本文主要是介绍mysql颗粒归仓,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
B+
B树:节点排序 一个节点存多个元素 多个元素也排序了
叶子节点间有指针,非叶子节点上的元素在叶子节点冗余:叶子节点存储排好序的all元素
通过数据排序提高查询速度,节点存储多个元素 高度不会太高,一个innodb页=B+树节点,16k两层B+树存储2000万行,叶子节点存储所有数据并且进行了排序,叶子之间有指针,很好支持全表扫描,范围查找
索引结构
设计原则:
where子句中的列,连接子句中指定的列
前缀索引,索引需要额外空间 降低写性能
更新频繁的字段不适合索引
尽量扩展索引不要新建索引
text image bit数据类型列不建立索引
结构
二叉树:每个节点最多只有两个字节点,左边字节点比当前小,右边字节点比当前大
AVL:树中任意节点的两个子树 高度差max=1
红黑树:每个节点都是红色或黑色,根是黑色,叶子节点黑色的空节点,红色节点的父节点都必须是褐色,从任一节点到其每个叶子节点所有路径含相同的黑色节点
B+树:非叶子节点不存储数据,只进行数据索引 ;所有数据存储在叶子节点 ;叶子节点都存有相邻叶子节点的指针 ;叶子节点按照本身关键字从小到大排序
哈希索引
哈希算法 将键值换算成新的哈希值,等值查询 效率高
范围查询不支持 哈希值排序打乱了 like也不行
不支持多列联合索引的最左匹配规则
聚簇索引
数据和索引在一起 ; 数据物理存放顺序和索引顺序一致
维护昂贵,插入新行或主键被更新导致分页
在大量插入新行后,在负载较低的时候,optimize table优化表,使用独享表空间可弱化碎片
int类型的自增主键
非聚簇索引
树的子节点data不是数据本身,数据存放地址
唯一索引:唯一性
主键索引:innodb 聚簇索引,唯一性 只能一个(myisam innodb)
联合索引:多个列组成索引
全文索引:倒排索引,alter table table_name add fulltext(column);
查询过程中 优化隐藏器 提高系统
占用物理空间,插入 删除 更新表速度降低
普通索引:含重复值
索引失效
最左前缀原则,隐式类型转化,走索引没有全表扫描效率高
慢查询
是否走索引,最优索引,字段是否必须,数据是否过多,机器性能
是否加载了多余的数据,查了多余并且抛弃掉了,加载不需要的列
执行计划;加载数据量过大 分表
ACID 如何保证:
A原子性,undolog日志 记录了需要回滚的日志信息
I隔离性 MVCC保证
D持久性 内存+redo log ,修改数据同时在内存 redo log记录操作,宕机时从redo log恢复
C一致性:其他三大特性保证,程序代码保证业务上一致性
步骤
redo log写盘 innodb事务进入 prepare状态
前面prepare成功 binlog 写盘 将事务日志持久化到binlog
持久化成功 事务commit ,redo log写入commit记录,redo log系统空闲时刷盘
事务
多个操作组成一个完整的事务单元
buffer pool ,log buffer,redo log,undo log
update 先根据条件找到数据所在页 该页缓存到buffer pool中
执行update修改buffer pool数据(内存中的数据)
针对update生成redoLog对象,放入logBuffer中
针对update生成undoLog对象,用于回滚
如事务提交 则把redoLog对象持久化 其他机制将buffer pool中修改数据页持久化到磁盘
如事务回滚,利用undoLog日志回滚
redoLog
重做日志缓冲redo log buffer ,重做日志文件 rego log
现存buffer 后台线程同步缓存池和磁盘
undo Log
被修改前到信息,逻辑变化 ;记录某行数据的多个版本的数据
insert undo log
insert新记录时产生undo log,只在事务回滚时需要,事务提交后立即丢弃
update undo log,update或delete产生,不仅事务回滚时需要 快照读也需要,只有在快速读 事务回滚不涉及该日志 对应日志才会被purge线程同一清除
MVCC
readView
事务快照读生成的读视图,记录当前活跃事务id
将要修改的数据最新记录中的trx_id取出来,与系统当前其他活跃事务ID对比,不可见通过roll_ptr回滚指针取undoLog中trx_id再比较
innodb的mvcc 通过每行记录后面保存的两个隐藏列
trx_id聚簇索引修改时候的事务ID;
roll_pointer聚簇索引记录上一个版本的位置,在undo日志中;
提交读每次查询生成一个独立的readView;可重复读第一次读的时候生成一个readView
purge线程:
更新删除设置了老记录点deleted_bit,innodb专门点purge线程清理deleted_bit为true点记录
purge维护了read view 记录deleted_bit=true / trx_id相对于purege点read_view可见,可被清除

依靠undo log和read view
read uncommited未提交读
没有提交 其他事务可见,脏读
read commited提交读
已提交的修改变化,不可重读 幻读, 每次select新的版本号 每次读取的不是同一个副本
repeatable read可重复读
mysql默认,事务内多次读取结果是一样的;幻读
serializable序列化
explain
id为查询语句中select关键字分配唯一id值,某些子查询会被优化为join查询,id一样
select_type:查询类型
simple简单查询 primary最外层查询 subquery子查询第一个select
union第二或随后的查询 dependent union:第二个或后面的查询 derived衍生
table:表名
partitions:匹配的分区信息
type:单表的查询方式 全表扫描 索引
const通过索引一次命中,匹配一行数据
system表中只有一行记录,相当于系统表
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配
ref非唯一索引扫描返回匹配某个值的所有
range只检索给定范围的行,使用一个索引来选择行,between < >
index 只遍历索引树
all全表扫描,这个类型的查询性能最差
all index range ref eq_ref const system
possible_key可能用到的索引
key实际上使用的索引
key_Len 实际使用索引长度
ref使用索引等值查询,索引列进行等值匹配的对象信息
rows预估需要读取的记录条数
filtered某个表经过搜索条件过滤后剩余记录条数的百分比
extra:额外信息 排序等
using filesort:结果集外部排序,不能通过索引顺序达到排序效果
using index:覆盖索引扫描
using temporary:临时表 排序 分组和多表join的情况
using where:sql使用了where过滤
锁
行锁:加锁粒度小 资源开销大 inndb
共享锁:读锁,多个事务读同一个数据共享一把锁,可访问不能修改
select * from lock in share mode;
排他锁:写锁,只能一个事务获取排他锁,update/del/insert /select* for update
自增锁:自增字段,事务有回滚,数据回滚,自增序列不会回滚
记录锁
行锁的一种,一条记录;唯一索引精准条件命中!
表锁:加锁粒度大,加锁资源开销小 myisam 和 innodb都支持
表共享读锁
表排他写锁
意向锁:自动添加的,不需要干预
页级锁BDB引擎
行锁和表锁,相邻一组记录
全局锁:整个数据库实例都是只读状态
记录锁:锁一条具体记录
间隙锁:rr隔离级别下,会加间隙锁 锁一定的范围,防止幻读
行锁一种,某一个区间,左开右闭
repeatable_read 可重复读
临建锁next-key:间隙锁+右记录锁
行锁,查出来的数据 间隙空间 相邻下一个区间也锁住
集群
主从同步
slave的IO线程连接master,从指定日志文件的指定位置读取
master接收到slave的IO线程,据请求读取指定日志指定位置position后的日志信息返slave的IO线程且+本次返回信息在mster端端binary log文件名称及其位置
slave的IO线程接收到信息后接收日志男内容依次写入到slave到relayLog文件后,读取m的binLog文件名和位置记录到master-info文件中
slave的SQL检测到relayLog新增了内容后解析并执行
binlog上命令以event形式存在
事务表一个event group对应一个事务
非事务表一个event group对应一条sql语句
全同步复制
主库写入binlog后强制同步日志到从库,all从库都执行完才返回给客户
半同步复制
提交事务至少等待一个从库接收并写入到relay log中,默认等待10s,超过则降级为异步复制
提高数据安全性,只保证事务提交后binlog至少传输到一个从库,不保证从库应用成功
半同步复制机制一定程度的延迟,最少上一个TCP/IP请求往返的时间
存储引擎
myisam:每个表两个文件,myd数据文件 myisam索引文件 表结构文件
查询是原子的,表级锁,存储表的总行数 非聚集索引
innodb一个文件idb,支持事务 外键
一个innodb存储在一个文件空间,共享表空间 表大小不受操作系统控制 一个表可能分布在多个文件里
高可用
MMM主主复制管理器
perl语言实现的脚本程序,监控集群 故障迁移,两个master 同一时间只一个m对外服务
通过VIP虚拟ip机制保证集群高可用,整个集群 主节点通过VIP地址提供数据读写服务
故障时vip从原主节点漂移到其他节点,其他节点提供服务
MHA 基于perl脚本,监控主库状态
发现master故障,提升拥有新数据的slave成为新的master
通过其他节点获取额外信息避免数据一致性问题
master按需在线切换功能,30s故障切换,最大程度保证数据一致性
单独部署,manager节点和node节点
m单独部署一台机器,node部署在每台mysql机器上
node通过解析各mysql日志进行操作
m探测集群中node节点判断node所在机器上mysql运行是否正常
分库分表
单主模式:mgr集群选出primary负责写请求,p于其他节点进行读请求
多主模式:随机向mysql节点写入数据
水平拆分:分散到多张表 分区键
结构一样 数据不一样 没有交集
垂直拆分:字段拆分多张表
结构 数据都不一样,并集为全集
取模/按时间/按枚举值
mycat
shardingSphere
sql解析 抽象语法树 遍历
关键字(固定 select from where) 变量进一步拆分
sql方言不同 不同解析模板
1.4前 采用性能较快druid,1.5自研sql,采取对sql半理解方式,提高解析的性能和兼容性
3.0 anltr做sql解析引擎 增加ast缓存功能
解析器生成器 ANTLR的详细介绍-CSDN博客

查询优化
sql路由
全库表路由:不带分片键DQL DML DDL 遍历all库表
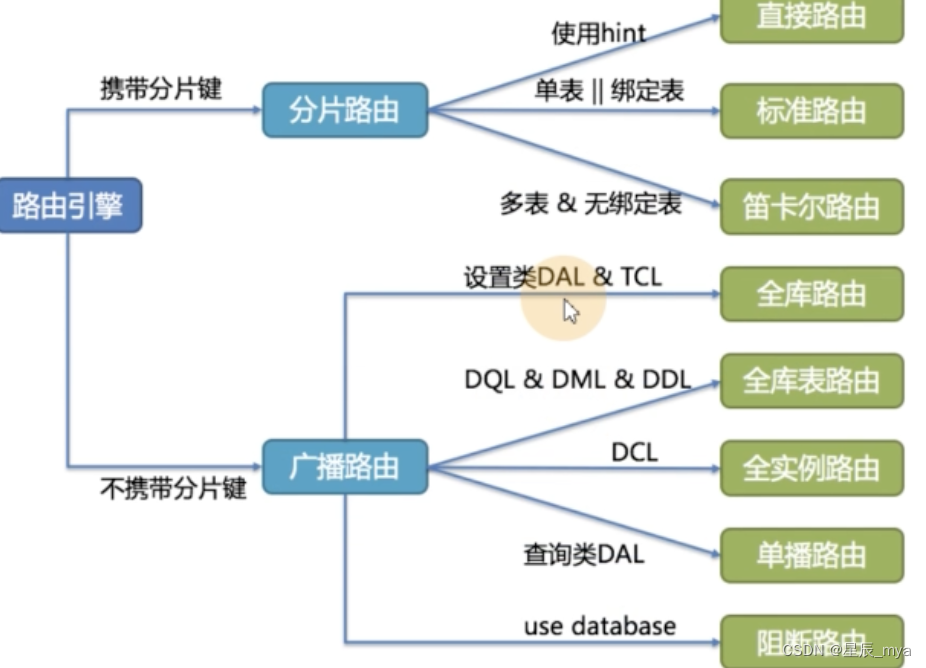
sql改写

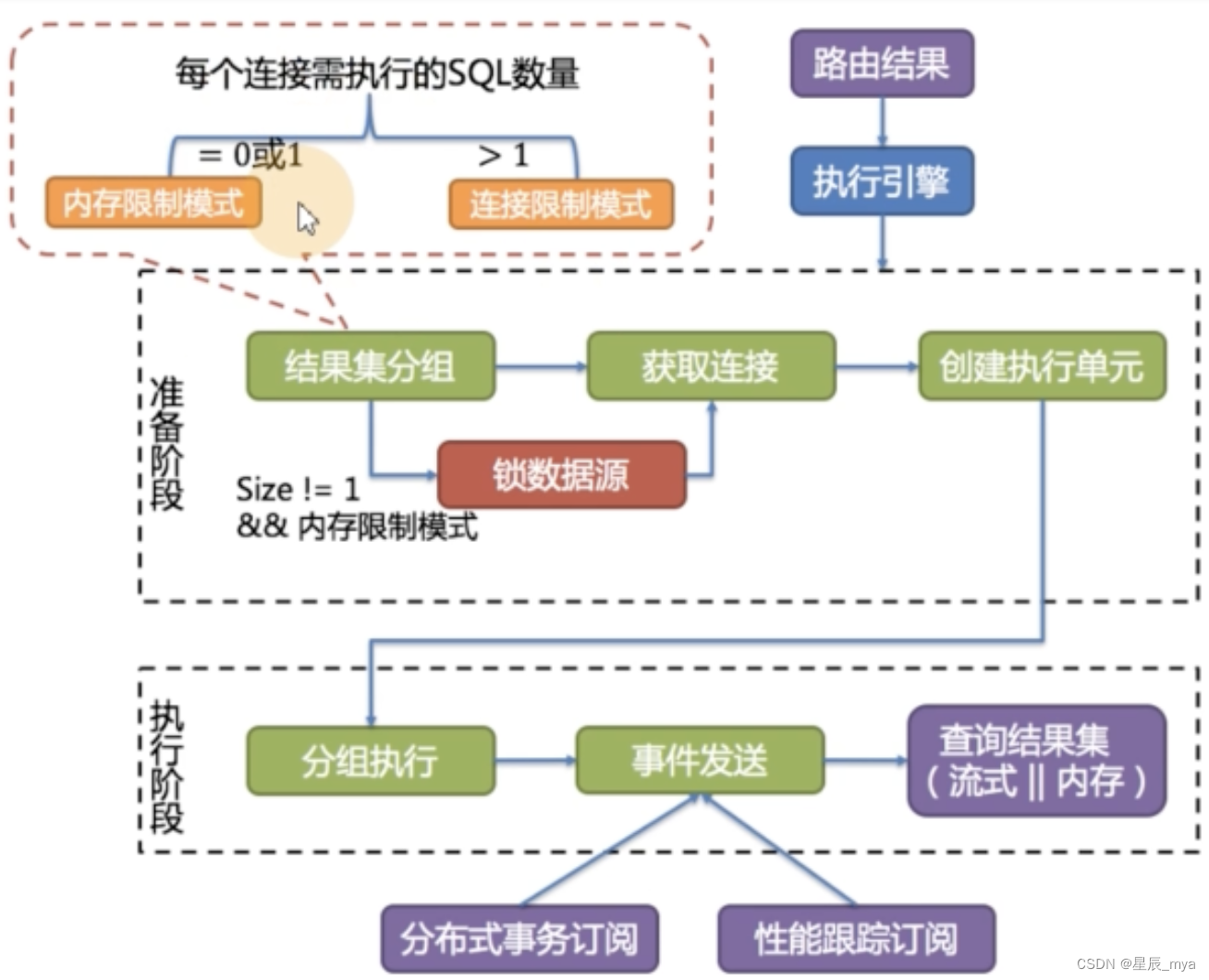
归并引擎

执行 归并返回
GTID同步集群
5.6引入,基于binlog实现主从同步,基于全局事务id标识同步进度
每一个在主节点提交读事务在复制集群中可生成一个唯一ID:递增
从服务器告诉主服务器已经在从服务器执行完了哪些事务的GTID,主库会把all没有在从库执行的事务发送到从库执行,使用GTID复制保证同一事务只在指定的从库上执行一次
唯一id
uuid / 数据库主键 / redis / mongodb / zk /雪花算法
初始值+步长 双主同步 延迟段时间再同步
快速查找数据
布隆过滤器 redis的bitmap结构实现布隆过滤器 建立缓存
这篇关于mysql颗粒归仓的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







