本文主要是介绍职业探索--运维体系-SRE岗位/CRE岗位/运维岗位-服务心态-运维职业发展方向-运维对象和运维场景,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考来源:
极客时间专栏:赵成的运维体系管理课
极客时间专栏:全栈工程师修炼指南
赵成大佬在鹏讯云社区的文章(77篇)
有了CMDB,为什么还要应用配置管理
故障没有根因,别再找了
如何理解CMDB的套路
故障复盘的简洁框架-黄金三问
数据中心运维管理方案(超详细)–数据中心场景的运维工作场景
https://www.uwintech.cn/2 --EasyOps一站式运维平台,关于运维专业化公司(优维科技)的介绍
关于 SRE 这个角色,你可以参看 Google 自己的描述,以及 SRE 这个词条
运维的组织架构
从实际的人员管理以及技能维度来划分的话,互联网公司的运维团队差别不大,基本会分为如下几个岗位:
基础运维,包括 IDC 运维、硬件运维、系统运维以及网络运维;
应用运维,主要是业务和基础服务层面的稳定性保障和容量规划等工作;
数据运维,包括数据库、缓存以及大数据的运维;
运维开发,主要是提供效率和稳定性层面的工具开发。
这个实体的组织架构,相当于是从技能层面的垂直划分。
基础运维更擅长硬件和操作系统层面的运维;
应用运维可能更擅长业务稳定性保障、疑难问题攻关以及技术运营等;
数据运维就不用多说了,DBA 本身就是专业性极高的一个岗位;
运维开发则是支持上述几个岗位日常运维需求的,是否能将人力投入转换成工具平台支持,就看这个团队的能力。
SRE岗位
书籍:《SRE:Google 运维解密》
SRE 关注的目标不是 Operation(运维),而是 Engineering(工程),是一个“通过软件工程的方式开发自动化系统来替代重复和手工操作”的岗位。我们从 SRE 这本书的前面几个章节,可以看到谷歌不断强调 SRE 的工程能力。
书中对 SRE 的职责定义比较明确,负责可用性、时延、性能、效率、变更管理、监控、应急响应和容量管理等相关的工作。如果站在价值呈现的角度,我觉得可以用两个词来总结,就是“效率”和“稳定”。
SRE 的能力模型,不仅仅是技术上的,还有产品设计、标准规范制定、事后复盘总结归纳这些技术运营能力,同时还需要良好的沟通协作能力,这个就属于职场软技能。
SRE,直译过来是网站稳定性工程师。表面看是做稳定的,但是我觉得更好的一种理解方式是,以稳定性为目标,围绕着稳定这个核心,负责可用性、时延、性能、效率、变更管理、监控、应急响应和容量管理等相关的工作。
分解一下,这里主要有“管理”和“技术”两方面的事情要做。
管理体系上,涉及服务质量指标(SLI、SLA、SLO)、发布规则、变更规则、应急响应机制、On-Call、事后复盘机制等一系列配套的管理规范和标准制定等。
技术体系上,以支持和实现上述标准和规范为目标,涉及自动化、发布、监控、问题定位、容量定位,最终以电子流程串联各个环节,做到事件的闭环。
–
SRE(Site Reliability Engineer,网站可靠性工程师),这个角色最早很可能是 Google创造出来的,从名称上也可以看出,这个职位的工程师所致力于解决的问题,就是网站可靠性的问题,这里的“可靠性”,包括可用性、延迟、容量等多个方面。
在“时间就是金钱”的压力环境下,严谨而大胆,快速定位和解决问题,但更重要的是,帮助不同的团队“防患于未然”,比如主导和把关新建服务的可靠性设计。SRE 有时要解决基础设施的问题,有时要分析服务端的压力来源,有时则要搞定网页上造成大量用户访问困难的“小 bug”。很显然,一个狭窄领域知识的工程师,是不可能胜任这样的岗位的,对于从端到端俯瞰整个流程的能力,Web 全栈工程师有着天然的优势。
CRE 岗位
CRE(Customer Reliability Engineering),直译过来就是客户稳定性工程师。
CRE 出现的根本目的,就是消除客户焦虑,真正地站在客户的角度去解决问题,同时对客户进行安抚、陪伴和关怀。
通常的售后支持,都是你问什么问题,我就回答什么问题,能马上解决的就马上解决,不能解决的就转到后端处理,然后让客户等着,承诺多长时间内给出答复。这种流程标准,严格执行 SLA 规范,对于一般问题还好,但要是真的出现大问题就不行了。
CRE 这个角色一定是站在客户角度解决问题。加入客户的“作战室”(War Room),和客户一起排查,问题不解决,自己不撤退;还会随时通报进展,必要的时候会将故障升级到更高的级别,寻求更专业的资源投入以共同解决;同时根据客户的不同反应进
行不同方式的安抚。
CRE 还会发挥谷歌多年积累下来的非常宝贵的线上运维经验,在日常就跟客户沟通传递一些稳定性保障的知识。
CRE 可以按照谷歌总结出来的类似 SRE 的标准规范,对客户线上系统进行稳定性标准评审,并给出专业的建议。如果客户同意遵守这样的标准规范执行,在后续出现故障时,CRE 就完全可以按照非常成熟的 SRE 的运作模式去协作用户处理故障,这样就会大大提升 CRE 和客户的协作效率,为故障快速处理赢得更多宝贵时间。同时 CRE 也可以发挥更大的专业作用,而不是之前的对客户系统不熟悉,空有一身绝世武功,却使不上劲。
服务心态
总结了一下,是不是有服务心态,表现在我们的做事方式上,就是我们是否能够站在对方的角度考虑问题、解决问题。
1. 多使用业务术语,少使用技术术语
与合作部门沟通协作,特别是对于非技术类的业务部门,尽量多使用业务语言来表达。在讨论一个需求时,如果表达的都是 API、缓存、数据库、消息队列等等这些专业术语,估计业务部门的同学肯定是跟不上我们的思路的,这样的沟通通常无法正常地进行下去,所以就会
经常出现业务同学说业务的事情,技术同学说技术的事情,两边不能达成一致,矛盾就产生了。
技术是实现业务功能的一种手段和方式,所以一定是从业务角度出发考虑技术解决方案,而不是从技术角度出发让业务来适配技术。
尝试用业务语言去沟通,用对方能够听得懂的表达方式去表达你的技术观点。为了让业务人员理解你的想法,就自然会用业务的思路去思考和解决问题了。这个需要一点点改变,可以先从尝试开始。
2. 学会挖掘问题背后的真正诉求
外部提出的一个问题,可能并不一定是真正的问题,而是问题的一个解决方案。
遇到类似问题,可以不着急动手做,先多问自己和对方几个问题,比如:
为什么要这样做?
谁要求做这件事情的?
这样做的目的是什么?
这样做是为了解决什么问题?
这一点其实也是站在对方角度去考虑,去思考对方要解决的问题是什么,而不是解决我们的问题。通常情况下,两三个问题后,一般就会暴露出背后最原始的那个需求了。正所谓“磨刀不误砍柴工”,问题和背景搞清楚了,思路和方案就是顺其自然的事情了。
3. 解决问题的时候关注目标,而不是聚焦困难
两种不同的思考问题的方式,带给人的感受也是完全不一样的。
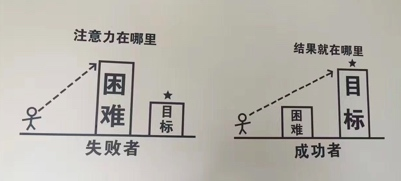
随着云计算技术的深入发展,公有云事业也不断拓展,运维领域的分工也在不断地精分细化,而每个细分领域对专业技术的要求也越来越高,专业的服务化程度也越来越高。我想这是一个好现象,让原来非常模糊的运维行业范畴变得越来越清晰、越来越具体。
一方面我们要不断提升自己的技术能力,另一方面也要注意自身服务意识的培养,让自己的能力得以发挥,创造更大的价值,获得更好的回报。
所以,CRE 这个角色,既具备良好的专业技术能力,又有非常强的问题解决能力,同时还要具有优秀的客户沟通和关怀能力。
运维职业发展方向
1.一线维护
这个团队是负责产品的交付服务和后续的客户服务工作。从技能上,很像传统运维,主要是对网络设备、硬件主机和操作系统层面要熟练。一方面要负责交付的项目管理;另一方面,也是非常重要的一点,要对一线客户满意度负责,也就是客户反馈的所有问题,甚至是客户工作中表现出来的喜怒哀乐都要关注。
一线维护,最重要的就是必须要有非常强的服务意识。
2.二线技术支持
因为一线维护面对的是单个具体的运营商,在遇到一些问题的时候,往往没有经验,但是二线因为要面对某个产品全球的局点问题,所以在经验上更容易沉淀和积累。当某个一线团队遇到没有经验的问题时,二线有可能就可以很快很好地帮忙解决,而不用直接透传到三线。
同时,二线还要做好统筹协调,因为一线过来的问题不仅仅是产品本身问题,也可能是网络设备、硬件、操作系统、存储甚至数据库等的问题,这就需要二线帮助一线协调专家资源进行处理,而不是一线再一个个找人,这时一线只管反馈问题即可。
二线技术支持,大多由产品研发或者一线维护经验的人员抽调上来的,即使没有这些经验,也要下放到一线去锻炼很长时间,两三年都有可能,所以技术和经验上都相对更加全面,同时能够有较强的推进协调能力。
3.三线研发维优
到了三线就是研发团队中的运维团队了,这个团队在华为叫做维优团队。这个团队就很牛了,一般都是从开发骨干精挑细选出来的,一方面是为了锻炼人,另一方面也是为了在出现问题时,能够有最专业、能力最强的人响应处理,因为电信级业务是国计民生的基础设施,
一般传递到三线的问题,都是比较严重或者疑难的了,必须投入精兵强将第一时间解决问题。
处理问题的过程中,还会不断完善工具体系,提升日常维护和问题定位的效率。因为三线同样要面对全球局点问题,所以 7*24 响应,而且常年无休,比我们现在互联网运维的工作负荷要大得多,所以这个团队成员一般做个 1~2 年就会转岗晋升,不然身体肯定是承受不住的。
三线研发维优,这个团队的成员就像军队中的突击队或尖刀连一样,总是冲在最前面,在高压状态下,解决最复杂、最棘手的问题,所以从选拔阶段,就有非常高的要求。最终经过这个团队磨练出来的人,技术能力、沟通协作能力以及全面解决问题的能力,都是非常突出的。自然地,在晋升发展方面就会有更大竞争优势。
这里我们不做过多发散,理解下来就是谁离客户最近,谁对客户负责,谁就能代表客户,谁就有最大的话语权,甚至是指挥权和决策权。体现在上述我们所说的运维机制上,就是:一线的声音,代表了客户声音;一线反馈到二线的问题,二线必须响应;二线传递到三线的问
题,三线必须响应。
客户第一
当然,问题级别不同,响应效率可以不同。同时,三线可以根据客户现场情况,以及问题严重程度,对问题进行升级,以知会到更高层级的主管进行关注。
在考核上,如果一线提交的问题,最终被定性为二线支持问题,或者三线研发质量问题,那二、三线的全年考核将会受到影响,如果是频繁出现问题,那就会受到严重影响,而且各级主管要承担连带责任。
这套机制的根本目的,还是为了促进整个体系能够以尽快解决问题、提升软件质量为目标。整个团队树立起这样的观念,就自然会对质量和问题有敬畏感,研发维优那个时候大多都是远程电话与一、二线沟通,潜意识里就会把一、二线作为他们的客户,同样保持谦卑和尊重。
从价值呈现的角度看运维岗位
运维能力的体现,一定是整体技术架构能力的体现。所以,要想做好运维就一定要跳出运维这个框框,从全局的角度来看
运维,要考虑如何打造和体现出整个技术架构的运维能力,而不是运维的运维能力。这一点是根本,一定要注意。如果我们仍然片面地从运维的角度看运维,片面地从运维的角度规划运维,是无法走出运维低价值的困局的。
当我改变了这个认知后,我的出发点就回归到了效率、稳定和成本这三个对于研发团队来说最重要的目标上来。从运维的角度来说,能够与这三个点契合的事情,我总结了以下五个。
1. 运维基础平台体系建设
这块主要包括我们前面提到的标准化体系以及 CMDB、应用配置管理、DNS 域名管理、资源管理等偏向运维自身体系的建设。这一部分是运维的基础和核心,我们前面讲到的标准化以及应用体系建设都属于这个范畴。
2. 分布式中间件的服务化建设
在整个技术架构体系中,分布式中间件基础服务这一块起到了支撑作用。这一部分的标准化和服务化非常关键,特别是基于开源产品的二次开发或自研的中间件产品,更需要有对应的标准化和服务化建设。这也是我们无意识地割裂运维与技术架构行为的最典型部分,这里容
易出现的问题,我们前面讲过,你可以回去再复习一下。
3. 持续交付体系建设
持续交付体系是拉通运维和业务开发的关键纽带,是提升整个研发团队效率的关键部分。这个部分是整个软件或应用的生命周期的管理体系,包括从应用创建、研发阶段的持续集成,上线阶段的持续部署发布,再到线上运行阶段的各类资源服务扩容缩容等。开发和运维的矛
盾往往比较容易在这个过程中爆发出来,但是这个体系建设依赖上面两部分的基础,所以要整体去看。
4. 稳定性体系建设
软件系统线上的稳定性保障,包括如何快速发现线上问题、如何快速定位问题、如何快速从故障中恢复业务、如何有效评估系统容量等等。这里面还会有一些运作机制的建设,比如如何对故障应急响应、如何对故障进行有效管理、如何对故障复盘、如何加强日常演练等等。同样,这个环节的事情也要依赖前两个基础体系的建设。
5. 技术运营体系建设
技术运营体系也是偏运作机制方面的建设,最主要的事情就是确保我们制定的标准、指标、规则和流程能够有效落地。这里面有些可以通过技术平台来实现,有些就需要管理流程,有些还需要执行人的沟通协作这些软技能。
最终通过这样一个规划,我把团队以虚拟形式重新规划了不同职责,分别负责基础平台体系、分布式中间件服务化体系、持续交付体系和稳定性体系,基本就是上述的前四件事情。
对于最后一个技术运营体系,这一点作为共性要求提出。我要求团队每个成员都要具备技术运营意识。
具体来说,就是要能够有制定输出标准的意识和能力,
能够有规范流程制定的能力,同时能够将标准和流程固化到工具平台中,最后能够确保承载了标准和规范的平台落地,也就是平台必须可用,确实能给运维团队或开发团队带来效率和稳定性方面的提升。这些对个人的要求还是比较高的,要有一定的规划、设计和落地能力,能具备一整套能力的人还是少数,目前这块还是靠团队协作来执行。
这篇关于职业探索--运维体系-SRE岗位/CRE岗位/运维岗位-服务心态-运维职业发展方向-运维对象和运维场景的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


