本文主要是介绍GEE数据集——全球( 30 弧秒)尺度地下水模型GLOBGM v1.0数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
全球尺度地下水模型GLOBGM v1.0
GLOBGM v1.0 数据集是全球地下水建模的一个重要里程碑,提供了 30 弧秒 PCR-GLOBWB-MODFLOW 模型的并行实施。该数据集由 Jarno Verkaik 等人开发,以赤道约 1 公里的空间分辨率全面展示了全球地下水动态。该数据集利用两个模型层和 MODFLOW 6 框架,利用现有的 30′′ PCR-GLOBWB 数据进行模拟,使研究人员能够探索全球范围的地下水流动态。计算实现采用消息传递接口并行化,便于在分布式内存并行集群上进行高效处理。
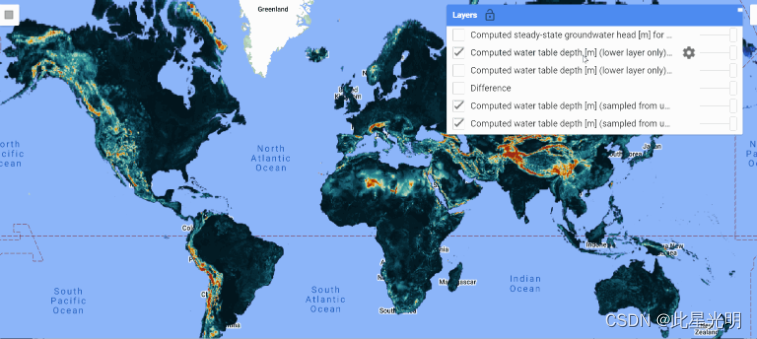
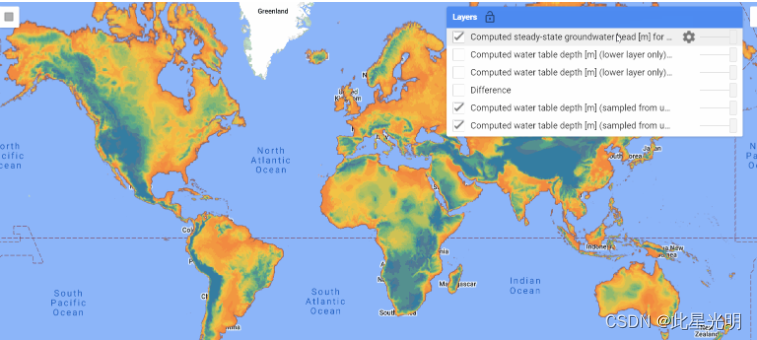
GLOBGM v1.0 数据集覆盖全球(不包括格陵兰岛和南极洲),有助于深入了解地下水行为的各个方面。尽管该数据集未经校准,但它利用美国地质调查局(USGS)国家水信息系统(NWIS)对美国毗连地区(CONUS)的水头观测数据进行了有限的评估。您可以点击此处阅读论文,以便更好地了解该方法。
讨论了在大型分布式内存并行集群上并行化 30′′ 分辨率(30 弧秒;赤道上 ∼ 1 公里)瞬态全球尺度地下水模型的各方面性能。该模型被称为 GLOBGM,是 PCR-GLOBWB 2(PCRaster Global Water Balance Model,PCRaster 全球水平衡模型)5′(5 弧分;赤道 ∼ 10 公里)地下水模型的后继模型,基于具有两个模型层的 MODFLOW。本研究使用的当前版本 GLOBGM(v1.0)也有两个模型层,未经校准,使用的是现有的 30′′ PCR-GLOBWB 数据。将模型分辨率从 5′ 提高到 30′ 会带来一些挑战,包括运行时间、内存使用量和数据存储量的增加,这些都超出了单台计算机的承受能力。我们的研究表明,我们的并行化方法能以相对较低的并行硬件要求解决这些问题,从而满足那些无法独享超级计算机中成百上千个节点的用户或建模人员的需求。
在模拟中,我们使用了非结构化网格和 MODFLOW 6 的原型版本,并利用消息传递接口对其进行了并行化处理。我们构建了总计 2.78 亿个活动单元的独立非结构化网格,以消除所有多余的海洋和陆地单元,同时满足所有必要的边界条件,并将其分布在三个大陆尺度的地下水模型上(1.68 亿个--非洲-欧亚大陆;0.77 亿个--美洲;0.16 亿个--澳大利亚),剩下的一个模型用于较小的岛屿(0.17 亿个)。四个地下水模型中的每个模型都被划分为多个不重叠的子模型,这些子模型在 MODFLOW 线性求解器中紧密耦合,每个子模型被唯一分配给一个处理器内核,相关子模型数据在预处理过程中使用数据块并行写入。为了提前平衡并行工作量,我们以两种方式应用了广泛使用的 METIS 图分割器:直接应用于所有(横向)模型网格单元,并以基于区域的方式应用于 HydroBASINS 集水区,这些集水区被分配给子模型,以便对未来与地表水的耦合进行预排序。我们考虑在荷兰国家超级计算机 Snellius 上进行一次试验,以每日时间步长和每月输入的方式模拟 1958-2015 年,包括 20 年的自旋。鉴于串行模拟需要 4.5 个月的运行时间,我们设定了最多 16 小时模拟运行时间的假设目标。我们的结果表明,12 个节点(每个节点 32 个内核;共 384 个内核)足以实现这一目标,在并行使用 7 个节点(224 个内核)时,最大的非洲-欧亚大陆模型的速度提高了 138 倍。
利用美国地质调查局 (USGS) 国家水信息系统 (NWIS) 对美国毗连地区的水头观测数据,对模型输出结果进行了有限的评估。结果表明,与 5 ′ PCR-GLOBWB 地下水模型相比,将分辨率从 5 ′提高到 30 ′,GLOBGM 在稳态模拟中的效果明显改善。然而,瞬态模拟的结果非常相似,还有很大的改进余地。不过,GLOBGM 和 PCR-GLOBWB 模型得出的月度和多年陆地总蓄水量异常值与 GRACE 卫星的观测结果相比还是比较理想的。要进一步改进下一版全球陆地水文地理信息模型,需要更详细的(水文)地质示意图和有关取水井位置、深度和抽水量的更多信息。
数据结构
本表提供了 GLOBGM 数据集模型栅格输出的结构概述,包括文件路径和每个文件的说明。
| File Path | Description |
|---|---|
| /steady-state/globgm-heads-lower-layer-ss.tif | Computed steady-state groundwater head [m] for the lower model layer |
| /steady-state/globgm-heads-lower-layer-ss.tif | Computed steady-state groundwater head [m] for the upper model layer |
| /steady-state/globgm-wtd-ss.tif | Computed water table depth [m] (sampled from upper to lower layer) |
| /transient_1958-2015/globgm-wtd-.tif | Computed water table depth [m] (sampled from upper to lower layer) |
| /transient_1958-2015/globgm-wtd-bot-*.tif | Computed water table depth [m] (lower layer only) |
文章引用
Verkaik, Jarno, Edwin H. Sutanudjaja, Gualbert HP Oude Essink, Hai Xiang Lin, and Marc FP Bierkens. "GLOBGM v1. 0: a parallel implementation of a 30
arcsec PCR-GLOBWB-MODFLOW global-scale groundwater model." Geoscientific Model Development 17, no. 1 (2024): 275-300.
数据引用
Verkaik, J., Hughes J.D., Langevin, C.D., (2021). Parallel MODFLOW 6.2.1 prototype release 0.1 (6.2.1_0.1). Zenodo.
数据代码
var wtd = ee.ImageCollection("projects/sat-io/open-datasets/GLOBGM/TRANSIENT/WTD");
var wtd_bt = ee.ImageCollection("projects/sat-io/open-datasets/GLOBGM/TRANSIENT/WTD-BOTTOM");
var globgm_wtd_ss = ee.Image("projects/sat-io/open-datasets/GLOBGM/STEADY-STATE/globgm-wtd-ss");
var globgm_heads_lower_layer_ss = ee.Image("projects/sat-io/open-datasets/GLOBGM/STEADY-STATE/globgm-heads-lower-layer-ss");
var globgm_heads_upper_layer_ss = ee.Image("projects/sat-io/open-datasets/GLOBGM/STEADY-STATE/globgm-heads-upper-layer-ss");
Sample code: https://code.earthengine.google.com/?scriptPath=users/sat-io/awesome-gee-catalog-examples:hydrology/GLOBGM-GROUNDWATER-MODEL
License¶
GLOBGM v1.0 is open source and distributed under the terms of GNU General Public License v3.0, or any later version, as published by the Free Software Foundation.
Created by: Verkaik et al. 2024
Curated in GEE by : Samapriya Roy
Keywords: GLOBGM,groundwater,global-scale modeling,PCR-GLOBWB,MODFLOW,high performance computing
Last updated in GEE: 2024-02-04
网址推荐
0代码在线构建地图应用
https://sso.mapmost.com/#/login?source_inviter=nClSZANO
机器学习
https://www.cbedai.net/xg
这篇关于GEE数据集——全球( 30 弧秒)尺度地下水模型GLOBGM v1.0数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





