本文主要是介绍性能优化—TraceView,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
两篇文章一起看,基本就懂了
https://blog.csdn.net/yinzhijiezhan/article/details/80167283
https://www.jianshu.com/p/8a24bfb4b0d6
一、TraceView的用处
TraceView用于分析计算性能,流入某个方法过于耗时导致UI卡顿,或者某个方法调用次数过多,或者某个方法虽然并不占用太多内存但是占用了大量的CPU资源等等。
二、获取TraceView文件的三种方式
1:方式一:通过代码获取
case R.id.bt_trace_view:Debug.startMethodTracing("custom");startTrace();Debug.stopMethodTracing();Utils.showToast(this, "成功");break;
a:在你想要检测的某段代码的开始位置调用
Debug.startMethodTracing("custom");
其中custom可根据需要自定义,其实就是生成的TraceView文件的文件名,例如custom.trace
b:在你想要检测的某段代码的结束位置调用
Debug.stopMethodTracing();
结束检测没有参数。
注意:这两行代码要在同一个线程成对出现。
c:通过以上设置运行代码后就会在手机里生成/sdcard/custom.trace文件
d:然后通过adb pull /sdcard/custom.trace D:\folder命令将custom.trace导出到指定目录。

后面会着重讲打开.trace文件且分析.trace文件的方法。
2:方式二:通过Android Studio的Monitor的CPU模块生成
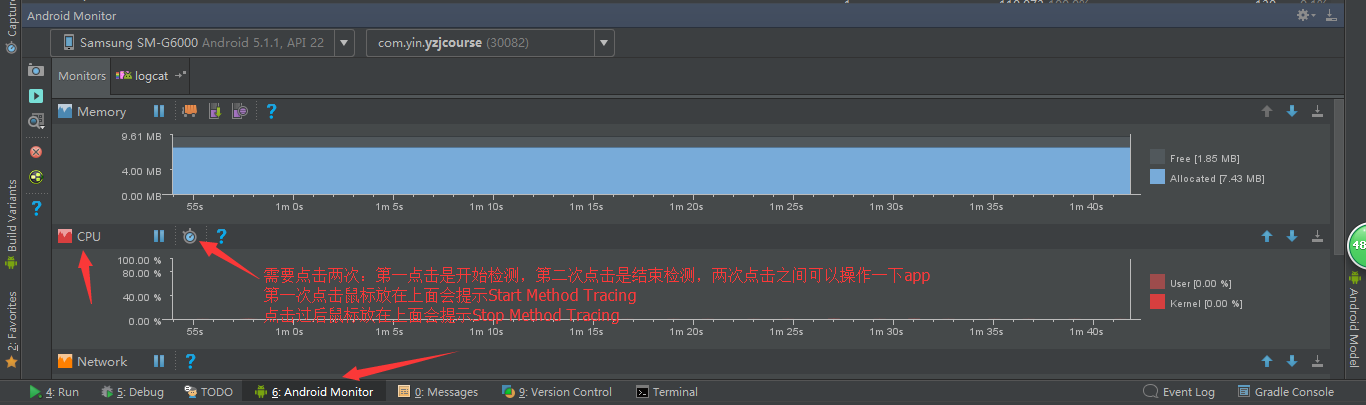
a:保持app在运行状态,在你要开始检测某个功能时点击一下按钮Start Method Tracing;
b:根据需要操作一下app,再点击该按钮Stop Method Tracing,则检测区间结束,Studio会打开.trace文件的查看窗口,
这个.trace文件在你app项目的captures目录下。
c:这个窗口界面并不友好,也不好用,我们不直接观察这个界面,所以我们像方式一一样将这个.trace文件保存到某个目录。
这里为了和上面的方式一统一,我也把这个文件保存到D:\folder,并且重命名为custom.trace文件。
后面会着重讲打开.trace文件且分析.trace文件的方法。
3:通过Tools --> Android --> Android Device Monitor获取
a:通过Tools --> Android --> Android Device Monitor路径进入,然后参考下图开始分析;
b:操作一会app后参考下图结束分析你刚才的操作执行的代码;
c:分析完成后会打开.trace文件如下图,这个界面的底部的搜索功能不可用,而且我们经常需要搜索功能,所以我的习惯也是
不采用这种方式产生的.trace文件。
到此,三种获取.trace文件的方式讲完了,第一种方式和第二种方式我们都获取到了.trace文件,第三种方式我一般不采用。
三:分析trace文件
前面讲到的方式一方式二我们获取到了.trace,下面讲解如果打开并分析该.trace文件
要打开.trace文件就用到了sdk目录下的D:\sdk\tools\traceview.bat工具,通过如下命令就打开.trace文件并进入分析界面
由于通常我们的业务代码比较复杂,产生的.trace文件也很复杂不方便我们学习,所以这里我自己写一段非常简单的代码并通过前面方式一讲到的通过代码的方式获取.trace文件来讲解。
private void test() {Debug.startMethodTracing("custom");startTrace();Debug.stopMethodTracing();Utils.showToast(this, "成功");
}/*** jie1()和jie2()没有调用关系是兄弟关系*/
private void startTrace() {jie1();jie2();
}/*** jie2()中两次调用jie3(),其中jie3(0)直接return,不产生递归也不会调用jie4()* jie3(3)会先调用一次jie4()再产生3次递归调用*/
private void jie2() {jie3(0);jie3(3);
}private void jie3(int count) {if (count == 3) {jie4();}if (count == 0) {return;} else {jie3(count - 1);}
}/*** 故意做比较耗时的操作:用于区分Excl和Incl的关系*/
private void jie4() {for (int i = 0; i < 15; i++) {for (int j = 0; j < 15; j++) {int k = i + j;}}
}private void jie1() {}
这段代码对应的.trace文件如下图
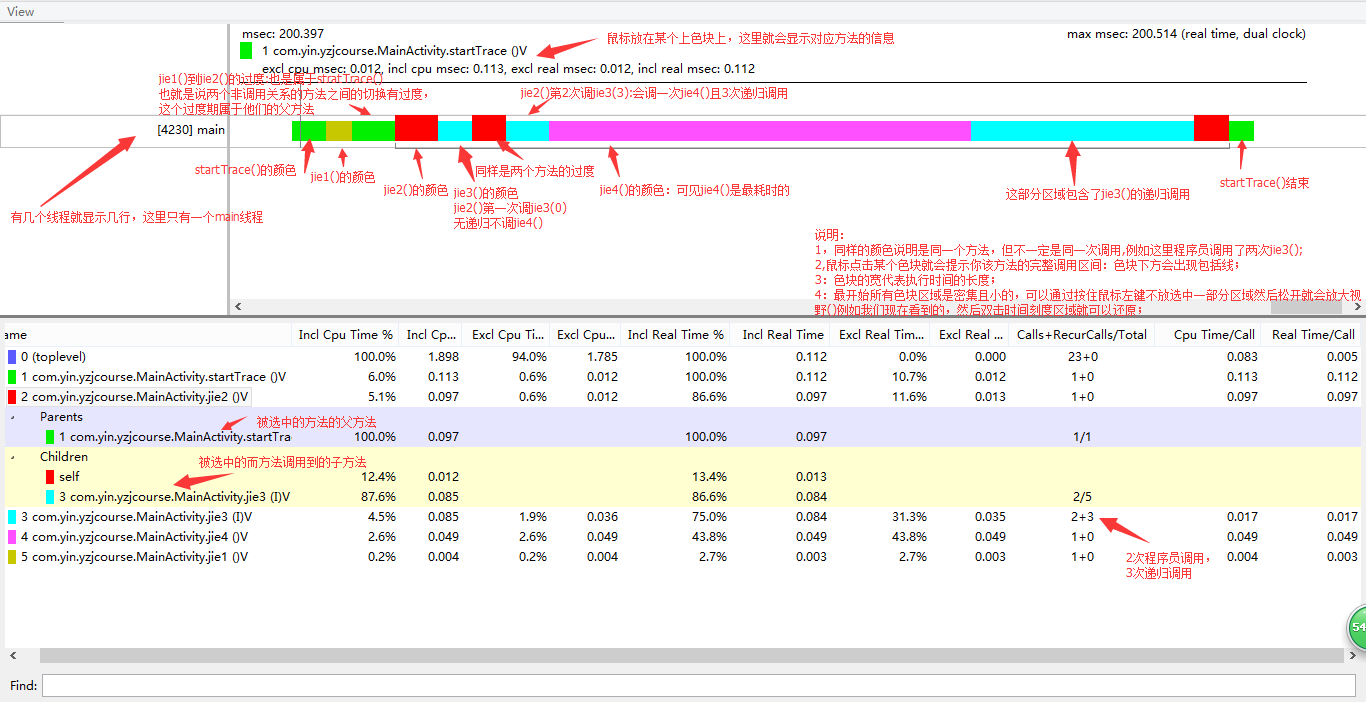
其中各个字段的说明:
Incl Cpu Time%
Incl Cpu Time
某函数占用的CPU时间,包含内部调用其它函数的CPU时间
Excl Cpu Time%
Excl Cpu Time
某函数占用的CPU时间,但不含内部调用其它函数所占用的CPU时间
结论:父方法的Incl Cpu Time = 父方法的Excl Cpu Time + 子方法的Incl Cpu Time.... 省略号说明一个方法可以调用多个方法
Incl Real Time%
Incl Real Time
某函数运行的真实时间(以毫秒为单位),内含调用其它函数所占用的真实时间
Excl Real Time%
Excl Real Time
某函数运行的真实时间(以毫秒为单位),不含调用其它函数所占用的真实时间
结论:父方法的Incl Real Time = 父方法的Excl Real Time + 子方法的Incl Real Time....省略号说明一个方法可以调用多个方法
Call+Recur Calls/Total
没展开某个方法时:
会显示该方法被程序员主动调用次数,以及被自身递归调用次数;例如:2+3,程序员调用两次,自己递归调用3次
展开某个方法时:
父方法会显示:其调用(程序员主动调用,非递归)该方法的次数/该方法的总次数,例如:2/5,说明该方法总共被调用5次其中父方法主动调了他2次
子方法会显示:子方法被其调用(程序员主动调用)的次数/子方法被调用的总次数,例如1/5
注意:这里的程序员主动调用是指,你看到的代码调用了几次就是几次,并不包括代码运行中的递归
例如funcA(){
funcD();
funcB();
funcB();
}
这里程序员主动调用了两次funcB()一次funcD(),并没有管funcB()有没有递归的情况。
再例如funcB(){
funcB();
funcB();
}
这里funcB()产生了递归,但是程序员在funcB()中只主动调用了2次funcB();不管funcB()递归了多少次。
Cpu Time/Call
某函数的Incl Cpu Time与调用次数的比。相当于该函数平均执行时间,注意不是Excl Cpu Time;
Real Time/Call
某函数的Incl Real Time与调用次数的比。相当于该函数平均执行时间,注意不是Excl Real Time;
注意:这些列可以左右拖动调换位置
通过对TraceView文件的分析,如果发现某个方法运行时间明显过长或者调用次数异常过多,则就存在优化的可能
这篇关于性能优化—TraceView的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






