itemelse:raise DropItem("Missing zwmc in %s" % item)把爬取的数据保存入mongodb数据库
from pymongo import MongoClientsettings = {"ip": "172.28.34.xxx", # ip"port": 27117, # 端口"db_name": "wangzs", # 数据库名字"set_name": "zhaopin" # 集合名字
}# 数据保存
class MongoWriterPipeline(object):def __init__(self):try:self.conn = MongoClient(settings["ip"], settings["port"])except Exception as e:print(e)self.db = self.conn[settings["db_name"]]self.my_set = self.db[settings["set_name"]]def process_item(self, item, spider):mongo = MongoWriterPipeline()mongo.my_set.insert({"zwmc": item["zwmc"][0], "gsmc": item["gsmc"][0], "zwyx": item["zwyx"][0], "gzdd": item["gzdd"][0]})return item配置USER_AGENT
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
import randomclass MyUserAgentMiddleware(UserAgentMiddleware):'''设置User-Agent'''def __init__(self, user_agent):self.user_agent = user_agent@classmethoddef from_crawler(cls, crawler): # 用于访问相关的设置信息return cls(user_agent=crawler.settings.get('MY_USER_AGENT'))def process_request(self, request, spider):agent = random.choice(self.user_agent)request.headers['User-Agent'] = agentDOWNLOADER_MIDDLEWARES = {'scrapy.downloadermiddleware.useragent.UserAgentMiddleware': None,'zhaopinSpider.middlewares.MyUserAgentMiddleware': 400,
}MY_USER_AGENT = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)","Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)","Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)","Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)","Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)","Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6","Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0","Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5","Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20","Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)","Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1","Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5","Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre","Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11","Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",]3.启动项目
pycharm中运行begin.py
from scrapy import cmdline# cmdline.execute("scrapy crawl dmoz".split())cmdline.execute("scrapy crawl zhaopin".split())这篇关于python爬虫scrapy框架,对于智联招聘职位进行抓取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





