本文主要是介绍关于SRE,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
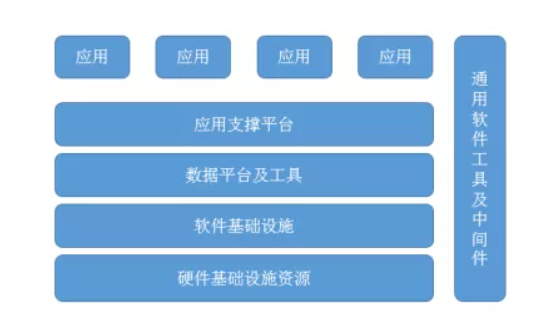
SRE(Site Reliability Engineering)是一种由Google提出的运维工程师团队的方法论。SRE的目标是通过将软件工程的原则和实践应用于运维工作,来提高系统的可靠性和可扩展性。SRE强调自动化、监控、故障处理和容量规划等方面的工作,以确保系统的稳定性和可用性。
SRE方法论关注以下几个方面:
1、可靠性工程:SRE团队致力于提高系统的可靠性,通过自动化和监控来减少人为错误,并通过故障处理来快速恢复系统。
2、容量规划:SRE团队负责系统的容量规划,确保系统能够满足用户的需求,并在需要时进行扩容。
3、故障处理:SRE团队通过故障注入和故障演练等方式来测试系统的弹性和恢复能力,并通过故障分析来改进系统的可靠性。
4、监控和警报:SRE团队建立监控系统来实时监测系统的状态,并设置警报来及时发现和解决问题。
5、自动化:SRE团队通过自动化工具和流程来减少手动操作,提高效率和可靠性。
总结起来,SRE是一种将软件工程的原则和实践应用于运维工作的方法论,旨在提高系统的可靠性和可扩展性。它强调自动化、监控、故障处理和容量规划等方面的工作,以确保系统的稳定性和可用性。
这篇关于关于SRE的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!