本文主要是介绍【InternLM 实战营笔记】基于 InternLM 和 LangChain 搭建MindSpore知识库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
InternLM 模型部署
准备环境
拷贝环境
/root/share/install_conda_env_internlm_base.sh InternLM激活环境
conda activate InternLM安装依赖
# 升级pip
python -m pip install --upgrade pippip install modelscope==1.9.5
pip install transformers==4.35.2
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.24.1模型下载
mkdir -p /root/data/model/Shanghai_AI_Laboratory
cp -r /root/share/temp/model_repos/internlm-chat-7b /root/data/model/Shanghai_AI_Laboratory/internlm-chat-7bLangChain 相关环境配置
pip install langchain==0.0.292
pip install gradio==4.4.0
pip install chromadb==0.4.15
pip install sentence-transformers==2.2.2
pip install unstructured==0.10.30
pip install markdown==3.3.7同时,我们需要使用到开源词向量模型 Sentence Transformer:(我们也可以选用别的开源词向量模型来进行 Embedding,目前选用这个模型是相对轻量、支持中文且效果较好的,同学们可以自由尝试别的开源词向量模型)
首先需要使用 huggingface 官方提供的 huggingface-cli 命令行工具。安装依赖:
pip install -U huggingface_hub然后在和 /root/data 目录下新建python文件 download_hf.py,填入以下代码: resume-download:断点续下 local-dir:本地存储路径。(linux环境下需要填写绝对路径)
import os# 下载模型
os.system('huggingface-cli download --resume-download --local-dir-use-symlinks False sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/data/model/sentence-transformer')如果下载速度慢可以使用镜像下载将 download_hf.py 中的代码修改为以下代码:
import os# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'# 下载模型
os.system('huggingface-cli download --resume-download --local-dir-use-symlinks False sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/data/model/sentence-transformer')执行脚本
python download_hf.py下载 NLTK 相关资源
下载
cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip知识库搭建
数据收集
选择mindspre docs代码仓作为语料库来源 地址: https://gitee.com/mindspore/docs
# 进入到数据库盘
cd /root/data
# clone 上述开源仓库
git clone https://gitee.com/mindspore/docs.git知识库搭建的脚本
# 首先导入所需第三方库
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from tqdm import tqdm
import os# 获取文件路径函数
def get_files(dir_path):# args:dir_path,目标文件夹路径file_list = []for filepath, dirnames, filenames in os.walk(dir_path):# os.walk 函数将递归遍历指定文件夹for filename in filenames:# 通过后缀名判断文件类型是否满足要求if filename.endswith("_CN.md"):# 如果满足要求,将其绝对路径加入到结果列表file_list.append(os.path.join(filepath, filename))elif filename.endswith("_CN.txt"):file_list.append(os.path.join(filepath, filename))return file_list# 加载文件函数
def get_text(dir_path):# args:dir_path,目标文件夹路径# 首先调用上文定义的函数得到目标文件路径列表file_lst = get_files(dir_path)# docs 存放加载之后的纯文本对象docs = []# 遍历所有目标文件for one_file in tqdm(file_lst):file_type = one_file.split('.')[-1]if file_type == 'md':loader = UnstructuredMarkdownLoader(one_file)elif file_type == 'txt':loader = UnstructuredFileLoader(one_file)else:# 如果是不符合条件的文件,直接跳过continuedocs.extend(loader.load())return docs# 目标文件夹
tar_dir = ["/root/data/docs"
]# 加载目标文件
docs = []
for dir_path in tar_dir:docs.extend(get_text(dir_path))# 对文本进行分块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)# 加载开源词向量模型
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")# 构建向量数据库
# 定义持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma.from_documents(documents=split_docs,embedding=embeddings,persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
# 将加载的向量数据库持久化到磁盘上
vectordb.persist()可以在 /root/data 下新建一个 demo目录,将该脚本和后续脚本均放在该目录下运行。运行上述脚本,即可在本地构建已持久化的向量数据库,后续直接导入该数据库即可,无需重复构建。
InternLM 接入 LangChain
脚本
from langchain.llms.base import LLM
from typing import Any, List, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun
from transformers import AutoTokenizer, AutoModelForCausalLM
import torchclass InternLM_LLM(LLM):# 基于本地 InternLM 自定义 LLM 类tokenizer : AutoTokenizer = Nonemodel: AutoModelForCausalLM = Nonedef __init__(self, model_path :str):# model_path: InternLM 模型路径# 从本地初始化模型super().__init__()print("正在从本地加载模型...")self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)self.model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True).to(torch.bfloat16).cuda()self.model = self.model.eval()print("完成本地模型的加载")def _call(self, prompt : str, stop: Optional[List[str]] = None,run_manager: Optional[CallbackManagerForLLMRun] = None,**kwargs: Any):# 重写调用函数system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文."""messages = [(system_prompt, '')]response, history = self.model.chat(self.tokenizer, prompt , history=messages)return response@propertydef _llm_type(self) -> str:return "InternLM"将上述代码封装为 LLM.py,后续将直接从该文件中引入自定义的 LLM 类。
构建检索问答链
整体脚本
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import os# 定义 Embeddings
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")# 向量数据库持久化路径
persist_directory = 'data_base/vector_db/chroma'# 加载数据库
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embeddings
)from LLM import InternLM_LLM
llm = InternLM_LLM(model_path = "/root/data/model/Shanghai_AI_Laboratory/internlm-chat-7b")
llm.predict("你是谁")from langchain.prompts import PromptTemplate# 我们所构造的 Prompt 模板
template = """使用以下上下文来回答用户的问题。如果你不知道答案,就说你不知道。总是使用中文回答。
问题: {question}
可参考的上下文:
···
{context}
···
如果给定的上下文无法让你做出回答,请回答你不知道。
有用的回答:"""# 调用 LangChain 的方法来实例化一个 Template 对象,该对象包含了 context 和 question 两个变量,在实际调用时,这两个变量会被检索到的文档片段和用户提问填充
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)from langchain.chains import RetrievalQAqa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})# 检索问答链回答效果
question = "什么是MindSpore"
result = qa_chain({"query": question})
print("检索问答链回答 question 的结果:")
print(result["result"])# 仅 LLM 回答效果
result_2 = llm(question)
print("大模型回答 question 的结果:")
print(result_2)部署 Web Demo
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import os
from LLM import InternLM_LLM
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQAdef load_chain():# 加载问答链# 定义 Embeddingsembeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")# 向量数据库持久化路径persist_directory = 'data_base/vector_db/chroma'# 加载数据库vectordb = Chroma(persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上embedding_function=embeddings)# 加载自定义 LLMllm = InternLM_LLM(model_path = "/root/data/model/Shanghai_AI_Laboratory/internlm-chat-7b")# 定义一个 Prompt Templatetemplate = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答案。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。{context}问题: {question}有用的回答:"""QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)# 运行 chainqa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})return qa_chainclass Model_center():"""存储检索问答链的对象 """def __init__(self):# 构造函数,加载检索问答链self.chain = load_chain()def qa_chain_self_answer(self, question: str, chat_history: list = []):"""调用问答链进行回答"""if question == None or len(question) < 1:return "", chat_historytry:chat_history.append((question, self.chain({"query": question})["result"]))# 将问答结果直接附加到问答历史中,Gradio 会将其展示出来return "", chat_historyexcept Exception as e:return e, chat_historyimport gradio as gr# 实例化核心功能对象
model_center = Model_center()
# 创建一个 Web 界面
block = gr.Blocks()
with block as demo:with gr.Row(equal_height=True): with gr.Column(scale=15):# 展示的页面标题gr.Markdown("""<h1><center>InternLM</center></h1><center>书生浦语</center>""")with gr.Row():with gr.Column(scale=4):# 创建一个聊天机器人对象chatbot = gr.Chatbot(height=450, show_copy_button=True)# 创建一个文本框组件,用于输入 prompt。msg = gr.Textbox(label="Prompt/问题")with gr.Row():# 创建提交按钮。db_wo_his_btn = gr.Button("Chat")with gr.Row():# 创建一个清除按钮,用于清除聊天机器人组件的内容。clear = gr.ClearButton(components=[chatbot], value="Clear console")# 设置按钮的点击事件。当点击时,调用上面定义的 qa_chain_self_answer 函数,并传入用户的消息和聊天历史记录,然后更新文本框和聊天机器人组件。db_wo_his_btn.click(model_center.qa_chain_self_answer, inputs=[msg, chatbot], outputs=[msg, chatbot])gr.Markdown("""提醒:<br>1. 初始化数据库时间可能较长,请耐心等待。2. 使用中如果出现异常,将会在文本输入框进行展示,请不要惊慌。 <br>""")
gr.close_all()
# 直接启动
demo.launch()通过将上述代码封装为 run_gradio.py 脚本,直接通过 python 命令运行,即可在本地启动知识库助手的 Web Demo,默认会在 7860 端口运行,接下来将服务器端口映射到本地端口即可访问:
运行效果
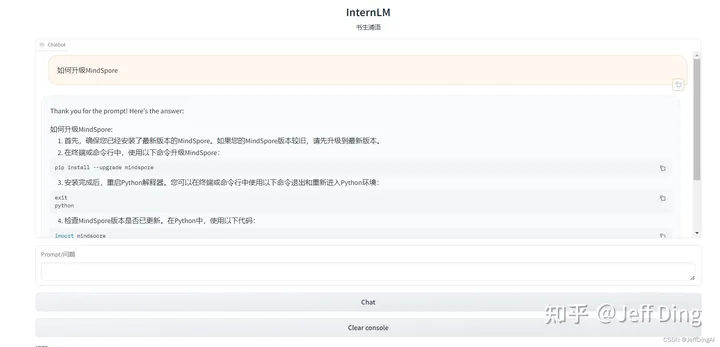
这篇关于【InternLM 实战营笔记】基于 InternLM 和 LangChain 搭建MindSpore知识库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






