本文主要是介绍openstack ice版availability zones host aggregates 实战详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
感谢朋友支持本博客,欢迎共同探讨交流,由于能力和时间有限,错误之处在所难免,欢迎指正!
如有转载,请保留源作者博客信息。
如需交流,欢迎大家博客留言。
1、availability zones
| openstack 从G版本开始废除了之前版本使用的availability zones配置功能:(数据库中也不再保留availability zones字段)
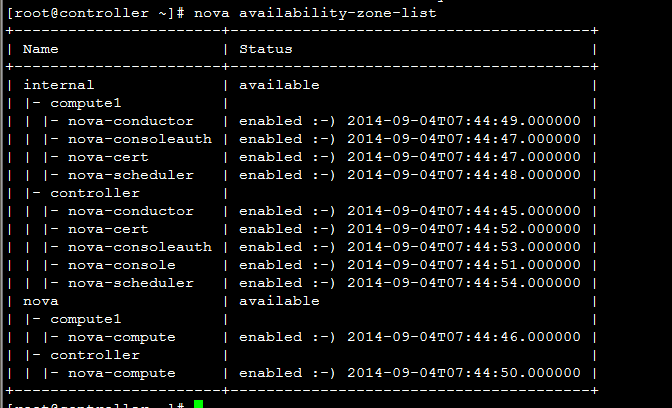
G版之后,默认情况下,对Nova服务分为两类, 一类是controller节点的服务进程,如nova-api, nova-scheduler, nova-conductor等;另一类是计算节点进程,nova-compute。 对于第一类服务,默认的zone是配置项internal_service_availability_zone, 而nova-compute所属的zone由配置项default_availability_zone决定。所以,一个新的环境,我们看到的服务如下: 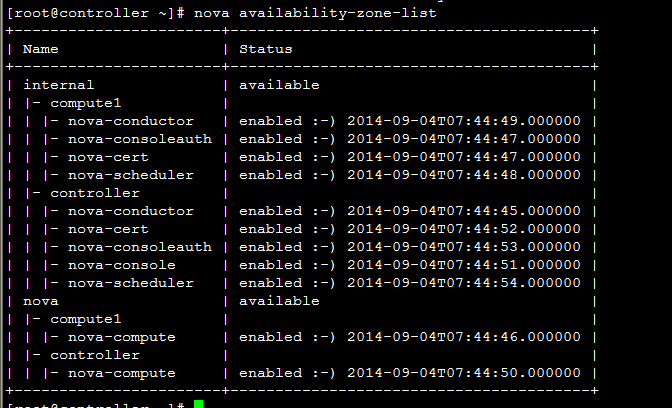 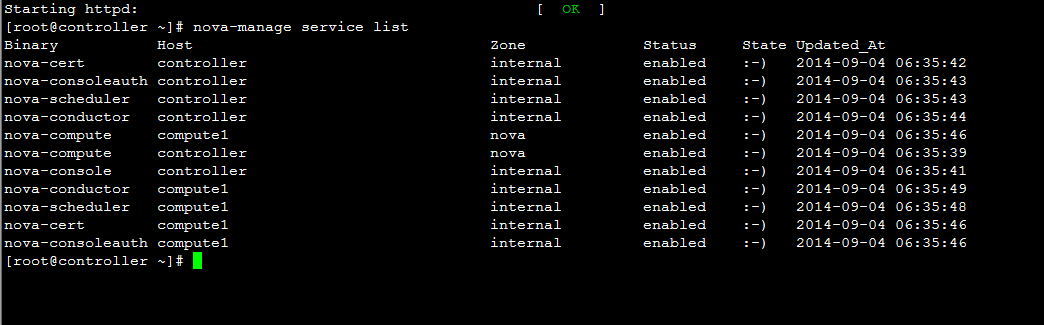 |
因此在后续版本中,将不能直接使用配置文件的availability zones作为调度算法的资源隔离手段。
那后续版本又该如何实现前面版本的availability zones功能呢?
在新版中增加了aggregate的概念,具体来讲aggregate是availability_zones的细分。具体关于availability_zones aggregate参考下图(下图设计概念比较多,后面有时间再一个个慢慢分析):
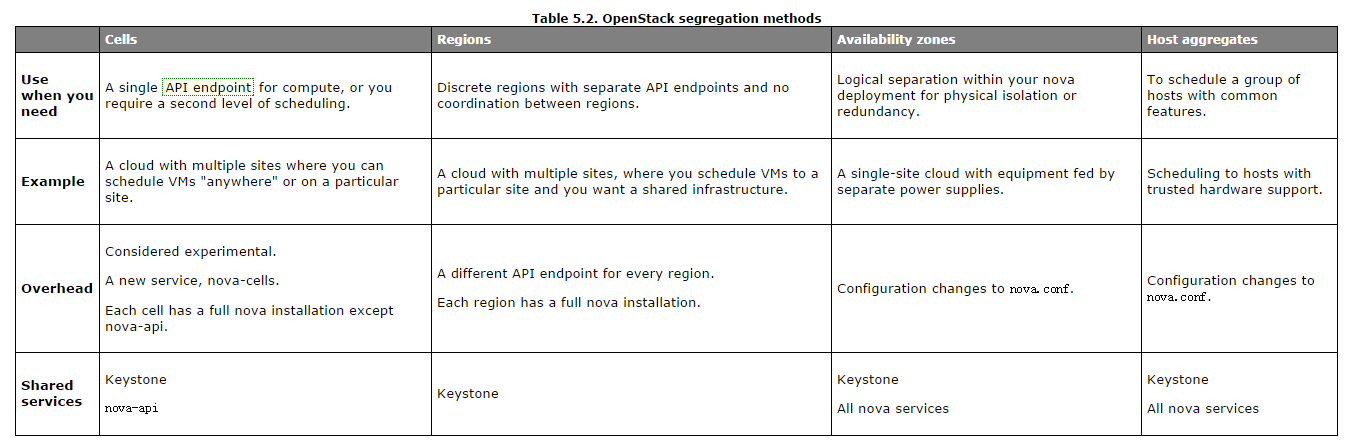
| 简单说明:有上图可以看出资源隔离、可以由cells、regions、available zone、host aggregates实现。 |
那为什么后续版本要废除之前的availability_zones功能呢,带着疑问继续前行ing...
| ps:由于大部分同学都是后续加入openstack开发团队的,因此有必要讲解下G版本之前availability_zones功能:
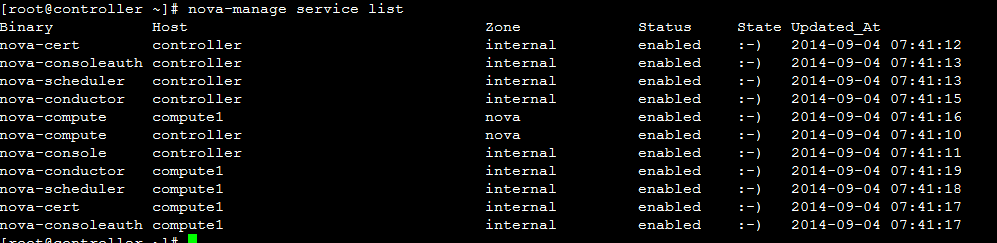
在控制节点执行命令: nova-manage service list 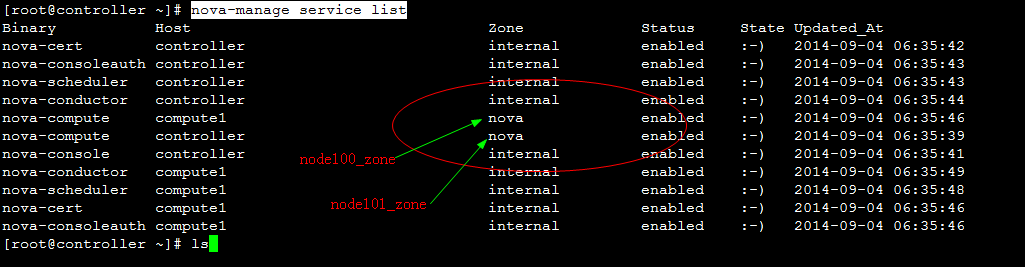 即下图这样(此图从别处复制): 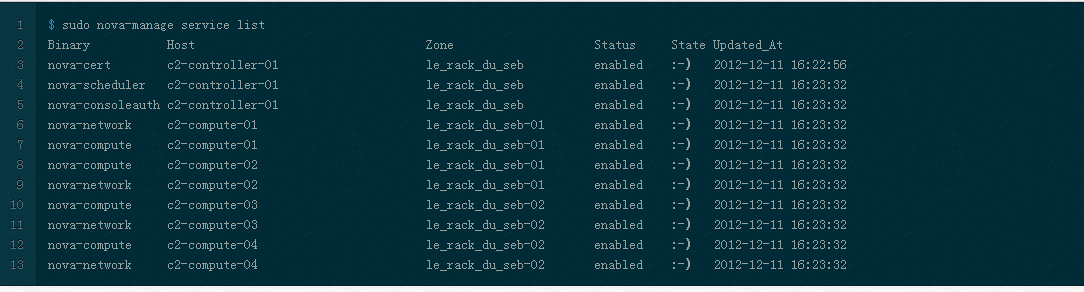 由于笔者手中没有openstack的老环境,所以用ice版的做标注,呈现老版。 也就是说:计算节点 availability_zones配置的值为多少这边zone的列则展示为多少。与ice版差别太明显了。ice 的zone的值如何得来,请自行参考前文讲解的" ice版nova-manage service list 中zone列值来由 "。 大家可能有疑问了, node100_zone、 node101_zone这些值从哪里来? 这些值从nova数据库来,只是新版中没有采用这套机制把保存这些记录的字段给废除了。 最后直观讲解下老版的 availability_zones如何使用: 截图dashboard生成虚拟机form表单项页: 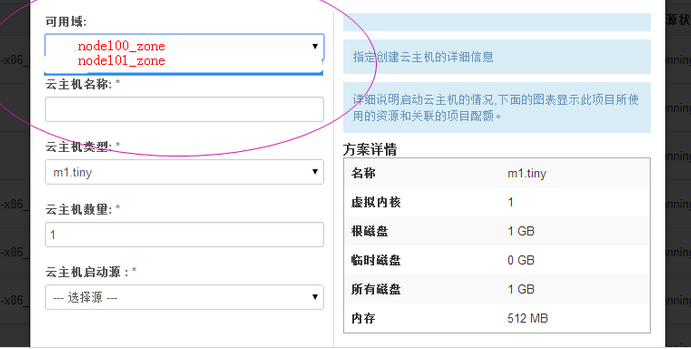 也就是说在生成虚拟机时候可以选择将虚拟机生成在哪个 availability_zones上面,通过页面将 availability_zones传送到底层调度模块,调度模块根据此参数生成虚拟机到制定的区域。(关于早期版本的调度模块实现机制,请自行参考博文: 创建instance调度算法解析及自定义调度算法-openstack E版 ) 那接下来看下ice版本的页面: 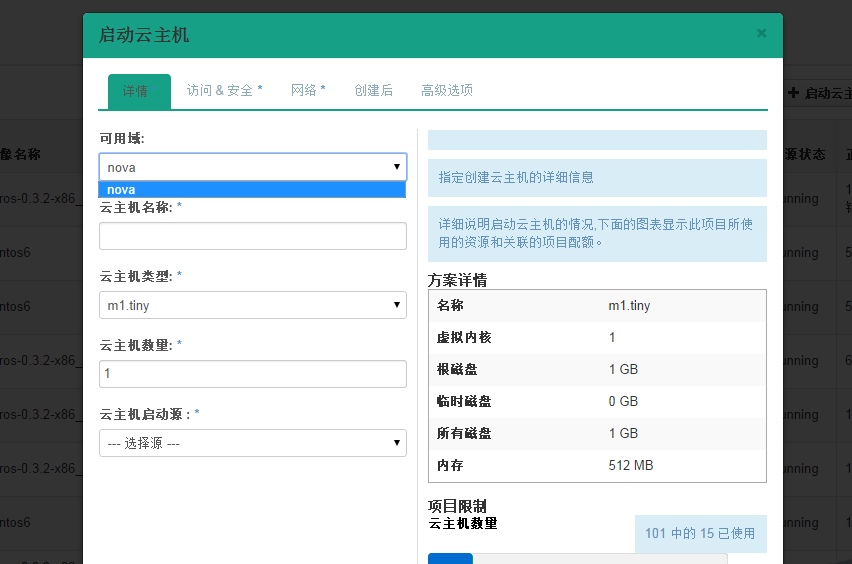 可以发现新版的可用域只有nova一个选项。 对比了新老版本对 availability_zones的不同处理机制,接下来分析 aggregate。 |
2、aggregate
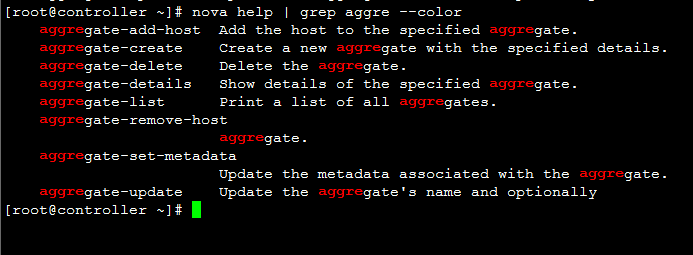   创建一个 aggregate:
 此处可以得出 availability_zones可以有自己自定义,无需关心配置文件。 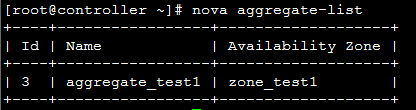 添加主机到 aggregate_test1: 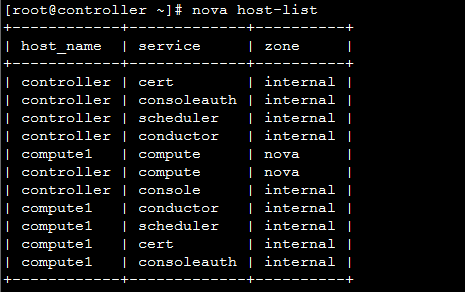
 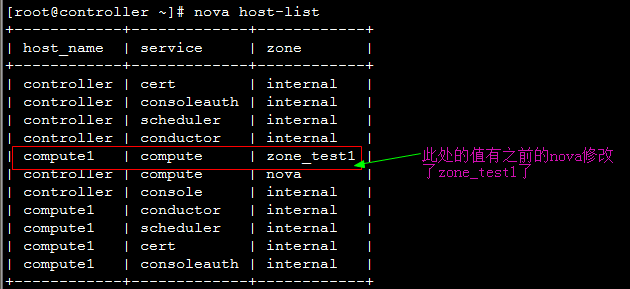 回到页面: 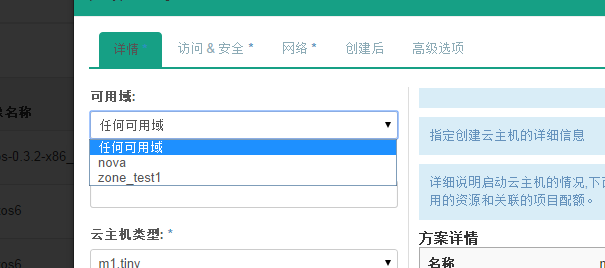 发现先添加的zone_test1出现在可选域中。 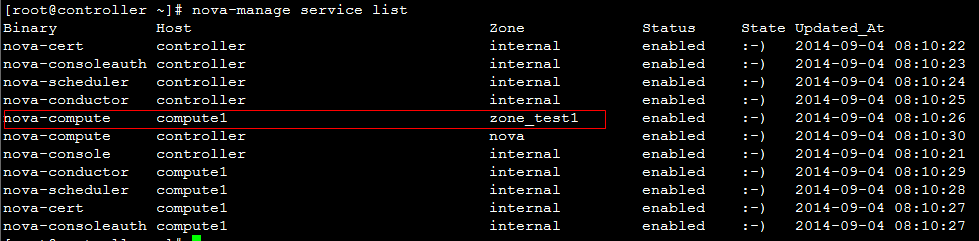 继续将另一个计算节点zone修改:   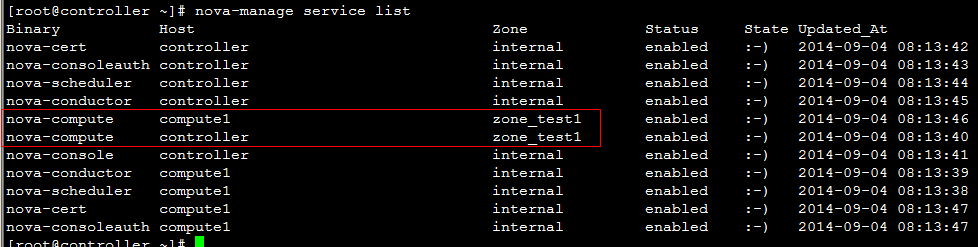 回到页面: 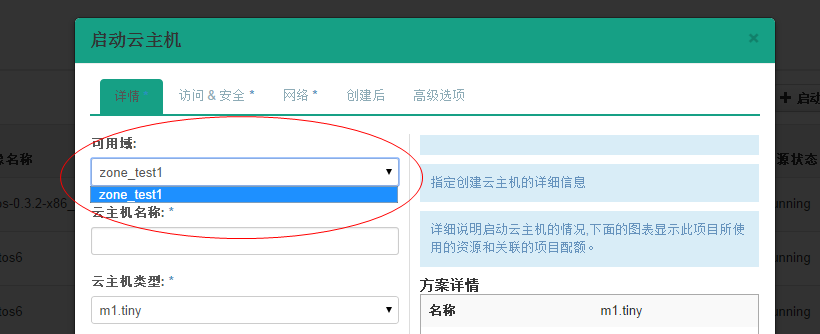 发现可用域里面只有zone_test1,因此可以发现,页面展示的不是针对 aggregate而是 availability_zones。 接下来试验将两个计算节点分属于不通的 availability_zones中:   发现已经存在自定义zone中的host需要先remove掉,才能添加到新的zone里面:   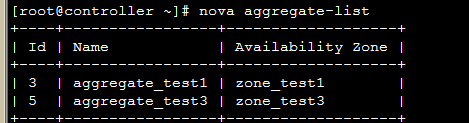 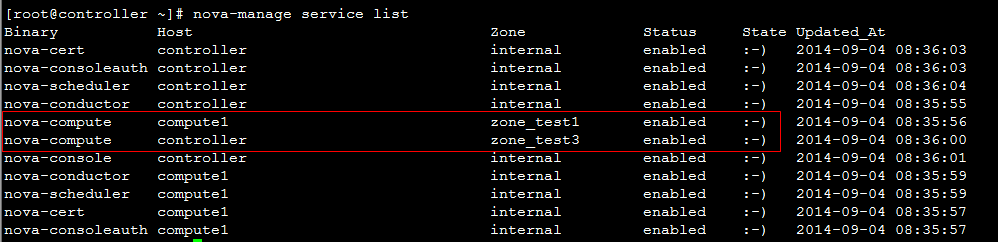 回到页面: 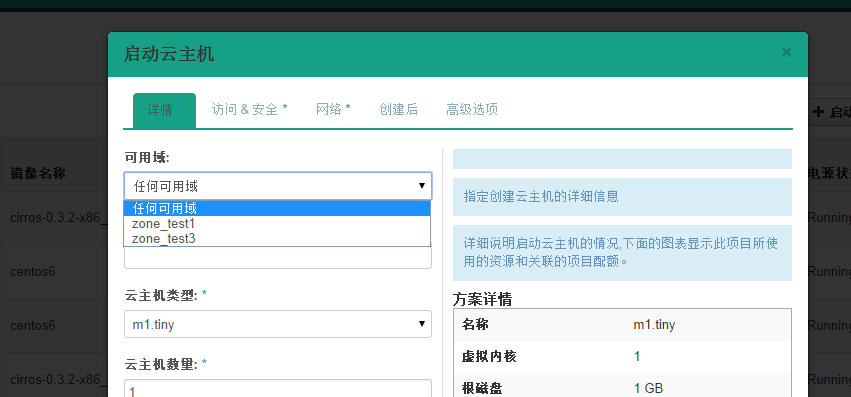 测试调度算法是否会将虚拟机生成到指定的zone: 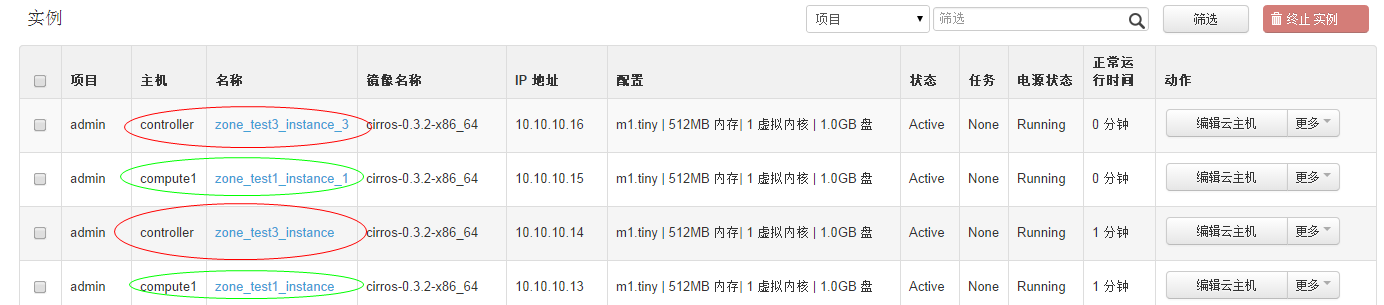 测试结果与预期相符,能够根据指定域里面的aggregate host进行资源分配。 总结:ice版本通过aggregate host与zones进行绑定从而达到了老版本的zones功能。不知道大家有发现新版相知于老版本的优点么。。。 新版本不再需要自己去修改配置文件来配置zones、可以直接通过命令行的形式实现,当然后期也可以自己将命令扩展集成至页面进行动态配置。 ice版本中已经集成了管理zone和aggregate的机制:  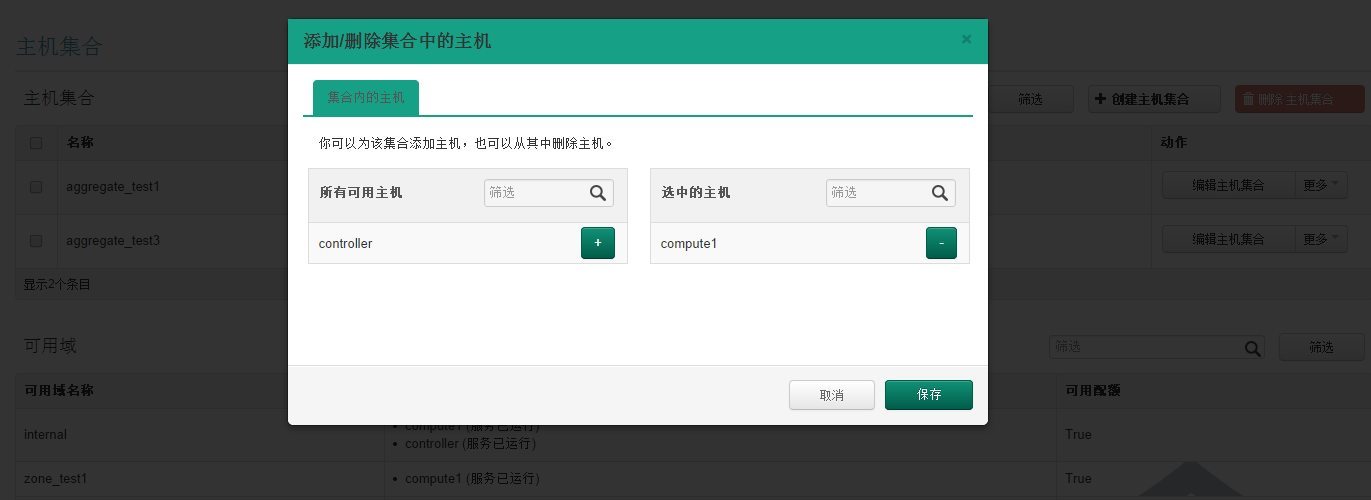 当然上述所有对zones和aggregates命令操作都可以在dashboard上面完成。 本文分析到此结束,后续将继续分析openstack ice版 aggregates在调度算法中的具体控制实现、以及cells, regions实战详解 |
这篇关于openstack ice版availability zones host aggregates 实战详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







