本文主要是介绍Learning Actor Relation Graphs for Group Activity Recognition 论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一.了解ARG
- 二.为什么需要ARG
- 1.多人场景识别的问题
- 2.先前的方法
- 3.本文的方法
- 4.本文的三大贡献
- 三.ARG详细介绍
- 1.群体活动识别框架
- 2.构建ARG
- 2.1图的定义
- 2.2外观联系
- 2.3位置联系
- 2.4多重图(Multiple graphs)
- 2.5时间建模(Temporal modeling)
- 3.图的推理与训练
- 3.1推理
- 3.2训练
- 四.消融实验
- 1.外观联系
- 2.位置联系
- 3.多重图
- 4.时间建模
- 五.与其他技术的比较
一.了解ARG
ARG的全称是actor relation graphs,即动作者关系图。
在多人场景中,角色之间的关系建模对于识别群体活动非常重要。文章提出构建一个灵活高效的动作者关系图(ARG),以同时捕获动作者之间的外观和位置关系。借助于GCN(Graph Convolutional Network),ARG中的连接可以以端到端的方式从群体活动视频中自动学习,并且可以通过标准矩阵运算高效地进行ARG推理。此外,文章提出了两种稀疏ARG的变体,以便在视频中进行更有效的建模:空间局部ARG(spatially localized ARG)和时间随机ARG(temporal randomized ARG)。在两个数据集上进行实验:排球数据集和集体活动数据集,并且这两个数据集都实现了最先进的性能。
二.为什么需要ARG
1.多人场景识别的问题
为了理解多人场景,不仅需要知道每个参与者的个人行为,还要推断他们的集体活动。准确捕捉参与者之间的关系并进行关系推理,对于理解多人的群体活动至关重要。但是我们只能访问个人行动标签和集体活动标签,而不知道潜在的交互信息。
因此,外观相似性和相对位置(appearance similarity and relative location)至关重要。
2.先前的方法
- 首先,通过卷积神经网络(CNN)提取人物级(personlevel)特征。
- 然后,设计一个全局模块来进行聚合,以生成场景级(scenelevel)特征。此方法使用不灵活的图形模型对动作者之间的关系进行建模,其结构是事先手动指定的,或者使用复杂但不直观的消息传递机制。
- 为了捕获时间动态,循环神经网络 (RNN) 通常用于对密集采样帧的时间演化进行建模。
缺点:很高的计算成本,缺乏处理群体活动变化的灵活性
3.本文的方法

具体来说,通过构建动作者关系图(ARG)来建模参与者-参与者关系,如图所示,图中的节点表示动作者的特征,边表示两个动作者之间的关系。
优势:
- ARG可以很容易地放在任何现有的2D CNN之上,以形成一个统一的群体活动识别框架。
- 由于GCN,ARG中的连接可以以端到端的方式自动优化。
- 经过训练后,不仅可以识别多人场景中的个人动作和集体活动,还可以动态生成ARG
- 进一步提高ARG在视频中进行长程时间建模的效率,提出了两种稀疏ARG中连接的技术。
空间域:通过强制动作者之间的连接仅在局部邻域中来设计局部ARG。
时间域:不连接任何成对帧,而是通过随机丢弃几个帧并只保留几个帧来产生一个随机ARG。
随机丢弃操作不仅能够极大地提高建模效率,而且能够极大地增加训练样本的多样性,降低ARG的过拟合风险。 - 引入在一个动作者集上构造多个ARG,以使该模型能够关注动作者之间更加多样化的关系信息。
4.本文的三大贡献
- 构造了灵活高效的ARG,以同时捕获动作者之间的外观和位置关系,用于群体活动识别。
- 利用具有稀疏时间采样策略的GCN实现ARG。
- 在排球数据集和集体活动数据集这两个数据集上取得了最优的结果。
三.ARG详细介绍
通过利用关系信息来识别多人场景中的群体活动。为此,构建了动作者关系图(ARG)来表示多人场景,并对其进行关系推理以进行群体活动识别。

1.群体活动识别框架
- 首先,从视频中统一采样 K 帧。
- 采用 Inception-v3 为每帧提取多尺度特征图。
- 应用RoIAlign从帧特征图中提取每个动作者边界框的特征。
- 执行FC层,以获得每个动作者的 d 维外观特征向量。 K 帧中边界框的总数表示为 N。使用 N × d 矩阵 X 来表示动作者的特征向量。
- 根据动作者的这些原始特征,构建ARG,其中每个节点表示一个动作者。 图中的每条边都是一个标量,它是根据两个动作者的外表特征和他们的相对位置计算出来的。 为了表示不同的关系信息,可以从一组相同的动作者特征构建多个关系图。
- 最后,进行学习和推理以识别个人行为和群体活动。 在GCN之后,ARG 融合在一起以生成动作者的关系特征,也是 N × d 维。 然后将分别用于识别个体动作和群体活动的两个分类器应用于汇集的动作者的关系特征和原始特征。 在个体表示上应用一个全连接层来进行个体动作分类。 动作者表示经过maxpool生成场景级表示,通过另一个全连接层进行群体活动分类。
2.构建ARG
2.1图的定义
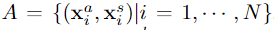
A是动作者的集合,N是人的数量,xia是第i个动作者的外观特征,它是一个d维的向量。
xis=(tix,tiy),是第i个动作者的边界框中心坐标。
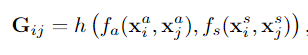
为了获得足够的表征能力来捕捉两个参与者之间的潜在关系,需要同时考虑外观特征和位置信息。
- G是一个N*N的矩阵,Gij代表第j个动作者特征对第i个动作者的重要性。
- fa(xia,xja)是指两个动作者之间的外观联系,fs(xis,xjs)是指两个动作者之间的位置联系。
- h是一个聚合函数,将外观联系与位置联系聚合为一个标量。
在此实验中,采用以下聚合函数来计算:
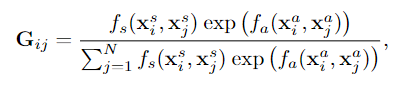
2.2外观联系
这里讨论了三种方式表达外观联系,也就是 fa(xia,xja)函数
1.Dot-Product
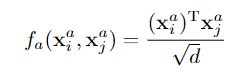
2.Embedded Dot-Product
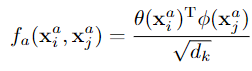
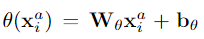
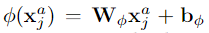
W的维度是dk*d,b是维度为dk的向量
通过原始特征的可学习变换,我们可以学习两个动作者之间的关系值
3.Relation Network
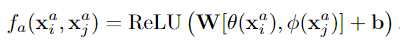
[·,·]内是连接操作,W和b是可学习参数,最后经过Relu函数成为一个标量
2.3位置联系
为了向ARG添加动作者之间的位置关系,即fs(xis,xjs),为此,使用了两种方法。
1.Distance Mask
将距离超过某个阈值的两个动作者的 Gij 设置为零。
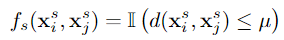
II(.)是一个指示函数,d(xsi,xsj) 表示两个演员边界框中心点之间的欧氏距离,μ 作为距离阈值,它是一个超参数.
2.Distance Encoding
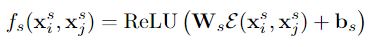
使用不同波长的余弦和正弦函数,将两个参与者之间的相对距离嵌入到高维表示中。 嵌入后的特征维度为ds。 然后通过 Ws 和 bs 将嵌入的特征转换为标量,最后使用ReLU激活函数
2.4多重图(Multiple graphs)
单个ARG通常关注动作者之间的特定关系信号,因此会丢弃大量上下文信息。 为了捕获不同类型的关系信号,我们可以将单个ARG扩展为多个图。 也就是说,我们在同一个actor集合上构建一组图G = (G1,G2,…,GNg),其中Ng是图的数量。 每个图 Gi 都是根据等式以相同的方式计算的,如2.1中所示,但其中的可学习参数不共享。
2.5时间建模(Temporal modeling)
时间上下文信息是活动识别的关键线索。 不同于之前使用RNN来聚合密集帧上的时间信息,此模型通过稀疏时间采样策略合并时间信息。 在训练期间,我们从整个视频中随机抽取一组 K = 3 帧,并在这些帧中的演员上构建时间图。 将得到的 ARG 称为随机 ARG。 在测试时,我们可以使用滑动窗口方法,将所有窗口的活动分数均值合并以形成全局活动预测。
优点:节省计算资源和时间,提高识别精度,降低过拟合的风险
3.图的推理与训练
3.1推理
一旦建立了 ARG,就可以对它们进行关系推理,以识别个人行为和群体活动。GCN 将图作为输入,对结构进行计算,并返回图作为输出,可以将其视为“图到图”的模块。 对于图中的目标节点 i,它根据它们之间的边权重聚合来自所有相邻节点的特征。 形式上,一层 GCN 可以写成
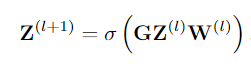
- G已经了解了,是N*N的矩阵,表示的是动作者之间的联系。
- Z(l)是第l层的特征表示,对于l=0,即Z0=X,N × d 矩阵 X 来表示动作者的特征向量(图中的original feature)。
- W(l)是d *d的可学习矩阵,最外层是Relu激活函数。
这种逐层传播可以堆叠成多层, 在这项工作中只使用了一层 GCN。
原始 GCN 在单个图结构上运行,为此,带来了三种选择:
- 在GCN前进行聚合
- 在GCN后进行相加聚合(element-wise sum)
- 在GCN后进行串联聚合(concatenation)
在这项工作中,采用了第二种方案,即在 GCN 之后相加聚合不同图中的同一动作者的特征:
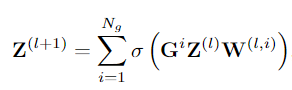
最后,GCN 的输出关系特征通过求和与原始特征融合形成场景表示。 如上图所示,场景表示被送到两个分类器以生成个人动作和群体活动预测。
3.2训练
整个模型可以通过反向传播以端到端的方式进行训练。采用交叉熵损失函数,最终的损失函数为
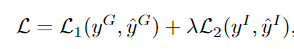
yG和yI分别是群体活动和个人活动的真实值(ground-truth),其余两个分别是预测值,L1和L2都是交叉熵损失函数,第一项对应于群体活动分类的损失,第二项是个人活动分类的损失。 权重 λ \lambda λ用于平衡这两个任务。
四.消融实验
论文中指出,对排球数据集进行了详细的消融实验,以了解所提出的模型组件对群体活动识别精度的影响。
1.外观联系
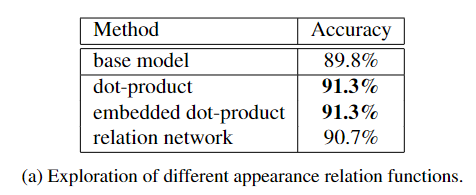
首先观察到,显式建模动作者之间的关系会带来显着的性能提升。点积(Dot-Product)和嵌入点积(Embedded Dot-Product)产生相同的识别准确率 91.3%,并且表现优于relation network。在下面的实验中,嵌入式点积用于计算外观联系值。
2.位置联系
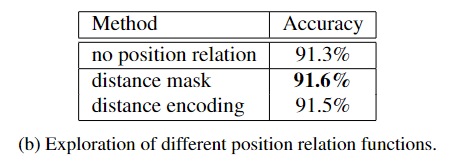
这两种方法都比不使用空间特征的方法获得了更好的性能,证明了建模位置关系的有效性。 并且距离掩码(distance mask)产生比距离编码(distance encoding)有较好的准确度。 因此实验选择distance mask来表示位置联系。
3.多重图
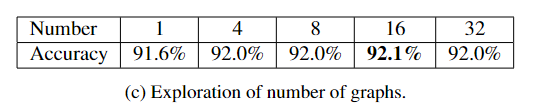
首先,比较了不同数量图的性能。可以观察到,与仅构建单个图相比,构建多个图会带来显著的效益,并且能够将准确度从 91.6% 进一步提高到 92.1%。
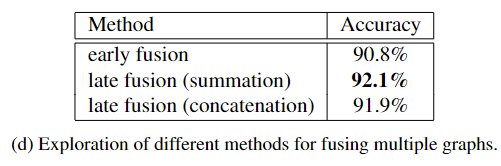
聚合一组图的三种方法:
- 前期聚合
- 通过求和进行后期聚合
- 通过串联进行后期聚合
使用 16 个图的实验结果总结在表 d 中。 通过求和的后期融合实现了最佳性能。 因此实验中采用 Ng = 16 和通过求和进行后期聚合
4.时间建模
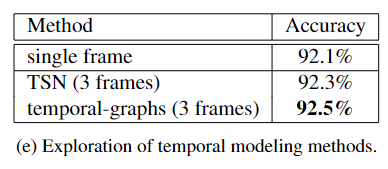
采用稀疏时间采样策略,并在训练期间从整个视频中均匀采样一组 K = 3 帧。
- 分别处理输入帧,然后将不同帧的预测分数融合为时间段网络(TSN)。
- 在输入帧中的参与者上构建时间图,并通过 GCN 融合时间信息。
TSN 有助于提高模型的性能,此外,构建时间图进一步将准确率提高到 92.5%。
五.与其他技术的比较

通过上面的表格可以看出,本实验最终确实达到了最先进的效果.
对于排球数据集,采用ground-truth的边界框,VGG16网络,个人活动的预测准确率达到了83.1%
采用ground-truth的边界框,VGG19网络,团体活动的预测准确率达到92.6%
对于集体活动数据集,采用ground-truth的边界框,Inception-v3网络,团体活动的预测准确率达到了91.0%
这篇关于Learning Actor Relation Graphs for Group Activity Recognition 论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







