本文主要是介绍【海贼王的数据航海】排序——直接选择排序|堆排序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1 -> 选择排序
1.1 -> 基本思想
1.2 -> 直接选择排序
1.2.1 -> 代码实现
1.3 -> 堆排序
1.3.1 -> 代码实现

1 -> 选择排序
1.1 -> 基本思想
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
1.2 -> 直接选择排序
- 在元素集合arr[i] -- arr[n - 1]中选择关键码最大(或最小)的数据元素
- 若它不是这组元素中的最后一个(或第一个)元素,则将它与这组元素中的最后一个(或第一个)元素交换
- 在剩余的arr[i] -- arr[n - 2] (arr[i + 1] -- arr[n - 1]) 集合中,重复上述步骤,直到集合剩余1个元素
直接选择排序的特性总结:
- 好理解,但效率不是很好,实际中很少使用
- 时间复杂度:
- 空间复杂度:
- 稳定性:不稳定
1.2.1 -> 代码实现
#define _CRT_SECURE_NO_WARNINGS 1#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>// 交换
void Swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}// 打印
void PrintArray(int* a, int n)
{for (int i = 0; i < n; i++)printf("%d ", a[i]);printf("\n");
}// 选择排序
void SelectSort(int* a, int n)
{int begin = 0, end = n - 1;while (begin < end){int maxi = begin, mini = begin;for (int i = begin; i <= end; i++){if (a[i] > a[maxi]){maxi = i;}if (a[i] < a[mini]){mini = i;}}Swap(&a[begin], &a[mini]);// 如果maxi和begin重叠,修正一下即可if (begin == maxi){maxi = mini;}Swap(&a[end], &a[maxi]);++begin;--end;}
}void TestSelectSort()
{int a[] = { 9, 2, 6, 1, 7, 3 ,0, 5, 8, 4 };PrintArray(a, sizeof(a) / sizeof(int));SelectSort(a, sizeof(a) / sizeof(int));PrintArray(a, sizeof(a) / sizeof(int));
}int main()
{TestSelectSort();return 0;
}
1.3 -> 堆排序
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。它是通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。
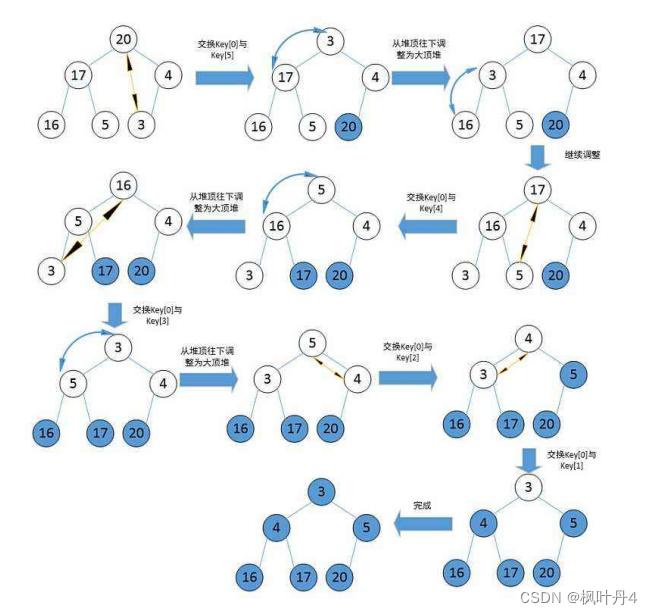
堆排序特性总结:
- 堆排序用堆来选数,效率较高
- 时间复杂度:
- 空间复杂度:
- 稳定性:不稳定
1.3.1 -> 代码实现
#define _CRT_SECURE_NO_WARNINGS 1#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>// 交换
void Swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}// 打印
void PrintArray(int* a, int n)
{for (int i = 0; i < n; i++)printf("%d ", a[i]);printf("\n");
}// 堆排序
void AdjustUp(int* a, int child)
{int father = (child - 1) / 2;while (child > 0){if (a[child] > a[father]){Swap(&a[child], &a[father]);//更新下标child = father;father = (father - 1) / 2;}else{break;//一旦符合小堆了,就直接退出}}
}void AdjustDown(int* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n){// 找出小的那个孩子if (child + 1 < n && a[child + 1] > a[child]){++child;}if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}// 排升序
void HeapSort(int* a, int n)
{// 建大堆for (int i = (n - 1 - 1) / 2; i >= 0; --i){AdjustDown(a, n, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
}void TestHeapSort()
{int a[] = { 9, 2, 6, 1, 7, 3 ,0, 5, 8, 4 };PrintArray(a, sizeof(a) / sizeof(int));HeapSort(a, sizeof(a) / sizeof(int));PrintArray(a, sizeof(a) / sizeof(int));
}int main()
{TestHeapSort();return 0;
}
感谢大佬们的支持!!!
互三啦!!!
这篇关于【海贼王的数据航海】排序——直接选择排序|堆排序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






