本文主要是介绍kubernetes-服务-ipvs-调度算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
kubernetes-服务-ipvs-调度算法
- kubernetes-6
- 1、kubernetes中的网络通信插件
- 1.1、calico
- 1.2、flannel
- 2、service服务
- 2.1、服务暴露/发现
- 2.2、体验操作
- 2.3、这个体验的流程图和解释
- 3、ipvs
- 3.1、理解
- 3.2、负载均衡的软件:LVS
- 3.2.1、LVS的nat模式
- 3.2.2、DR模式
- 3.2.3、TUN模式-隧道模式
- 3.3、查看ipvs命令
- 4、调度算法
- 5、iptables和ipvs做负载均衡的时候,哪些性能好?
- 5.1、`iptables` 负载均衡:
- 5.2、 `IPVS` 负载均衡:
- 5.3、总结:
- 6、当表越来越大的时候,传统的表和哈希表在查找和插入、删除方面有什么区别?哪个优势更加大?
- 6.1、顺序表(如数组或链表):
- 6.2、哈希表:
- 6.3、性能优势:
- 7、iptables和ipvs使用了不同的数据结构存放规则,在查找速度上和扩展性上有差异 哈希表查询为什么比较快?
- 8、endpoint
- 9、查看service和endpoind的命令简写
- 10、查看proxyMode
- 11、service的暴露服务有几种类型
- 11.1、体验一下ClusterIP--->只能在内网(集群内部)访问,外网看不了
- 11.2、nodepod的指定端口范围
- 12、使用 Redis 部署 PHP 留言板应用
- 13、练习
- 13.1、编写一个yaml文件mysql.yaml,启动一个MySQL的pod,1个副本,然后创建一个服务service-MySQL,发布MySQL 标准的方式,启动pod
- 13.2、编写一个yaml文件nginx.yaml,使用deployment控制器,启动一个nginx的pod,3个副本,然后创建一个服务service-nginx,发布nginx集群 使用deployment控制器启动pod service的类型推荐使用nodeport
kubernetes-6
1、kubernetes中的网络通信插件
Calico和Flannel都是Kubernetes集群中常用的网络插件,用于处理Pod之间的通信和网络连接。它们都提供了覆盖网络(overlay network)的功能,但使用了不同的技术实现。
1.1、calico
Calico是一个专为大规模和高性能环境设计的网络和网络策略解决方案。它的一些关键特性包括:
- 适用大规模集群:Calico支持大规模部署,可以处理数千个节点和数十万个Pod的网络。
- 覆盖网络技术:Calippo默认使用IP-in-IP(ipip)模式作为其覆盖网络技术。这种技术通过在数据包上封装一个额外的IP头来在不同的Pod网络之间传输数据。
- BGP:Calico使用边界网关协议(BGP)来管理路由信息。这意味着Calico可以将Pod的IP地址作为BGP路由广播到整个集群中,从而允许直接的Pod间通信,减少了网络跳跃和提高了效率。
1.2、flannel
Flannel是CoreOS团队开发的一个简单且轻量级的网络插件,它适用于小规模或刚开始成长的集群。Flannel的一些关键特性包括:
- 适用小规模集群:Flannel设计简单,适合小型集群或开发环境,其中网络规模和复杂性较低。
- 覆盖网络技术:Flannel默认使用虚拟可扩展局域网(VXLAN)作为其覆盖网络技术。VXLAN通过封装原始数据包并添加一个VXLAN头来在不同节点上的Pod之间传输数据。
- 覆盖网络范围:Flannel的覆盖网络是跨越整个集群的,它允许不同节点上的Pod之间进行通信,就像它们在同一个局域网中一样。
2、service服务
将内部的pod暴露到外面,让用户可以访问
2.1、服务暴露/发现
将k8s内部的pod发送出去,外面的用户就可以发现我们内部的应用 —>做的DNAT策略
2.2、体验操作
[root@master ~]# mkdir /service
[root@master ~]# cd /service/
[root@master service]# vim scnginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: scnginx-deploymentlabels:app: scnginx
spec:replicas: 6selector:matchLabels:app: scnginxtemplate:metadata:labels:app: scnginxspec:containers:- name: nginximage: nginx:latestimagePullPolicy: IfNotPresentports:- containerPort: 80
[root@master service]#
这段YAML配置定义了一个Kubernetes Deployment资源,用于部署和管理名为scnginx的Nginx服务。以下是对这个YAML配置的详细解释:
-
apiVersion: apps/v1:- 指定了Kubernetes API的版本,
apps/v1是Deployment资源的一个稳定版本。
- 指定了Kubernetes API的版本,
-
kind: Deployment:- 声明了这个YAML文件定义的资源类型是Deployment,这是用来管理无状态应用副本的。
-
metadata::- 包含了Deployment的元数据信息。
name: scnginx-deployment: 定义了Deployment的名称为scnginx-deployment。labels:: 定义了Deployment的标签,这里设置了app: scnginx,可以用来选择和管理相关的资源。
- 包含了Deployment的元数据信息。
-
spec::- 定义了Deployment的规格,包括副本数量、选择器和模板。
-
replicas: 6:- 指定了Deployment应该维护的Pod副本数量,这里是6个。
-
selector::- 定义了如何选择Pod模板。
matchLabels:: 使用matchLabels来选择所有带有app: scnginx标签的Pods。
- 定义了如何选择Pod模板。
-
template::-
定义了Pod模板,所有由这个Deployment创建的Pod都会基于这个模板。
-
metadata:: 定义了Pod的元数据。labels:: 定义了Pod的标签,这里设置了app: scnginx,以便Deployment可以通过选择器找到这些Pod。
-
spec:: 定义了Pod的规格,包括容器和其他配置。containers:: 列出了Pod中的容器。- name: nginx: 定义了容器的名称为nginx。image: nginx: 指定了容器使用的镜像为官方的nginx镜像。imagePullPolicy: IfNotPresent: 指定了拉取镜像的政策,IfNotPresent意味着如果本地没有这个镜像,那么会尝试从镜像仓库拉取。ports:: 定义了容器的端口。- containerPort: 80: 指定了容器内部的端口80对外开放。
-
-
这个Deployment配置将创建6个Nginx Pod,这些Pod将在集群中运行,并且可以通过端口80进行访问。如果你在集群中运行了这个配置,你可以通过Kubernetes的服务发现和负载均衡机制来访问这些Nginx实例。
[root@master service]# kubectl apply -f scnginx.yaml
deployment.apps/scnginx-deployment created
[root@master service]# kubectl apply -f scnginx.yaml
deployment.apps/scnginx-deployment configured
[root@master service]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
scnginx-deployment-6b75585858-4mk5k 1/1 Running 0 2s 10.244.247.42 node-2 <none> <none>
scnginx-deployment-6b75585858-fk7dm 1/1 Running 0 76s 10.244.247.37 node-2 <none> <none>
scnginx-deployment-6b75585858-hkr8t 1/1 Running 0 76s 10.244.247.39 node-2 <none> <none>
scnginx-deployment-6b75585858-pgdc2 1/1 Running 0 76s 10.244.247.40 node-2 <none> <none>
scnginx-deployment-6b75585858-v2v8c 1/1 Running 0 2s 10.244.247.41 node-2 <none> <none>
scnginx-deployment-6b75585858-z87s5 1/1 Running 0 2s 10.244.84.140 node-1 <none> <none>
[root@master service]#
这个时候需要再建个service的yaml,用来暴露出去
[root@master service]# vim service.yaml
apiVersion: v1
kind: Service
metadata:name: scnginx-service
spec:type: NodePort selector:app: scnginxports:- name: name-of-service-portprotocol: TCPport: 80targetPort: 80nodePort: 30009
这个service.yaml文件定义了一个Kubernetes Service资源,名为scnginx-service。Service是Kubernetes中的一个抽象,它定义了一种访问Pod的方式,通常用于负载均衡和提供稳定的网络接口。以下是对这个YAML配置的详细解释:
-
apiVersion: v1:- 指定了Kubernetes API的版本,
v1是Service资源的一个稳定版本。
- 指定了Kubernetes API的版本,
-
kind: Service:- 声明了这个YAML文件定义的资源类型是Service。
-
metadata::- 包含了Service的元数据信息。
name: scnginx-service: 定义了Service的名称为scnginx-service。
- 包含了Service的元数据信息。
-
spec::- 定义了Service的规格,包括选择器、端口和访问类型。
-
type: NodePort:- 指定Service的类型为NodePort。这意味着Service将在集群的所有节点上打开一个端口(
nodePort),外部流量可以通过任何节点的IP地址和这个端口访问Service。
- 指定Service的类型为NodePort。这意味着Service将在集群的所有节点上打开一个端口(
-
selector::- 定义了Service如何选择Pod。
app: scnginx: 这是选择器的标签,Service将选择所有带有app=scnginx标签的Pod。
- 定义了Service如何选择Pod。
-
ports::- 定义了Service的端口配置。
name: name-of-service-port: 这是端口的名称,它是一个可选字段,用于标识端口。protocol: TCP: 指定了使用的协议类型,这里是TCP。port: 80: 负载均衡器的对外监听的端口targetPort: 80: 容器里监听的端口(pod监听的端口)nodePort: 30009: 宿主机(节点服务器)监听的端口
- 定义了Service的端口配置。
使用这个配置,当你创建了Service后,你可以通过任何节点的IP地址和nodePort(在这个例子中是30009)来访问运行在集群中的Nginx服务。这对于从集群外部访问内部Pod非常有用,尤其是当你没有使用负载均衡器或Ingress资源时。
这将创建一个名为scnginx-service的Service,它将流量从节点上的30009端口转发到带有app=scnginx标签的Pod上的80端口。
[root@master service]# kubectl apply -f service.yaml
service/scnginx-service created
[root@master service]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 10d
mydb ClusterIP 10.111.97.213 <none> 80/TCP 6d5h
myservice ClusterIP 10.110.72.101 <none> 80/TCP 6d5h
scnginx-service NodePort 10.99.11.122 <none> 80:30009/TCP 9s
[root@master service]#
每个服务都会有一个ip
通过访问宿主机上的端口,映射到pod里–》外网就可以访问内部的pod了
访问: 30009端口,不管是master还是node1,node2都会转到负载均衡器的
谁做的负载均衡器?
- kube-proxy

ipvsadm 是一个客户端的管理工具,用来查看内核的ipvs的规则,给内核里的ipvs模块传递参数使用
[root@master service]# ipvsadm -L -n
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.182.133:30009 rr-> 10.244.84.150:80 Masq 1 0 0 -> 10.244.247.30:80 Masq 1 0 0 -> 10.244.247.31:80 Masq 1 0 0 -> 10.244.247.38:80 Masq 1 0 0 -> 10.244.247.45:80 Masq 1 0 0 -> 10.244.247.51:80 Masq 1 0 0
这个命令输出显示了通过 ipvsadm 工具配置的 TCP 虚拟服务器列表,这些服务器是使用 IPVS(IP Virtual Server)内核模块设置的。ipvsadm 是一个用于管理 IPVS 规则的命令行工具。下面是对输出内容的逐项解释:
-
IP Virtual Server version 1.2.1 (size=4096):这行显示了 IPVS 版本(1.2.1)和 IPVS 表的最大大小(4096个条目)。
-
Prot:表示协议类型,这里是
TCP表示传输控制协议。 -
LocalAddress:Port:负载均衡器的虚拟 IP 地址和端口号,也就是客户端连接的目标地址和端口。在这个例子中,有两个虚拟服务器分别监听在
192.168.182.133:30009和10.96.0.1:443。 -
Scheduler:调度算法,
rr表示轮询(Round Robin)算法,它将请求按顺序轮流分配给后端的服务器。 -
Flags:标志位,
Masq表示伪装(Masquerading),这是一种 NAT 类型,负载均衡器会将后端服务器的源 IP 地址替换为自己的虚拟 IP 地址,以便客户端无法看到真实的服务器 IP。 -
Forward:权重,这里所有服务器的权重都是
1,表示每个服务器被平等地考虑用于负载均衡。 -
ActiveConn:当前活动的连接数,这里显示为
0,表示目前没有活跃的连接。 -
InActConn:非活动的连接数,这里也是
0,表示没有处于非活动状态的连接。
具体到每个虚拟服务器:
- 对于
192.168.182.133:30009虚拟服务器,有六个后端服务器(Real Servers)被配置为处理到达该地址的 TCP 流量。这些服务器的 IP 地址分别是10.244.84.150,10.244.247.30,10.244.247.31,10.244.247.38,10.244.247.45, 和10.244.247.51,它们都监听端口80。所有这些服务器都被设置为Masq模式,并且每个服务器的权重都是1。
这个输出提供了一个关于如何通过 IPVS 进行负载均衡的快照,显示了虚拟服务器的配置和当前的状态。
2.3、这个体验的流程图和解释
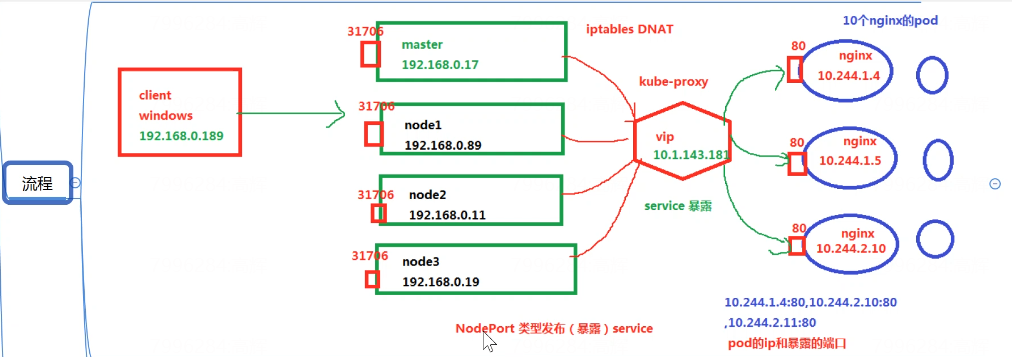
用户访问master或者pod节点上,然后会转到service上(服务相当于一个负载均衡器—>虚拟ip),然后内部采用ipvs做负载均衡把流量导到后边的机器上。
更详细的解释:
在 Kubernetes 集群中,用户访问服务(Service)时,流量的流转过程如下:
- 用户访问:用户通过集群外部访问服务时,通常是通过 LoadBalancer 类型的 Service 的外部 IP 地址,或者是通过 NodePort 类型的 Service 的节点 IP 地址和特定端口。
- Service 层:Service 在 Kubernetes 中充当抽象层,它定义了一个逻辑集合(Pods)和访问它们的策略。Service 有一个 ClusterIP(内部访问)或一个 LoadBalancer IP(外部访问),以及定义了如何选择后端 Pods 的标签选择器。
- 负载均衡:当流量到达 Service 的 IP 地址时,Kubernetes 使用 kube-proxy 组件来实现负载均衡。在 IPVS 模式下,kube-proxy 会配置 IPVS 规则,这些规则负责将流量从 Service 的虚拟 IP(ClusterIP 或 LoadBalancer IP)转发到后端的 Pod IP 地址。
- IPVS 转发:IPVS 作为内核级别的负载均衡器,会根据配置的负载均衡算法(如轮询、最少连接等)将流量分发到后端的多个 Pod 上。IPVS 直接在内核空间操作,因此具有高性能和低延迟的特点。
- Pod 处理请求:流量最终到达后端的 Pod,Pod 处理请求并将响应返回给用户。
需要注意的是,Service 的 ClusterIP 是一个虚拟 IP,它只在集群内部可见,用于内部服务发现和负载均衡。而 LoadBalancer 类型的 Service 通常会通过云提供商的负载均衡器来分配一个外部可访问的 IP 地址,用于外部访问。
3、ipvs
3.1、理解
在 Kubernetes (k8s) 中,IPVS 是一种内核级别的负载均衡器,用于实现服务的负载均衡功能。它是 kube-proxy 组件支持的三种模式之一(另外两种是 userspace 和 iptables)。IPVS 模式在 Kubernetes v1.8 中引入,并在 v1.9 版本中进入 beta 阶段,v1.11 版本中正式成为 GA(General Availability)。
IPVS 的主要优势包括:
高性能:IPVS 工作在内核空间,可以高效地处理大量的网络流量,提供高速的数据包转发。可扩展性:IPVS 支持复杂的负载均衡算法,如轮询(Round Robin)、最少连接(Least Connections)、源哈希(Source Hash)等,适合大规模集群环境。连接跟踪:IPVS 可以与 Linux 的 conntrack 模块配合使用,支持 SNAT 和 DNAT,从而实现负载均衡和会话保持。健康检查:IPVS 支持对后端服务的健康检查,可以自动移除不健康的后端实例。灵活性:IPVS 允许使用 ipset 来管理一组 IP 地址,这有助于优化和管理负载均衡的后端实例。
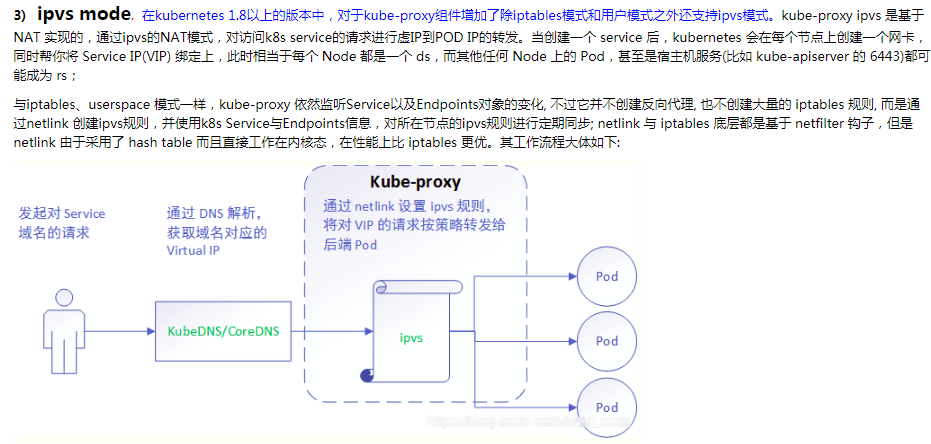
创建一个service的时候,背后就会创建一个负载均衡器 对我们的服务进行负载均衡
3.2、负载均衡的软件:LVS
load balancer 负载均衡器
LVS(Linux Virtual Server)是一个开源的负载均衡解决方案,它提供了高性能、高可用性的服务器集群功能。LVS 可以将多个服务器组织成一个虚拟服务器群组,对外表现为一个单一的服务器,从而提供负载均衡和故障转移的能力。
lvs 是 linux虚拟机,是一个负载均衡软件,是中国人发明的–>章文嵩
LVS 的工作流程大致如下:
- 客户端发送请求到虚拟 IP(VIP),这个 VIP 由 LVS 集群共享。
- LVS 负载均衡器(Director Server)接收到请求后,根据配置的负载均衡策略和算法,选择一个合适的真实服务器(Real Server)来处理请求。
- LVS 将请求转发到选定的真实服务器。
- 真实服务器处理请求并将响应发送回 LVS。
- LVS 将响应转发回客户端。
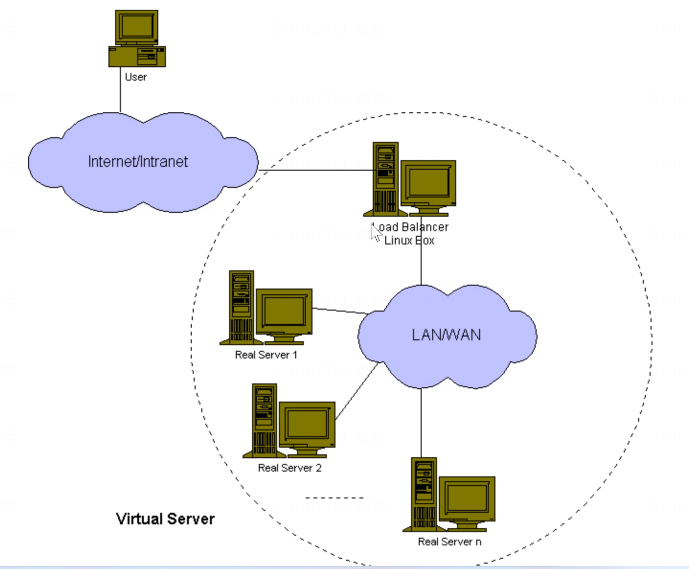
- 用户通过互联网访问到我的负载均衡器
- 负载均衡器再转发到内网去
3.2.1、LVS的nat模式
http://www.linuxvirtualserver.org/VS-NAT.html
LVS 的 NAT 模式(Network Address Translation,网络地址转换模式)是 LVS 负载均衡器的一种工作模式。在这种模式下,LVS 负载均衡器(Director)充当了网络地址转换的角色,将客户端的请求转发给后端的真实服务器(Real Server),并将服务器的响应返回给客户端。NAT 模式允许 LVS 在不改变客户端和服务器端 IP 地址的情况下进行流量的转发和负载均衡。
NAT 模式的特点包括:
-
地址转换:LVS 在 NAT 模式下会修改经过它的数据包的目标 IP 地址。对于进入的数据包,LVS 将目标 IP 地址从 VIP(Virtual IP)转换为后端服务器的 RIP(Real Server IP)。对于传出的数据包,LVS 将源 IP 地址从 RIP 转换回 VIP。
-
透明性:客户端和服务器不需要关心负载均衡器的存在,因为所有的地址转换都是在 LVS 负载均衡器上完成的。
-
安全性:由于所有的流量都需要经过 LVS 负载均衡器,因此可以在此层实施安全策略,例如防火墙规则。
-
跨网络:NAT 模式允许 LVS 负载均衡器和后端服务器位于不同的网络中,只要 LVS 负载均衡器有路由到这些服务器的路径。
-
端口映射:NAT 模式支持端口映射,允许将不同的服务映射到不同的端口上。
NAT 模式的工作原理如下:
- 客户端向 VIP 发送请求。
- LVS 负载均衡器接收到请求,并根据配置的调度算法选择一个后端服务器。
- LVS 修改请求数据包的目标 IP 地址为选定的后端服务器的 RIP。
- 后端服务器处理请求,并将响应发送回 LVS 负载均衡器。
- LVS 接收到响应后,修改数据包的源 IP 地址为 VIP,然后将其发送回客户端。
NAT 模式适用于多种场景,特别是当需要隐藏后端服务器的真实 IP 地址或需要对流量进行集中管理时。然而,这种模式也可能导致 LVS 负载均衡器成为系统的瓶颈,因为所有的流量都需要经过它。此外,NAT 模式不支持 SNAT(源地址转换),这意味着所有的响应流量都需要经过 LVS 负载均衡器。
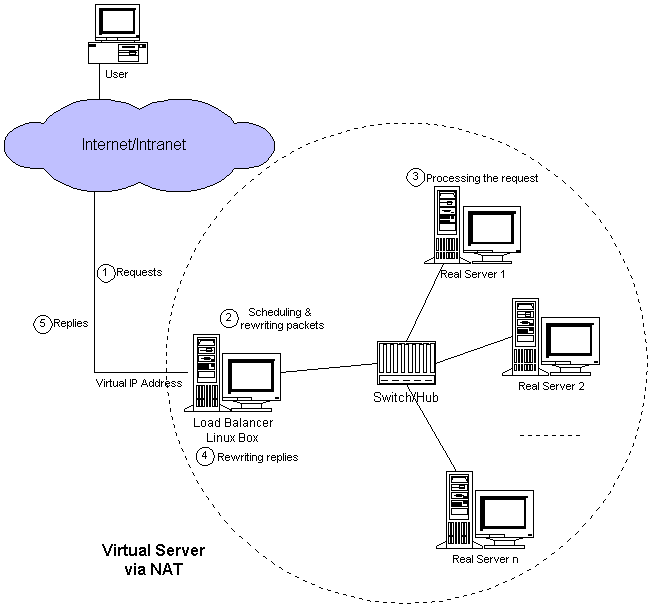
NAT模式的负载均衡系统的工作流程:
用户请求:用户(User)通过互联网(Internet)或内部网络(Intranet)发起请求(Requests)。负载均衡器接收:用户的请求首先到达负载均衡器(Load Balancer),这是一个运行在Linux服务器(Linux Box)上的系统,它负责管理和分配流量。调度和数据包重写:负载均衡器根据预设的调度策略(Scheduling),选择一个合适的真实服务器(Real Server)来处理这个请求。同时,它会重写(rewriting)数据包,将目标地址从负载均衡器的虚拟IP(Virtual IP Address)更改为选定的真实服务器的IP地址。通过NAT转发:负载均衡器使用网络地址转换(NAT)将用户的请求转发给选定的真实服务器。这意味着请求的数据包在发送给真实服务器之前,其源地址会被更改为负载均衡器的虚拟IP地址。真实服务器处理请求:选定的真实服务器接收到请求后,根据请求内容进行处理。响应重写:真实服务器处理完请求后,会生成响应(Replies)。负载均衡器再次重写这些响应数据包,将源地址从真实服务器的IP地址更改回负载均衡器的虚拟IP地址。响应返回给用户:重写后的响应数据包通过交换机(Switch)或集线器(Hub)返回给负载均衡器,然后负载均衡器将这些响应发送回用户。多个真实服务器:如果有多个真实服务器(Real Server 1, Real Server 2, …, Real Server n),负载均衡器会根据调度策略将请求分配给它们,从而实现负载分散。
总结来说,负载均衡器在这个流程中充当了流量的调度中心,它接收用户的请求,决定由哪个真实服务器来处理这些请求,并通过NAT技术将请求和响应在用户和服务器之间进行转发和重定向。这样可以提高服务的可用性和可靠性,同时分散单个服务器的负载。
3.2.2、DR模式
http://www.linuxvirtualserver.org/VS-DRouting.html
3.2.3、TUN模式-隧道模式
http://www.linuxvirtualserver.org/VS-IPTunneling.html
3.3、查看ipvs命令
ipvsadm -L -n
4、调度算法
-
轮询(Round Robin, RR):
- 按顺序将请求轮流分配给每个服务器。
- 简单且公平,但不考虑服务器的负载情况。
-
最少连接(Least Connections, LC):
- 优先将请求发送给当前活跃连接数最少的服务器。
- 适用于处理时间不均匀的场景。
-
加权轮询(Weighted Round Robin, WRR):
- 根据服务器的权重来分配请求,权重高的服务器将接收更多的请求。
- 允许为不同的服务器分配不同的负载。
-
加权最少连接(Weighted Least Connections, WLC):
- 结合最少连接和权重的概念,根据服务器的权重和活跃连接数来分配请求。
- 考虑了服务器的性能差异。
-
源地址哈希(Source Hashing):
- 根据客户端的 IP 地址计算哈希值,然后根据这个值选择服务器。
- 可以保持来自同一客户端的请求总是被发送到同一台服务器。
-
目标地址哈希(Destination Hashing):
- 类似于源地址哈希,但是根据目标地址(服务器的 IP)来计算哈希值。
- 适用于后端服务器有多个实例且分布在不同位置的场景。
-
最短响应时间(Least Time):
- 将请求发送给预测响应时间最短的服务器。
- 需要负载均衡器能够估计或测量服务器的响应时间。
-
动态权重(Dynamic Weight):
- 根据服务器的实际性能动态调整权重。
- 可以适应服务器负载变化的情况。
-
URL哈希:
- 根据请求的 URL 计算哈希值来选择服务器。
- 适用于需要按内容分发请求的应用,如缓存服务器。
这些算法可以单独使用,也可以组合使用,以满足特定的负载均衡需求。例如,可以在一个集群中对不同的服务应用不同的调度算法,或者根据实际情况调整算法参数。
5、iptables和ipvs做负载均衡的时候,哪些性能好?
在使用 iptables 和 IPVS 进行负载均衡时,它们的性能特点如下:
5.1、iptables 负载均衡:
- 顺序处理:
iptables规则是顺序地存放在一个表中,当处理网络流量时,会按照规则的顺序进行匹配,直到找到匹配的规则为止。 - 规则数量影响:随着
iptables规则数量的增加,查找匹配规则所需的时间也会增加,这可能导致效率降低。 - 适用场景:由于规则查找的线性特性,
iptables可能不适合大规模集群,特别是当需要处理大量规则时。
5.2、 IPVS 负载均衡:
- 哈希表存储:
IPVS使用哈希表来存储负载均衡策略,这意味着它可以通过哈希值快速定位到具体的规则,从而实现高效的查找。 - 性能优势:由于哈希表的查找效率较高,
IPVS可以在大规模集群中快速地进行负载均衡决策,消耗的时间较短。 - 适用场景:
IPVS适合于大型集群和高并发的场景,因为它能够快速处理大量的网络流量,同时保持高效的性能。
5.3、总结:
IPVS 在进行负载均衡时,由于其哈希表的存储方式,提供了更高的查找效率和更好的性能,特别适合大规模集群和高负载环境。相比之下,iptables 由于其顺序表的特性,在处理大量规则时可能会遇到性能瓶颈。因此,在需要高性能负载均衡的场合,IPVS 通常是更优的选择。
6、当表越来越大的时候,传统的表和哈希表在查找和插入、删除方面有什么区别?哪个优势更加大?
当表的大小增加时,传统的顺序表(如链表或数组)和哈希表在查找、插入和删除操作上的性能差异变得显著。以下是两者的比较:
6.1、顺序表(如数组或链表):
- 查找:在最好的情况下,查找操作的时间复杂度是 O(1)(如数组通过索引直接访问),但在最坏的情况下是 O(n)(如链表需要遍历每个元素)。
- 插入:插入操作通常是 O(1),因为可以在表的任何位置添加元素,但可能需要后续的重新排序或调整。
- 删除:删除操作的复杂度也依赖于数据结构。在数组中,删除可能需要 O(n) 时间来移动后续元素,而在链表中,删除操作通常是 O(1),如果已经知道要删除的元素的位置。
6.2、哈希表:
- 查找:哈希表的平均查找时间复杂度是 O(1),因为它使用哈希函数将键直接映射到表中的一个位置。即使表变得很大,只要哈希函数设计得当,冲突(两个不同的键映射到同一个位置)的概率仍然很低。
- 插入:插入操作的时间复杂度也是 O(1),因为哈希表可以通过哈希函数快速定位到插入位置,并且通常不需要遍历整个表。
- 删除:删除操作同样具有 O(1) 的平均时间复杂度,因为可以通过键直接定位到要删除的元素。
6.3、性能优势:
哈希表在查找、插入和删除操作上具有显著的性能优势,尤其是在处理大量数据时。哈希表的平均性能不随数据量的增加而显著下降,这使得它们非常适合用于大型数据集和高并发的场景。然而,哈希表的性能依赖于哈希函数的设计和良好的散列,以最小化冲突。如果发生大量冲突,性能可能会下降,因为需要解决冲突,这通常涉及到额外的链表操作或其他方法。
总的来说,当表的大小增加时,哈希表在大多数情况下提供了更优的性能,尤其是对于频繁的查找操作。然而,设计一个高效的哈希表需要考虑键的分布、表的大小和处理冲突的策略。
7、iptables和ipvs使用了不同的数据结构存放规则,在查找速度上和扩展性上有差异 哈希表查询为什么比较快?
哈希表查询之所以比较快,主要归功于其背后的数据结构和算法——哈希函数。以下是哈希表查询速度快的几个关键原因:
-
直接寻址:
哈希表使用哈希函数将键(key)转换为一个索引(hash code),这个索引直接指向表中的一个位置。这意味着一旦计算出哈希值,就可以立即知道数据存储在数组的哪个位置,无需遍历整个表。 -
平均时间复杂度为O(1):
理想情况下,哈希函数会均匀地将键散列到哈希表的所有可能位置。这样,查找任何键的平均时间复杂度都是常数时间,即 O(1),因为每个键都有一个唯一的位置。 -
快速散列计算:
哈希函数通常设计得足够简单,以便快速计算。这意味着从输入键到得到哈希值的过程非常迅速。 -
冲突解决机制:
尽管哈希函数旨在减少冲突,但在实际应用中,不同的键可能会产生相同的哈希值。哈希表通过不同的冲突解决策略(如链地址法、开放地址法等)来处理这些冲突,这些策略旨在最小化查找时间。 -
动态调整大小:
许多哈希表实现在达到一定负载因子时会自动调整大小(rehashing),这有助于保持哈希表的性能,即使在动态变化的数据集中也是如此。
相比之下,使用顺序存储的数据结构(如数组或链表)在查找时可能需要遍历整个数据集,特别是在最坏的情况下,这会导致 O(n) 的时间复杂度,其中 n 是数据集中的元素数量。因此,哈希表在处理大量数据时提供了更快的查找速度和更好的扩展性。然而,哈希表的性能也受限于哈希函数的设计和冲突解决策略的有效性。如果哈希函数导致大量冲突,或者冲突解决策略效率低下,哈希表的性能可能会下降。
8、endpoint
- ENDPOINTS就是service关联的pod的ip地址和端口
- 真正提供业务服务的终点
- 一个服务会对应一个endpoint
[root@master service]# kubectl get endpoints -o wide
NAME ENDPOINTS AGE
kubernetes 192.168.182.133:6443 12d
scnginx-service 10.244.247.30:80,10.244.247.31:80,10.244.247.38:80 + 3 more... 41h
[root@master service]#
9、查看service和endpoind的命令简写
[root@master service]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 12d <none>
mydb ClusterIP 10.111.97.213 <none> 80/TCP 7d23h <none>
myservice ClusterIP 10.110.72.101 <none> 80/TCP 7d23h <none>
scnginx-service NodePort 10.99.11.122 <none> 80:30009/TCP 41h app=scnginx
[root@master service]# kubectl get ep -o wide
NAME ENDPOINTS AGE
kubernetes 192.168.182.133:6443 12d
scnginx-service 10.244.247.30:80,10.244.247.31:80,10.244.247.38:80 + 3 more... 41h
[root@master service]#
10、查看proxyMode
[root@master service]# curl localhost:10249/proxyMode
ipvs[root@master service]#
11、service的暴露服务有几种类型
在 Kubernetes 中,Service 对象用于定义一种方式,使得可以访问一组运行在 Pod 中的应用。Service 通过定义一个统一的访问接口(即 ClusterIP),来负载均衡到后端的多个 Pod。此外,Service 还可以通过不同的方式将服务暴露给集群外部。以下是 Kubernetes Service 的几种暴露服务类型:
-
ClusterIP(默认):
- 这是默认的 Service 类型,它在集群内部提供一个虚拟 IP 地址(ClusterIP),用于从集群内部访问服务。外部无法直接访问 ClusterIP。
-
NodePort:
- NodePort 类型的 Service 会在集群的所有节点上分配一个静态端口(NodePort),并将该端口路由到对应的 Service。这样,可以通过任何节点的 IP 地址和分配的 NodePort 来访问服务。
-
LoadBalancer:
- 这种类型的 Service 会向云提供商的负载均衡器请求一个负载均衡器实例,并将外部流量路由到 Service。这是在云环境中常用的方法,可以提供一个外部可访问的 IP 地址。
-
ExternalName:
- ExternalName 类型的 Service 允许将 Service 定义为对外部服务的引用,通过返回一个 CNAME 记录,而不是像其他类型那样通过一个 IP 地址。这对于服务发现和将服务路由到 Kubernetes 集群外部的资源非常有用。
每种类型都有其特定的用途和适用场景。例如,ClusterIP 适用于在集群内部通信的服务,NodePort 和 LoadBalancer 适用于需要从集群外部访问的服务,而 ExternalName 适用于将服务指向集群外部的 DNS 名称。
11.1、体验一下ClusterIP—>只能在内网(集群内部)访问,外网看不了
[root@master service]# vim scnginx-2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: scnginx-deployment-2labels:app: scnginx-2
spec:replicas: 3selector:matchLabels:app: scnginx-2template:metadata:labels:app: scnginx-2spec:containers:- name: nginximage: nginx:latestimagePullPolicy: IfNotPresentports:- containerPort: 80
[root@master service]#
[root@master service]# vim service-2.yaml
apiVersion: v1
kind: Service
metadata:name: scnginx-service-2
spec:type: ClusterIPselector:app: scnginx-2ports:- name: name-of-service-port-2protocol: TCPport: 80targetPort: 80#nodePort: 30009
[root@master service]#
[root@master service]# kubectl apply -f scnginx-2.yaml
deployment.apps/scnginx-deployment-2 created
[root@master service]# kubectl apply -f service-2.yaml
service/scnginx-service-2 created
[root@master service]# kubectl get pod
NAME READY STATUS RESTARTS AGE
scnginx-deployment-2-ff76d989-g8vh2 1/1 Running 0 21s
scnginx-deployment-2-ff76d989-th77v 1/1 Running 0 21s
scnginx-deployment-2-ff76d989-wcd84 1/1 Running 0 21s'查看服务类型'
[root@master service]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 12d
mydb ClusterIP 10.111.97.213 <none> 80/TCP 7d23h
myservice ClusterIP 10.110.72.101 <none> 80/TCP 7d23h
scnginx-service NodePort 10.99.11.122 <none> 80:30009/TCP 41h
scnginx-service-2 ClusterIP 10.98.192.152 <none> 80/TCP 15s
[root@master service]#
[root@master service]# curl 10.98.192.152
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p><p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p><p><em>Thank you for using nginx.</em></p>
</body>
</html>
[root@master service]#
11.2、nodepod的指定端口范围

12、使用 Redis 部署 PHP 留言板应用
-
编写yaml文件
[root@master redis]# vim redis-leader.yaml [root@master redis]# cat redis-leader.yaml apiVersion: apps/v1 kind: Deployment metadata:name: redis-leaderlabels:app: redisrole: leadertier: backend spec:replicas: 1selector:matchLabels:app: redistemplate:metadata:labels:app: redisrole: leadertier: backendspec:containers:- name: leaderimage: "docker.io/redis:6.0.5"imagePullPolicy: IfNotPresentresources:requests:cpu: 100mmemory: 100Miports:- containerPort: 6379 [root@master redis]# -
创建
[root@master redis]# kubectl apply -f redis-leader.yaml deployment.apps/redis-leader created [root@master redis]# kubectl get pod NAME READY STATUS RESTARTS AGE redis-leader-fb76b4755-vtn47 1/1 Running 0 65s [root@master redis]# kubectl get -f redis-leader.yaml -o wide NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR redis-leader 1/1 1 1 67s leader docker.io/redis:6.0.5 app=redis [root@master redis]# -
创建服务,发布redis
[root@master redis]# vim fedis-leader-service.yaml apiVersion: v1 kind: Service metadata:name: redis-leaderlabels:app: redisrole: leadertier: backend spec:ports:- port: 6379targetPort: 6379selector:app: redisrole: leadertier: backend [root@master redis]#
后续实验完成不了,没有国外镜像…
实验地址: https://kubernetes.io/zh-cn/docs/tutorials/stateless-application/guestbook/
13、练习
13.1、编写一个yaml文件mysql.yaml,启动一个MySQL的pod,1个副本,然后创建一个服务service-MySQL,发布MySQL 标准的方式,启动pod
[root@master mysql]# vim mysql-pod-svc.yaml
[root@master mysql]# cat mysql-pod-svc.yaml
apiVersion: v1
kind: Pod
metadata:name: mysqllabels:app.sc.io/name: scmysql
spec:containers:- name: mysqlimage: mysql:5.7.39imagePullPolicy: IfNotPresentports:- containerPort: 3306name: mysql-svcenv:- name: MYSQL_ROOT_PASSWORDvalue: "sc123456"
---
apiVersion: v1
kind: Service
metadata:name: mysql-service
spec:type: NodePortselector:app.sc.io/name: scmysqlports:- name: name-of-service-portprotocol: TCPport: 3306targetPort: mysql-svcnodePort: 30008
[root@master mysql]#
[root@master mysql]# kubectl apply -f mysql-pod-svc.yaml
pod/mysql created
service/mysql-service created
[root@master mysql]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 12d
mydb ClusterIP 10.111.97.213 <none> 80/TCP 8d
myservice ClusterIP 10.110.72.101 <none> 80/TCP 8d
mysql-service NodePort 10.108.120.107 <none> 3306:30008/TCP 10s
redis-leader ClusterIP 10.98.178.58 <none> 6379/TCP 19m
[root@master mysql]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mysql 1/1 Running 0 4m35s 10.244.247.52 node-2 <none> <none>
[root@master mysql]# [root@master mysql]# kubectl get ep
NAME ENDPOINTS AGE
kubernetes 192.168.182.133:6443 12d
mysql-service 10.244.247.52:3306 4m1s
redis-leader 10.244.247.48:6379 23m
[root@master mysql]#
去访问mysql
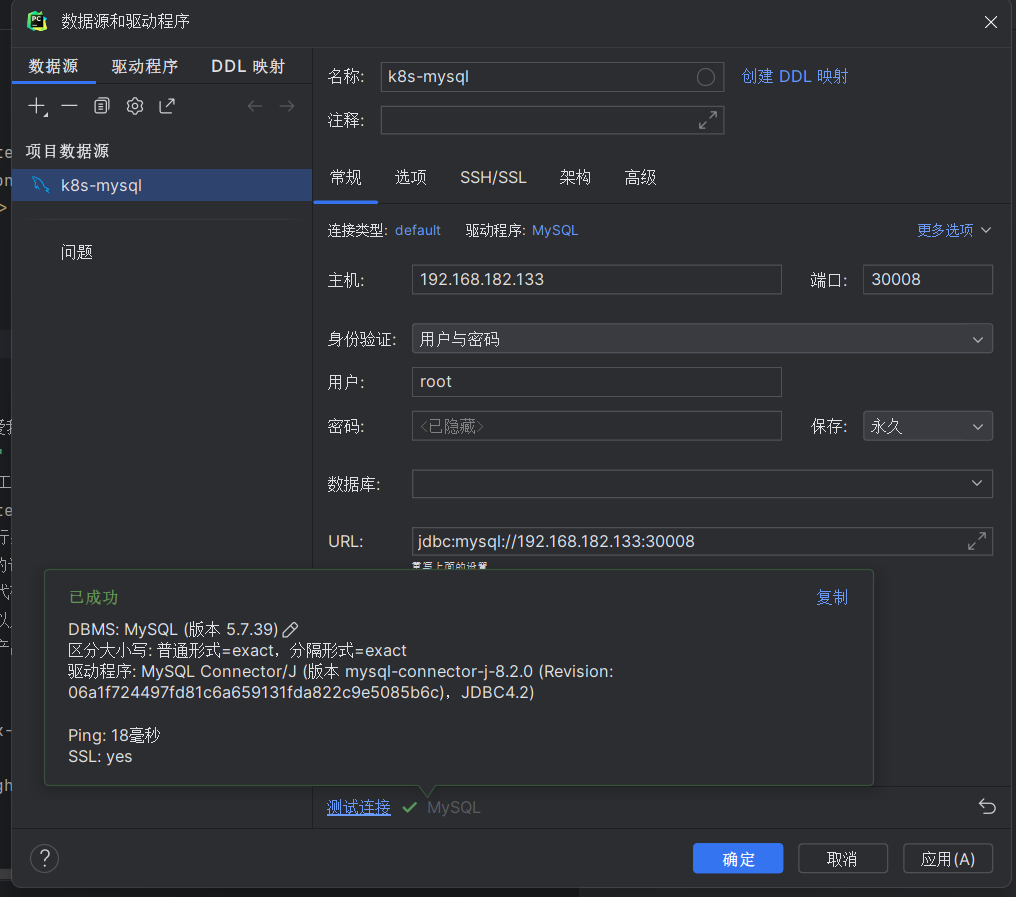
13.2、编写一个yaml文件nginx.yaml,使用deployment控制器,启动一个nginx的pod,3个副本,然后创建一个服务service-nginx,发布nginx集群 使用deployment控制器启动pod service的类型推荐使用nodeport
[root@master nginx]# vim nginx-pod-svc.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: scnginx-deploymentlabels:app: scnginx
spec:replicas: 3selector:matchLabels:app: scnginxtemplate:metadata:labels:app: scnginxspec:containers:- name: nginximage: nginximagePullPolicy: IfNotPresentports:- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:name: scnginx-service
spec:type: NodePortselector:app: scnginxports:- name: name-of-service-portprotocol: TCPport: 80targetPort: 80nodePort: 30009
[root@master nginx]# [root@master nginx]# kubectl apply -f nginx-pod-svc.yaml
deployment.apps/scnginx-deployment created
service/scnginx-service created
[root@master nginx]# kubectl get -f nginx-pod-svc.yaml
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/scnginx-deployment 3/3 3 3 8sNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/scnginx-service NodePort 10.103.157.7 <none> 80:30009/TCP 8s
[root@master nginx]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 12d
mydb ClusterIP 10.111.97.213 <none> 80/TCP 8d
myservice ClusterIP 10.110.72.101 <none> 80/TCP 8d
mysql-service NodePort 10.108.120.107 <none> 3306:30008/TCP 24m
redis-leader ClusterIP 10.98.178.58 <none> 6379/TCP 44m
scnginx-service NodePort 10.103.157.7 <none> 80:30009/TCP 14s
[root@master nginx]# kubectl get pod|grep nginx
scnginx-deployment-b975997c7-5jpbc 1/1 Running 0 26s
scnginx-deployment-b975997c7-8zjnj 1/1 Running 0 26s
scnginx-deployment-b975997c7-xbnnr 1/1 Running 0 26s
[root@master nginx]#
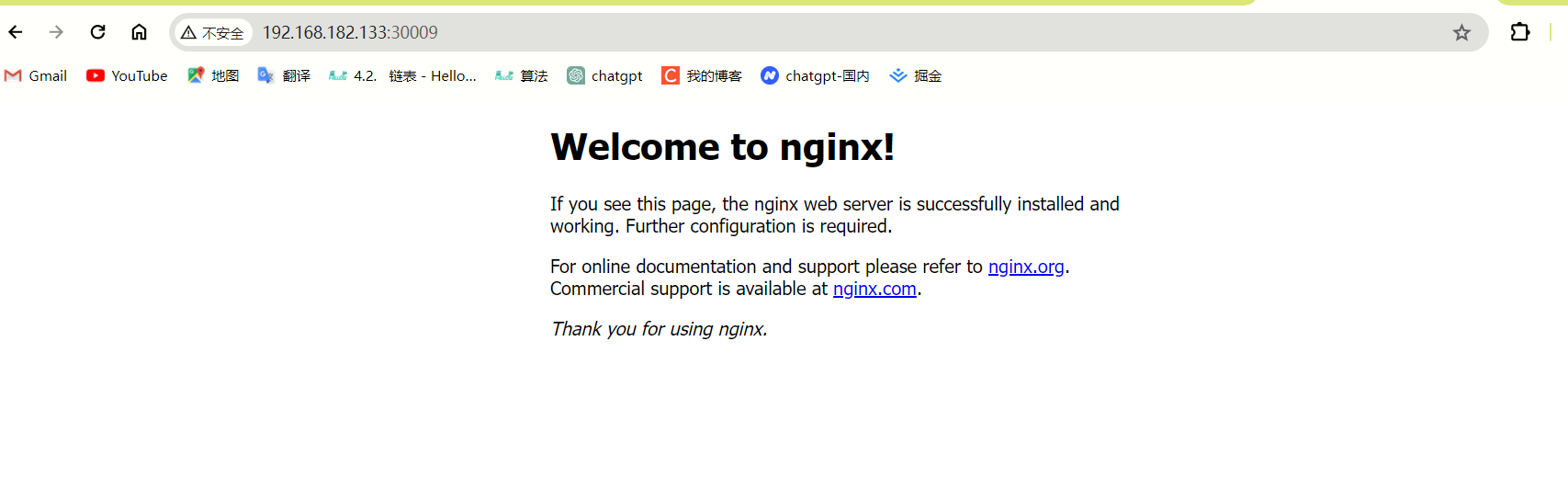
这篇关于kubernetes-服务-ipvs-调度算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






