本文主要是介绍AI系统性学习06—开源中文语言大模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、ChatGLM
ChatGLM-6B的github地址:https://github.com/THUDM/ChatGLM-6B
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
为了方便下游开发者针对自己的应用场景定制模型,我们同时实现了基于 P-Tuning v2的高效参数微调方法 (使用指南) ,INT4 量化级别下最低只需 7GB 显存即可启动微调。
2、硬件部署
2.1 硬件需求
| 量化等级 | 最低GPU显存(推理) | 最低GPU显存(高效参数微调) |
|---|---|---|
| FP16(无量化) | 13GB | 14GB |
| INT8 | 8GB | 9GB |
| INT4 | 6GB | 7GB |
2.2 环境安装
推荐在AutoDL上运行。
- 创建AutoDL容器,下载好后使用ssh工具连接上去
- 下载模型
因为huggingface被墙,所以我的建议是先将模型下载到本地,然后再在无卡模式下上传到服务器上,操作可以看这篇博文:huggingface下载模型 - 安装环境
conda create -n chatglm python=3.8
conda activate chatglm
pip install protobuf transformers==4.30.2 cpm_kernels torch>=2.0 gradio mdtex2html sentencepiece accelerate
- 从pycharm上连接到服务器上
使用下面的代码
注意将其中的模型地址换成自己本机上的地址
from transformers import AutoTokenizer, AutoModeltokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/huggingface/hub/models--THUDM--chatglm-6b/snapshots/8b7d33596d18c5e83e2da052d05ca4db02e60620", trust_remote_code=True)
model = AutoModel.from_pretrained("/root/autodl-tmp/huggingface/hub/models--THUDM--chatglm-6b/snapshots/8b7d33596d18c5e83e2da052d05ca4db02e60620", trust_remote_code=True).half().cuda()
model = model.eval()
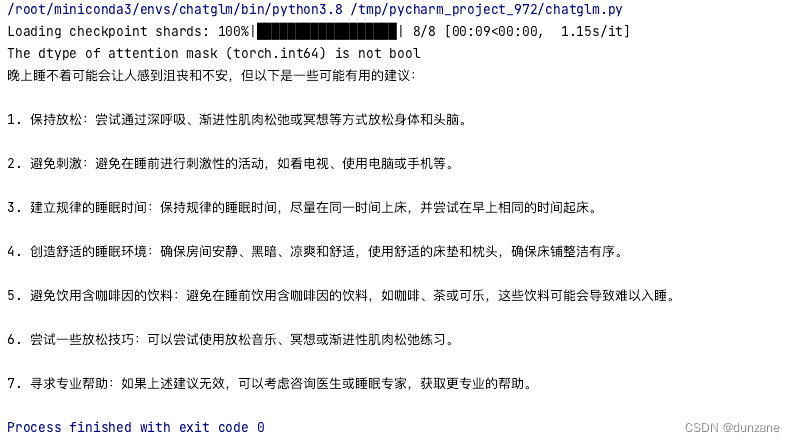
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)
成功如下:
这篇关于AI系统性学习06—开源中文语言大模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






