本文主要是介绍CBCC3 – A CBCC Algorithm with Improved Exploration/Exploitation Balance,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0、论文背景
本文是在CBCC1和CBCC2的基础上提出了CBCC3。在本文中,证明了过度探索和过度开发是现有CBCC变体中性能损失的两个主要来源。在此基础上,提出了一种新的基于贡献的算法,可以在探索和开发之间保持更好的平衡。
Omidvar M N, Kazimipour B, Li X, et al. CBCC3—A contribution-based cooperative co-evolutionary algorithm with improved exploration/exploitation balance[C]//2016 IEEE congress on evolutionary computation (CEC). IEEE, 2016: 3541-3548.
1、CBCC存在的问题
有关CBCC 请参照博客:CBCC。
- 在一些情况下,CBCC2未能切换到另一个刚刚成为最具贡献的组件的组件。当所选组件的目标值低于其他组件的目标值时,CBCC应该停止优化该组件,以便给其他组件提供一个机会。
- 一个部分的主导地位,通过探索阶段(第一阶段)的资源平等分配,浪费了大量的客观函数评价。
一般来说,CBCC1和CBCC2的两个主要缺点可以总结如下:
- CBCC对适应度值的局部变化的反应缓慢,以及它对进化早期阶段积累的信息的强烈依赖。这在CBCC2中更为明显。
- 通过在算法中频繁地应用探索阶段来进行过度的探索。
2、CBCC3
CBCC3的另一个主要区别是它依赖于最近的贡献信息来选择一个组件进行进一步优化(消除了CBCC1和CBCC2中对历史信息的使用)。

C1是与组件相关的最大贡献,而C2是与组件相关的第二大贡献。
3、实验分析
CBCC因为未能切换到另一个刚刚成为最具贡献的组件的组件,所以导致组件的过度开发:

而导致其他组件没有获得相对应的进一步优化的资源。而CBCC3有效地解决了这一点:
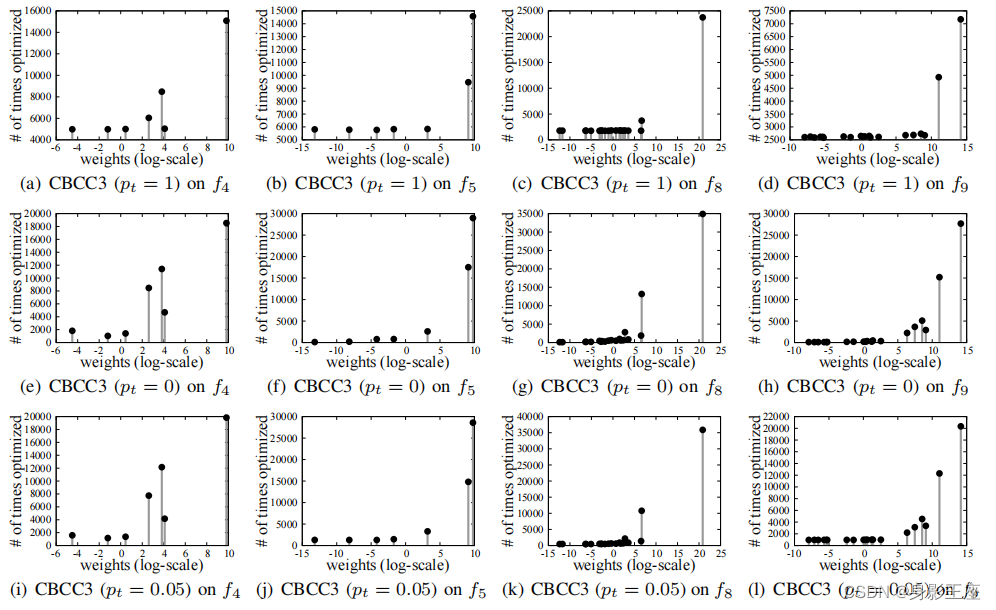
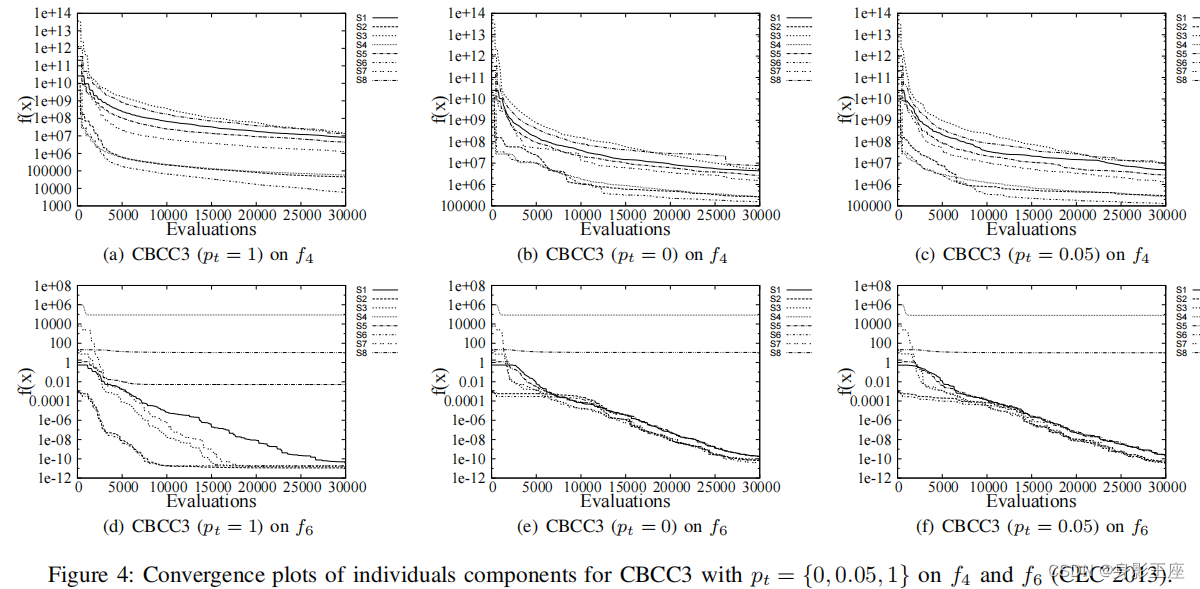
然后将DECC、CBCC与CBCC3进行对比实验:
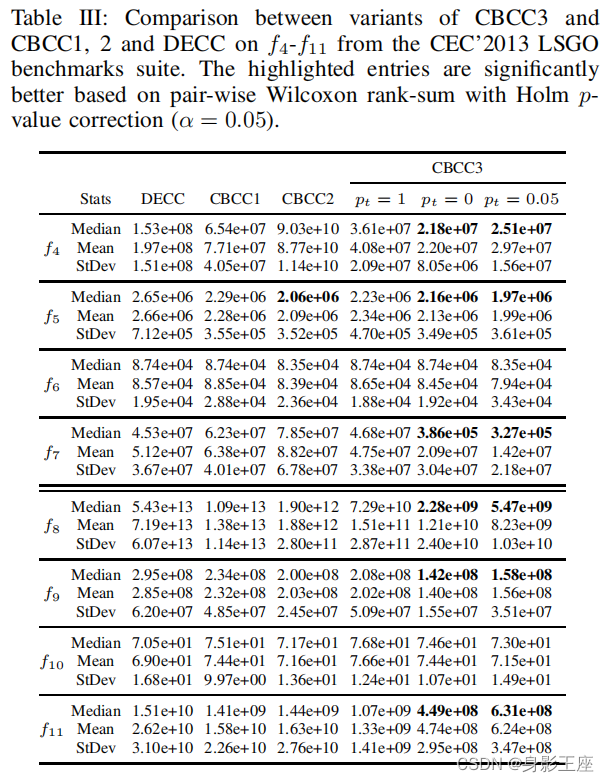
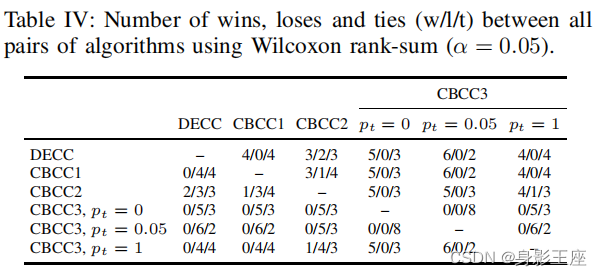
4、算法复现
clc; clearvars; close all;
addpath('LSGO2013\')
addpath('LSGO2013\datafiles\');
load 'f07.mat';
global initial_flagNS = 50; % 种群数
dim = 1000; % 种群维度
upperBound = ub;
lowerBound = lb;
bestYhistory = []; % 保存每次迭代的最佳值
trueGroup = [50, 25, 25, 100, 50, 25, 25, 700];for funcNum = 7initial_flag = 0; % 换一个函数initial_flag重置为0sampleX = lhsdesign(NS, dim) .* (upperBound - lowerBound) + lowerBound .* ones(NS, dim); % 生成NS个种群,并获得其评估值sampleY = benchmark_func(sampleX', funcNum);sampleY = sampleY'; % 每一列是一个种群[bestY, bestIndex] = min(sampleY); % 获取全局最小值以及对应的种群lastBestY = bestY;bestX = sampleX(bestIndex, :);bestYhistory = [bestYhistory; bestY];evalue = 50;allGroups = {}; % 理想分组s1 = size(trueGroup, 2);for i0 = 1 : s1if i0 == 1start = 1;elsestart = start + trueGroup(i0 - 1);endendstart = start + trueGroup(i0) - 1;allGroups{end + 1} = p(1, start : endstart);enddeltaF = zeros(1, s1);version = 2;pt = 0.05;while evalue < 3 * 10 ^ 6 if evalue == 50 || rand() < ptfor i1 = 1 : s1index1 = allGroups{i1};dim1 = size(index1, 2);subX = sampleX(:, index1);subX = SaNSDE(subX, sampleY, bestX, index1, 100, dim1, lowerBound, upperBound, @(x)benchmark_func(x, funcNum));sampleX(:, index1) = subX;sampleY = benchmark_func(sampleX', funcNum);sampleY = sampleY';[bestY, bestIndex] = min(sampleY); % 获取全局最小值以及对应的种群bestX = sampleX(bestIndex, :);if (lastBestY - bestY) ~= 0deltaF(1, i1) = lastBestY - bestY;endlastBestY = bestY;evalue = evalue + 50 * 100;endenddeltaF1 = deltaF;[~, index2] = sort(deltaF1,'descend');c1 = index2(1);c2 = index2(2);while deltaF(c1) > deltaF(c2) && evalue < 3 * 10 ^ 6index1 = allGroups{c1};dim1 = size(index1, 2);subX = sampleX(:, index1);subX = SaNSDE(subX, sampleY, bestX, index1, 100, dim1, lowerBound, upperBound, @(x)benchmark_func(x, funcNum));sampleX(:, index1) = subX;sampleY = benchmark_func(sampleX', funcNum); sampleY = sampleY';[bestY, bestIndex] = min(sampleY); % 获取全局最小值以及对应的种群bestX = sampleX(bestIndex, :);if (lastBestY - bestY) ~= 0deltaF(c1) = lastBestY - bestY;endlastBestY = bestY;evalue = evalue + 50 * 100;disp(evalue);disp(bestY);endbestYhistory = [bestYhistory; bestY];disp(evalue);end
end
plot(bestYhistory);
save('CCBC3DG.mat','bestYhistory');
legend('Y','Location', 'northeast');fminCBCC: 7021576.99155833
fminCBCC3:1.347210239771024e+05
这篇关于CBCC3 – A CBCC Algorithm with Improved Exploration/Exploitation Balance的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![[Algorithm][综合训练][栈和排序][加减]详细讲解](https://i-blog.csdnimg.cn/direct/7df413c28a644b6097dcfa5df3fb027c.png)
![[Algorithm][综合训练][四个选项][接雨水]详细讲解](https://i-blog.csdnimg.cn/direct/9e062d23fecc4cdc937d86b7f56aad5b.png)


