本文主要是介绍【小沐学AI】数据分析的Python库:Pandas AI,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1、简介
- 2、安装
- 2.1 Python
- 2.2 PandasAI
- 3、部署
- 4、功能
- 4.1 大型语言模型 (LLM)
- 4.1.1 BambooLLM
- 4.1.2 OpenAI 模型
- 4.1.3 谷歌 PaLM
- 4.1.4 谷歌 Vertexai
- 4.1.5 Azure OpenAI
- 4.1.6 HuggingFace 模型
- 4.1.7 LangChain 模型
- 4.1.8 Amazon Bedrock 模型
- 4.1.9 本地模型
- 5、代码测试
- 5.1 入门示例
- 结语
1、简介
https://pandas-ai.com/
https://github.com/Sinaptik-AI/pandas-ai
PandasAI 是一个 Python 库,可以轻松地用自然语言向数据提问。它可以帮助您使用生成式 AI 探索、清理和分析数据。

PandasAI与您的数据库(SQL、CSV、pandas、polars、mongodb、noSQL 等)聊天。PandasAI 使用 LLM(GPT 3.5 / 4、Anthropic、VertexAI)和 RAG 进行数据分析对话。
PandasAI 是一个 Python 库,可以轻松地用自然语言对数据(CSV、XLSX、PostgreSQL、MySQL、BigQuery、Databrick、Snowflake 等)提出问题。xIt 可帮助您使用生成式 AI 探索、清理和分析数据。
除了查询之外,PandasAI 还提供通过图形可视化数据、通过处理缺失值来清理数据集以及通过特征生成提高数据质量的功能,使其成为数据科学家和分析师的综合工具。
PandasAI 使用生成式 AI 模型来理解和解释自然语言查询,并将其转换为 python 代码和 SQL 查询。然后,它使用代码与数据交互并将结果返回给用户。
- PandasAI 的特点
- 自然语言查询:使用自然语言向数据提问。
- 数据可视化:生成图形和图表以可视化数据。
- 数据清理:通过处理缺失值来清理数据集。
- 特征生成:通过特征生成提高数据质量。
- 数据连接器:连接到各种数据源,如 CSV、XLSX、PostgreSQL、MySQL、BigQuery、Databrick、Snowflake 等。
2、安装
2.1 Python
https://www.python.org/downloads/windows/
首先尝试安装Python3.12
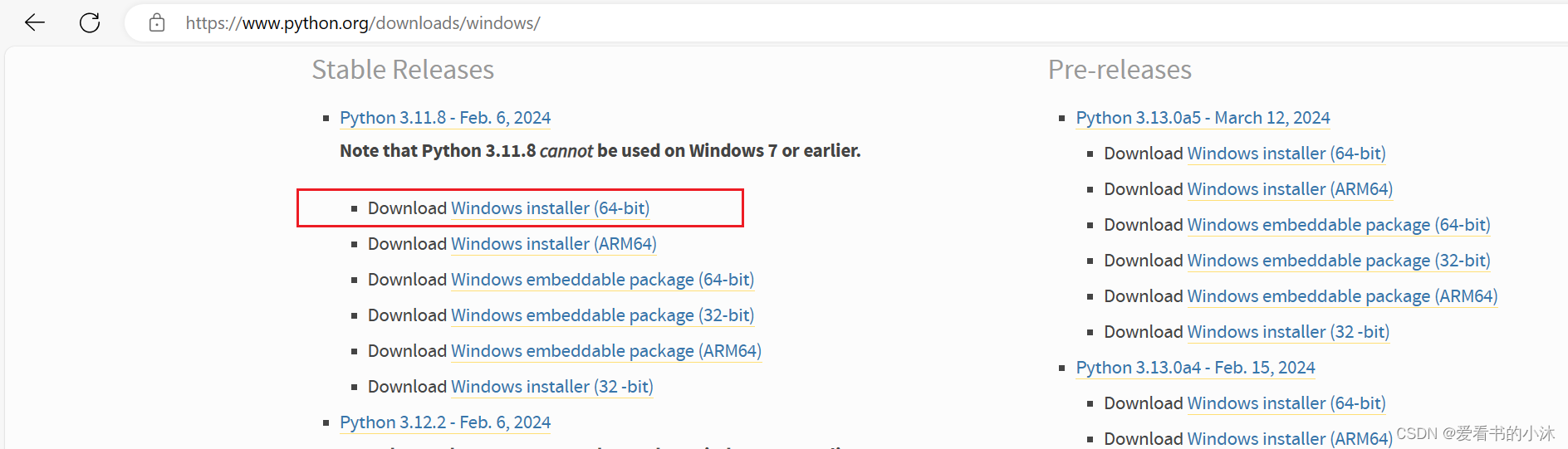
2.2 PandasAI
使用如下命令安装:
pip install pandasai
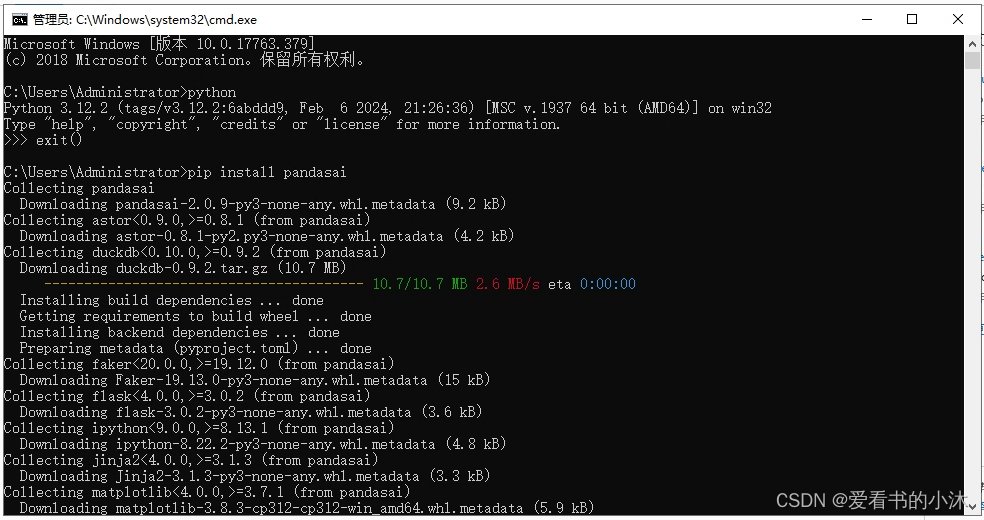
安装刚开始还比较顺利。
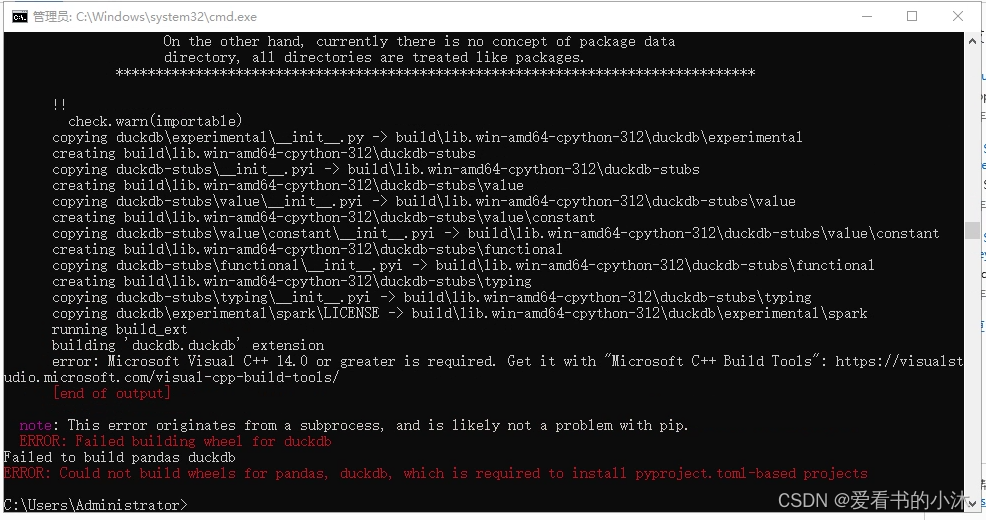
结果后面如上报错,需要VC++编译器,于是安装VS2019如下:
vs2019社区版下载地址:
https://learn.microsoft.com/zh-cn/visualstudio/releases/2019/release-notes
vs2019专业版下载地址:
https://visualstudio.microsoft.com/zh-hans/vs/older-downloads/
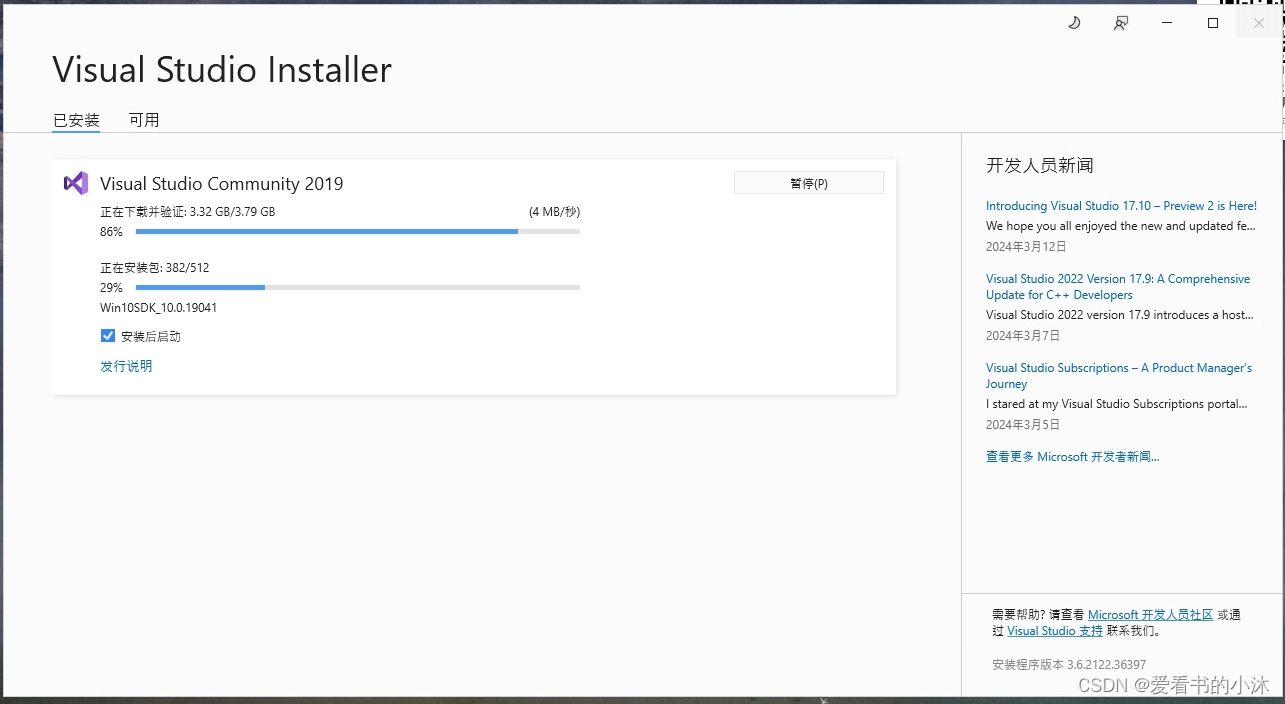
安装完vs2019之后,再安装PandasAI 仍然报错。
于是卸载Python3.12,安装Python3.11试试。
安装完Python3.11之后。

再安装PandasAI 如下:
正在安装中,
提示安装安装成功。
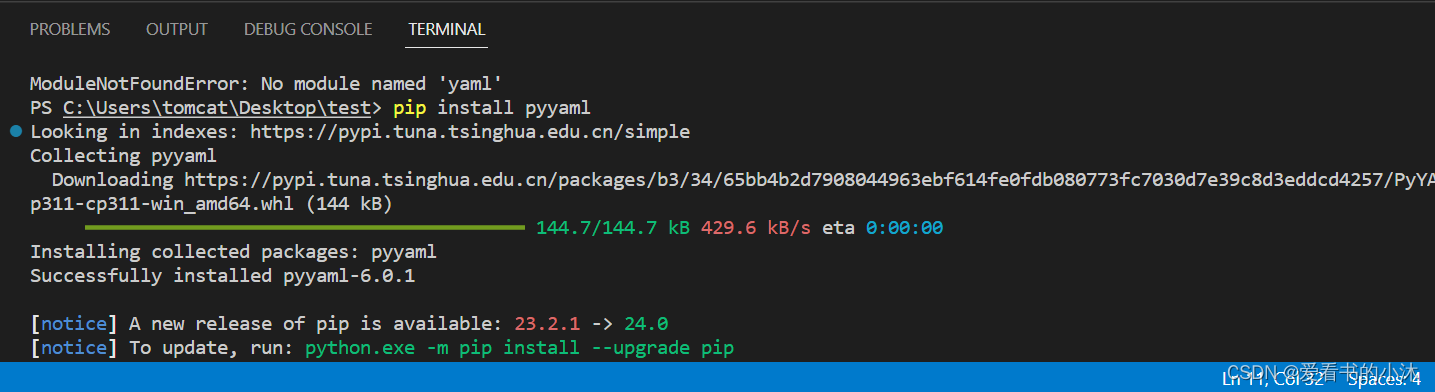
运行测试脚本后,提示还需要pyyaml库。
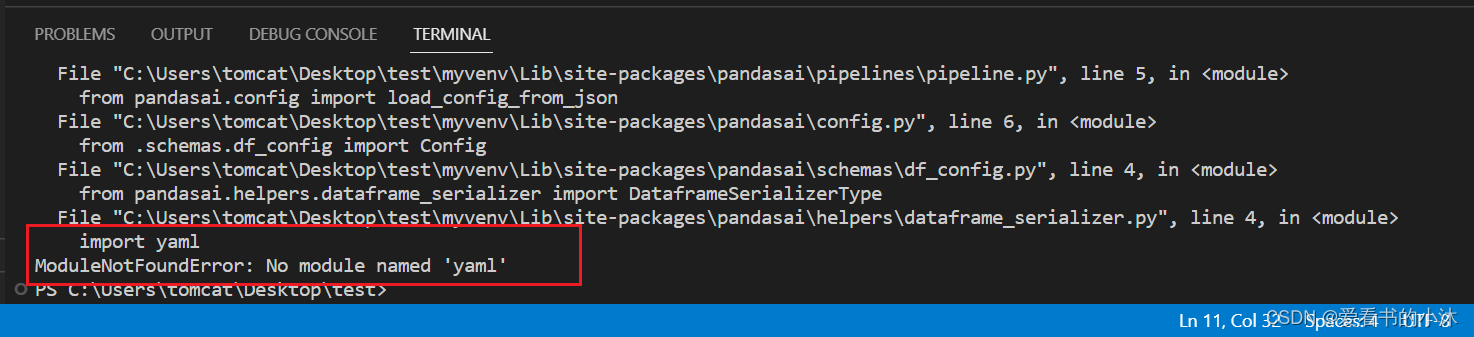
这里再安装一下pyyaml库。
pip install pyyaml
3、部署
PandasAI 可以通过多种方式进行部署。
-
您可以在 Jupyter 笔记本或streamlit 应用中轻松使用它,也可以将其部署为 REST API,例如使用 FastAPI 或 Flask。
-
托管 PandasAI Cloud 或自托管企业产品,见网站https://pandas-ai.com/。
4、功能
4.1 大型语言模型 (LLM)
https://docs.pandas-ai.com/en/latest/LLMs/llms/
PandasAI 支持多种大型语言模型 (LLM)。LLM 用于从自然语言查询生成代码。然后执行生成的代码以生成结果。
您可以通过实例化一个 LLM 并将其传递给 or 构造函数来选择一个 LLM,也可以在文件中指定一个 LLM。SmartDataFrame / SmartDatalake / pandasai.json
4.1.1 BambooLLM
BambooLLM 是由 PandasAI 开发的最先进的语言模型,考虑了数据分析。
- 示例代码如下:
from pandasai import SmartDataframe
from pandasai.llm import BambooLLMllm = BambooLLM(api_key="my-bamboo-api-key")
df = SmartDataframe("data.csv", config={"llm": llm})response = df.chat("Calculate the sum of the gdp of north american countries")
print(response)
4.1.2 OpenAI 模型
为了使用 OpenAI 模型,您需要拥有 OpenAI API 密钥。
https://platform.openai.com/account/api-keys
- 示例代码如下:
from pandasai import SmartDataframe
from pandasai.llm import OpenAIllm = OpenAI(api_token="my-openai-api-key")
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
4.1.3 谷歌 PaLM
为了使用 Google PaLM 模型,您需要拥有 Google Cloud API 密钥。
- 示例代码如下:
from pandasai import SmartDataframe
from pandasai.llm import GooglePalmllm = GooglePalm(api_key="my-google-cloud-api-key")
df = SmartDataframe("data.csv", config={"llm": llm})
4.1.4 谷歌 Vertexai
为了通过 Vertexai api 使用 Google PaLM 模型,您需要具备:
Google Cloud 项目
项目设置区域
安装可选依赖项google-cloud-aiplatform
认证gcloud
- 示例代码如下:
from pandasai import SmartDataframe
from pandasai.llm import GoogleVertexAIllm = GoogleVertexAI(project_id="generative-ai-training",location="us-central1",model="text-bison@001")
df = SmartDataframe("data.csv", config={"llm": llm})
4.1.5 Azure OpenAI
若要使用 Azure OpenAI 模型,需要具有 Azure OpenAI API 密钥以及 Azure OpenAI 终结点。
https://azure.microsoft.com/zh-cn/products/ai-services/openai-service/
- 示例代码如下:
from pandasai import SmartDataframe
from pandasai.llm import AzureOpenAIllm = AzureOpenAI(api_token="my-azure-openai-api-key",azure_endpoint="my-azure-openai-api-endpoint",api_version="2023-05-15",deployment_name="my-deployment-name"
)
df = SmartDataframe("data.csv", config={"llm": llm})
4.1.6 HuggingFace 模型
为了通过文本生成使用 HuggingFace 模型,您需要首先提供受支持的大型语言模型 (LLM)。例如,这可用于使用 LLaMa2、CodeLLaMa 等模型。
https://huggingface.co/docs/text-generation-inference/index
- 示例代码如下:
from pandasai.llm import HuggingFaceTextGen
from pandasai import SmartDataframellm = HuggingFaceTextGen(inference_server_url="http://127.0.0.1:8080"
)
df = SmartDataframe("data.csv", config={"llm": llm})
4.1.7 LangChain 模型
PandasAI 还内置了对 LangChain 模型的支持。
为了使用LangChain模型,您需要安装软件包:langchain
pip install pandasai[langchain]
- 示例代码如下:
from pandasai import SmartDataframe
from langchain_openai import OpenAIlangchain_llm = OpenAI(openai_api_key="my-openai-api-key")
df = SmartDataframe("data.csv", config={"llm": langchain_llm})
4.1.8 Amazon Bedrock 模型
要使用 Amazon Bedrock 模型,您需要拥有 AWS AKSK 并获得模型访问权限。
https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_access-keys.html
您需要安装软件包: pip install pandasai[bedrock]
- 示例代码如下:
from pandasai import SmartDataframe
from bedrock_claude import BedrockClaude
import boto3bedrock_runtime_client = boto3.client('bedrock-runtime',aws_access_key_id=ACCESS_KEY,aws_secret_access_key=SECRET_KEY
)llm = BedrockClaude(bedrock_runtime_client)
df = SmartDataframe("data.csv", config={"llm": llm})
4.1.9 本地模型
PandasAI 支持本地模型,但较小的模型通常性能不佳。要使用本地模型,请先在遵循 OpenAI API 的本地推理服务器上托管一个模型。这已经过测试,可与 Ollama 和 LM Studio 配合使用。
from pandasai import SmartDataframe
from pandasai.llm.local_llm import LocalLLMollama_llm = LocalLLM(api_base="http://localhost:11434/v1", model="codellama")
df = SmartDataframe("data.csv", config={"llm": ollama_llm})
from pandasai import SmartDataframe
from pandasai.llm.local_llm import LocalLLMlm_studio_llm = LocalLLM(api_base="http://localhost:1234/v1")
df = SmartDataframe("data.csv", config={"llm": lm_studio_llm})
5、代码测试
5.1 入门示例
import pandas as pd
from pandasai import SmartDataframe# Sample DataFrame
sales_by_country = pd.DataFrame({"country": ["United States", "United Kingdom", "France", "Germany", "Italy", "Spain", "Canada", "Australia", "Japan", "China"],"sales": [5000, 3200, 2900, 4100, 2300, 2100, 2500, 2600, 4500, 7000]
})# Instantiate a LLM
from pandasai.llm import OpenAI
llm = OpenAI(api_token="YOUR_API_TOKEN")df = SmartDataframe(sales_by_country, config={"llm": llm})
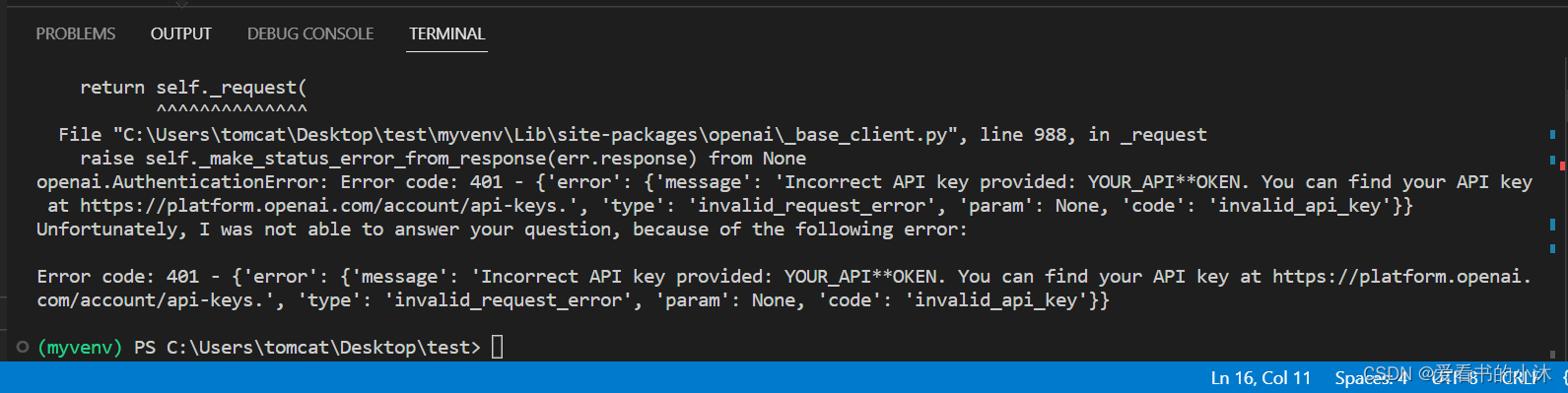
df.chat('Which are the top 5 countries by sales?')
运行后提示open key错误或不存在,如下:
当然正确的结果应该输出:
China, United States, Japan, Germany, Australia
修改代码,使用google的AI如下:
import pandas as pd
from pandasai import SmartDataframe# Sample DataFrame
sales_by_country = pd.DataFrame({"country": ["United States", "United Kingdom", "France", "Germany", "Italy", "Spain", "Canada", "Australia", "Japan", "China"],"sales": [5000, 3200, 2900, 4100, 2300, 2100, 2500, 2600, 4500, 7000]
})# Instantiate a LLM
# from pandasai.llm import OpenAI
# llm = OpenAI(api_token="YOUR_API_TOKEN")from pandasai.llm import GooglePalm
llm = GooglePalm(api_key="my-google-cloud-api-key")# df = SmartDataframe("data.csv", config={"llm": llm})
df = SmartDataframe(sales_by_country, config={"llm": llm})res = df.chat('Which are the top 5 countries by sales?')
print(res)
运行又报错,如下:
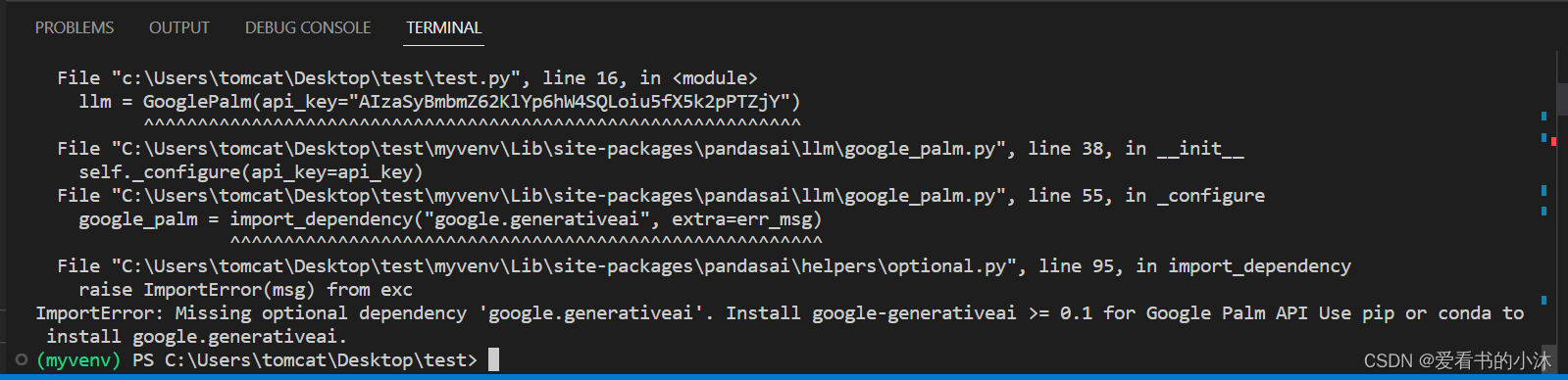
安装了google.generativeai库之后:
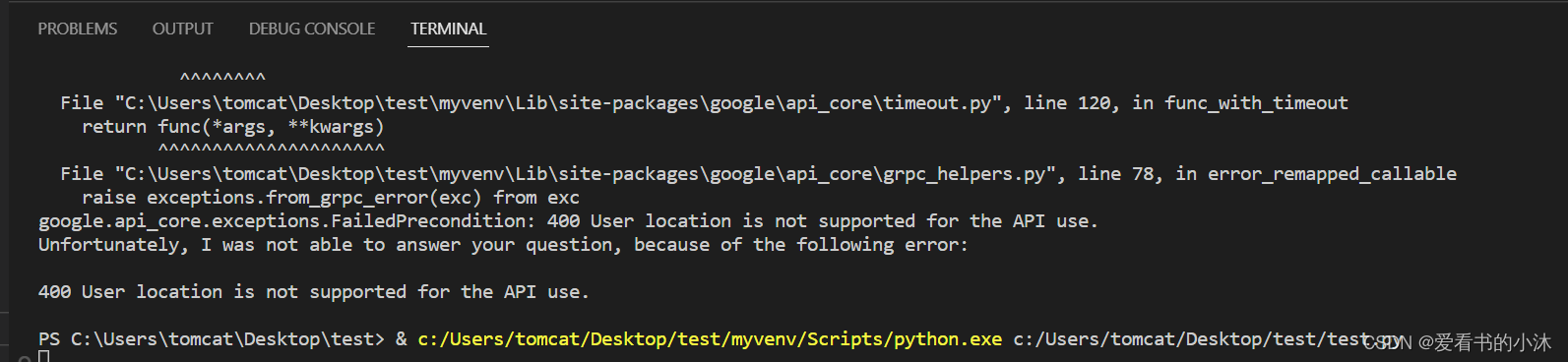
仍然报错如上。
尝试画图语句如下:
df.chat("Plot the histogram of countries showing for each the sales",
)
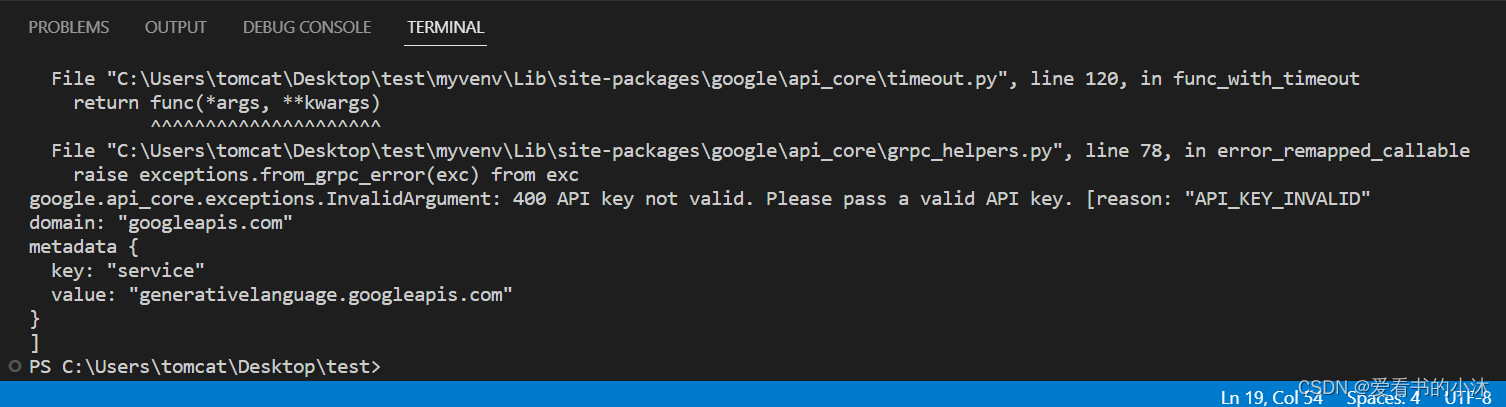
仍然报错如上。
结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;╮( ̄▽ ̄)╭
如果您感觉方法或代码不咋地//(ㄒoㄒ)//,就在评论处留言,作者继续改进;o_O???
如果您需要相关功能的代码定制化开发,可以留言私信作者;(✿◡‿◡)
感谢各位童鞋们的支持!( ´ ▽´ )ノ ( ´ ▽´)っ!!!

这篇关于【小沐学AI】数据分析的Python库:Pandas AI的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




