本文主要是介绍数字多空策略(实盘+回测+数据),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

数量技术宅团队在CSDN学院推出了量化投资系列课程
欢迎有兴趣系统学习量化投资的同学,点击下方链接报名:
量化投资速成营(入门课程)
Python股票量化投资
Python期货量化投资
Python数字货币量化投资
C++语言CTP期货交易系统开发
数字货币JavaScript语言量化交易系统开发
技术宅此前分享的数字策略多为单边策略。单边策略最大的特征是在承担一定的波动风险前提下获取高收益率。而对于许多稳健的、中、低风险偏好的投资者来说,在承担尽可能小的波动风险前提下,获取尽可能高的收益率,是他们追求的目标。
本期,我们将推出一期同时兼顾低风险和高收益的优质策略:数字货币多空策略。策略不受整个数字货币市场涨跌的影响、回撤小同时长期运行也有极高的收益率,让我们一起来看看吧!
策略逻辑
首先,我们简要介绍“数字货币多空策略”的策略逻辑:
随着交易所挂牌交易的合约数量不断增加,同时合约相互间相关性不断降低,有更多的币种不与BTC、ETH等主流币同涨同跌,呈现涨跌分化的状态,因此每天都有不同币种的做多、做空机会。下图是我们随机选取某天币安所有U本位合约的涨跌幅排序,可以看出币种涨跌分化很明显,涨幅排名第一的ICPUSDT和跌幅排名第一的BSVUSDT的24h涨跌幅差距超过40%,而涨幅排名前5名币种的24h涨跌幅差距也超过20%,多空分化产生的交易机会很多、价差收益也很可观。

那么,问题的关键就在如何有效筛选出多空分化的币种,从而实现合约的价差收益。我们通过全量历史数据+海量因子筛选测试,最终确定了三个最有效的信号因子,以及之对应的三个多空策略,每个多空策略的多空币种市值相当,实现了方向上的完全对冲,不受整个数字货币市场涨跌的影响,能够在低风险的前提下,有效赚取币种间的相对强弱收益。
三个策略的目标执行周期不同,因此在捕捉行情的时间维度上也有一定的分散度。三策略既可以单策略独立运行,也可以三策略组合运行。组合运行的策略收益更稳定、回撤更小。
回测绩效
三策略通用测试参数:测试周期从2020-1-1测试到2023年末共计4年时间;交易成本按照单次多空交易千分之二扣除(足够覆盖交易手续费与盘口价差成本);测试杠杆采用2倍杠杆;单利测试。
我们先分别看三策略单策略绩效:
策略一:累积收益率超过17.5倍,年化收益率超过437.5%,单次多空交易利润3.7%,最大回撤率<20%。

策略二:累积收益率同样超过17.5倍,年化收益率超过437.5%,单次多空交易利润2.6%,最大回撤率<25%
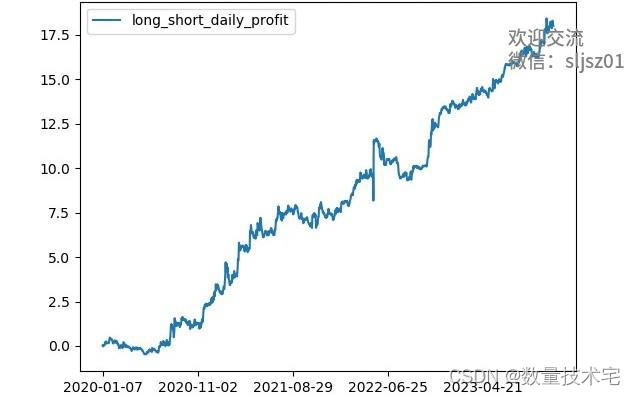
策略三:累积收益率超过16倍,年化收益率超过400%,单次多空交易利润1.4%,最大回撤率<15%

再来看组合绩效,组合绩效是同时运行三个多空策略所产生的效果,组合策略累积收益率同样超过17.5倍,年化收益率超过437.5%,单次多空交易利润2.5%,最大回撤率<15%。可以看出,组合策略在实现不低于单策略收益率的同时,最大回撤率更低,运行也更稳健,真正创造了低风险、高收益的特征。

通过历史测试可以看到,多空策略在低风险的环境下,在2倍杠杆的条件下,实现了年均超4倍的利润,其盈利能力完全不低于目前市场中的大多数单边策略。
实盘业绩
我们根据回测确定的最佳三策略组合,并编写了实盘交易系统。并在测试账户进行为期两个半月多的实盘交易(同样采用2倍杠杆),累积产生了超过150%的收益率!(ps:尽管BTC处于大牛市,策略仍大幅跑赢BTC涨幅),实盘业绩曲线如下。
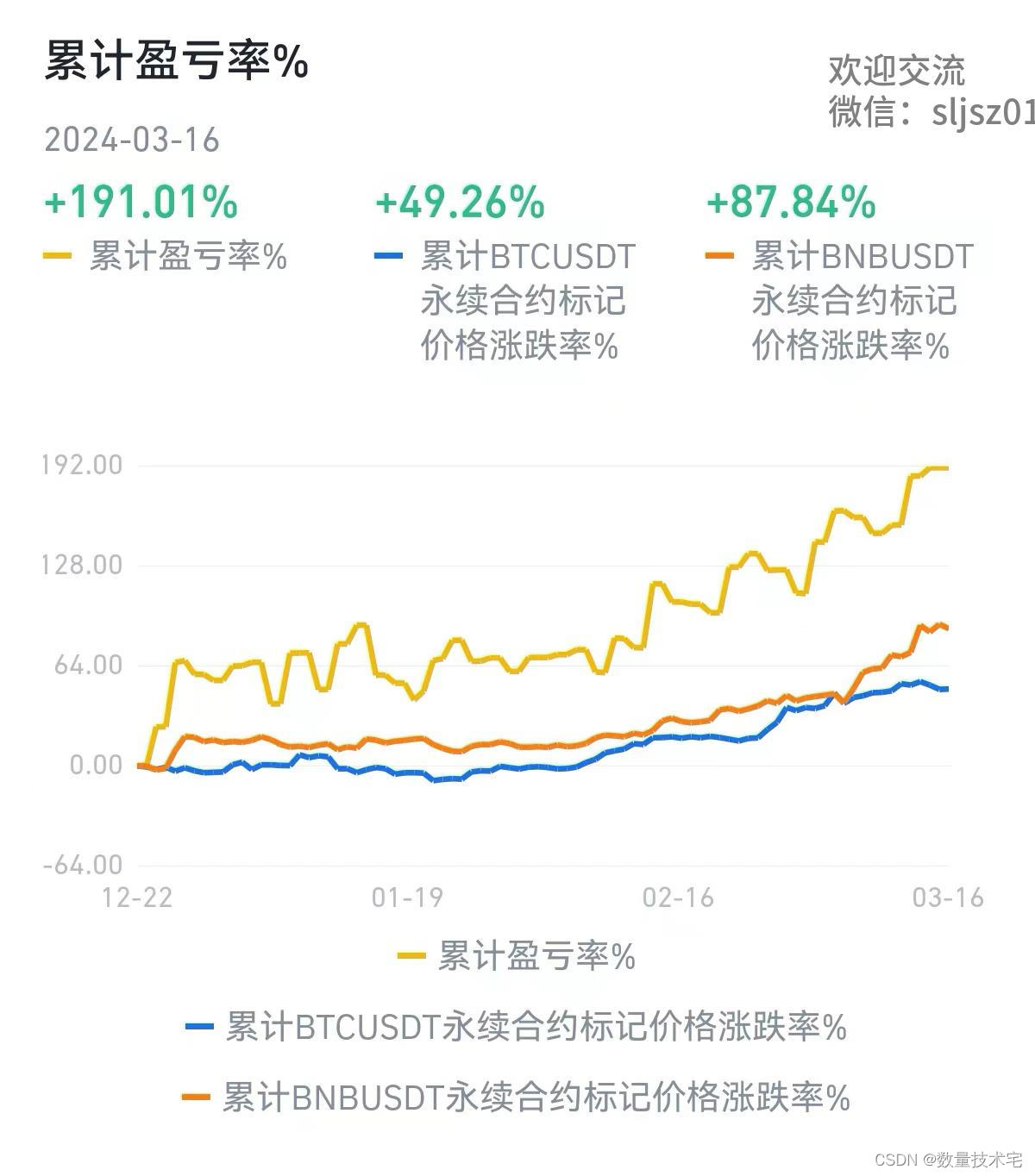
附上部分随机截取实盘交易记录:

至此,数字多空策略通过实盘业绩验证。
这篇关于数字多空策略(实盘+回测+数据)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





