本文主要是介绍【python】爬取百度热搜排行榜Top50+可视化【附源码】【送数据分析书籍】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
英杰社区 https://bbs.csdn.net/topics/617804998
https://bbs.csdn.net/topics/617804998
一、导入必要的模块:
这篇博客将介绍如何使用Python编写一个爬虫程序,从斗鱼直播网站上获取图片信息并保存到本地。我们将使用requests模块发送HTTP请求和接收响应,以及os模块处理文件和目录操作。
如果出现模块报错
进入控制台输入:建议使用国内镜像源
pip install requests -i https://mirrors.aliyun.com/pypi/simple
我大致罗列了以下几种国内镜像源:
清华大学
https://pypi.tuna.tsinghua.edu.cn/simple阿里云
https://mirrors.aliyun.com/pypi/simple/豆瓣
https://pypi.douban.com/simple/ 百度云
https://mirror.baidu.com/pypi/simple/中科大
https://pypi.mirrors.ustc.edu.cn/simple/华为云
https://mirrors.huaweicloud.com/repository/pypi/simple/腾讯云
https://mirrors.cloud.tencent.com/pypi/simple/
二、发送GET请求获取响应数据:
设置了请求头部信息,以模拟浏览器的请求,函数返回响应数据的JSON格式内容。
def get_html(url):header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}response = requests.get(url=url, headers=header)# print(response.json())html = response.json()return html如何获取请求头:
火狐浏览器:
- 打开目标网页并右键点击页面空白处。
- 选择“检查元素”选项,或按下快捷键Ctrl + Shift + C(Windows)
- 在开发者工具窗口中,切换到“网络”选项卡。
- 刷新页面以捕获所有的网络请求。
- 在请求列表中选择您感兴趣的请求。
- 在右侧的“请求标头”或“Request Headers”部分,即可找到请求头信息。
将以下请求头信息复制出来即可
三、代码思路
-
导入所需的库:
import requests
from bs4 import BeautifulSoup
import openpyxl
requests库用于发送HTTP请求获取网页内容。
BeautifulSoup库用于解析HTML页面的内容。
openpyxl库用于创建和操作Excel文件。
2.发起HTTP请求获取百度热搜页面内容:
url = 'https://top.baidu.com/board?tab=realtime'
response = requests.get(url)
html = response.content这里使用了
requests.get()方法发送GET请求,并将响应的内容赋值给变量html。
3.使用BeautifulSoup解析页面内容:
soup = BeautifulSoup(html, 'html.parser')
创建一个
BeautifulSoup对象,并传入要解析的HTML内容和解析器类型。
4.提取热搜数据:
hot_searches = []
for item in soup.find_all('div', {'class': 'c-single-text-ellipsis'}):hot_searches.append(item.text)这段代码通过调用
soup.find_all()方法找到所有<div>标签,并且指定class属性为'c-single-text-ellipsis'的元素。然后,将每个元素的文本内容添加到
hot_searches列表中。
5.保存热搜数据到Excel:
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = 'Baidu Hot Searches'使用
openpyxl.Workbook()创建一个新的工作簿对象。调用
active属性获取当前活动的工作表对象,并将其赋值给变量sheet。使用
title属性给工作表命名为'Baidu Hot Searches'。
6.设置标题:
sheet.cell(row=1, column=1, value='百度热搜排行榜—博主:Yan-英杰')使用
cell()方法选择要操作的单元格,其中row和column参数分别表示行和列的索引。将标题字符串
'百度热搜排行榜—博主:Yan-英杰'写入选定的单元格。
7.写入热搜数据:
for i in range(len(hot_searches)):sheet.cell(row=i+2, column=1, value=hot_searches[i])使用
range()函数生成一个包含索引的范围,循环遍历hot_searches列表。对于每个索引
i,使用cell()方法将对应的热搜词写入Excel文件中。
8.保存Excel文件:
workbook.save('百度热搜.xlsx')使用
save()方法将工作簿保存到指定的文件名'百度热搜.xlsx'。
9.输出提示信息:
print('热搜数据已保存到 百度热搜.xlsx')在控制台输出保存成功的提示信息。
四、完整代码:
如果对CSDN周边以及有偿返现任务感兴趣:https://bbs.csdn.net/topics/617804998
私信博主进入交流群,一起学习探讨:
可添加博主:Yan--yingjie
如果想免费获取图书,也可添加博主微信,每周免费送数十本import requests
from bs4 import BeautifulSoup
import openpyxl# 发起HTTP请求获取百度热搜页面内容
url = 'https://top.baidu.com/board?tab=realtime'
response = requests.get(url)
html = response.content# 使用BeautifulSoup解析页面内容
soup = BeautifulSoup(html, 'html.parser')# 提取热搜数据
hot_searches = []
for item in soup.find_all('div', {'class': 'c-single-text-ellipsis'}):hot_searches.append(item.text)# 保存热搜数据到Excel
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = 'Baidu Hot Searches'# 设置标题
sheet.cell(row=1, column=1, value='百度热搜排行榜—博主:Yan-英杰')# 写入热搜数据
for i in range(len(hot_searches)):sheet.cell(row=i+2, column=1, value=hot_searches[i])workbook.save('百度热搜.xlsx')
print('热搜数据已保存到 百度热搜.xlsx')
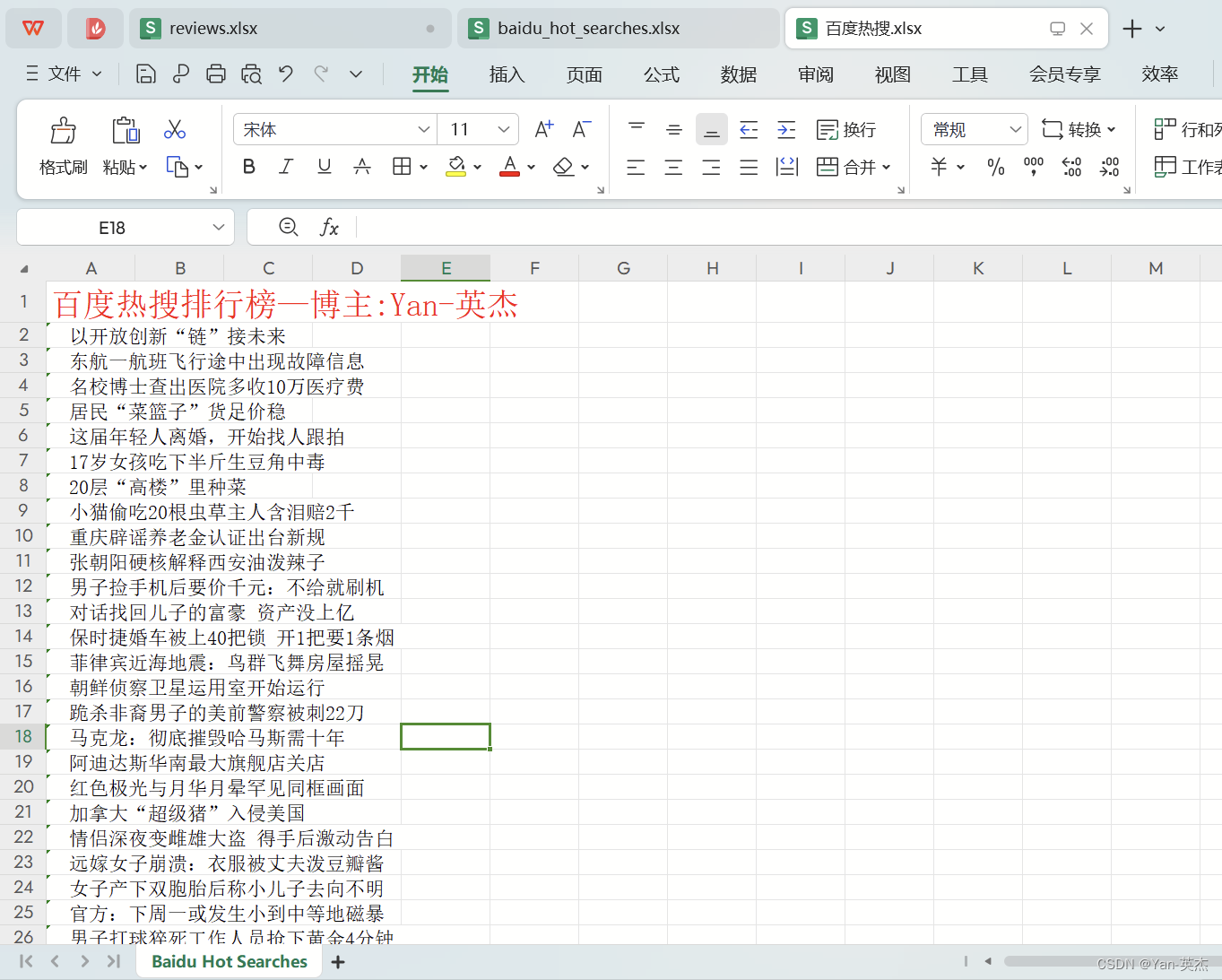
效果图:
可视化完整代码:
如果对CSDN周边以及有偿返现任务感兴趣:https://bbs.csdn.net/topics/617804998
私信博主进入交流群,一起学习探讨,如果对CSDN周边以及有偿返现任务感兴趣:
可添加博主:Yan--yingjie
如果想免费获取图书,也可添加博主微信,每周免费送数十本import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt# 发起HTTP请求获取百度热搜页面内容
url = 'https://top.baidu.com/board?tab=realtime'
response = requests.get(url)
html = response.content# 使用BeautifulSoup解析页面内容
soup = BeautifulSoup(html, 'html.parser')# 提取热搜数据
hot_searches = []
for item in soup.find_all('div', {'class': 'c-single-text-ellipsis'}):hot_searches.append(item.text)# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 绘制条形图
plt.figure(figsize=(15, 10))
x = range(len(hot_searches))
y = list(reversed(range(1, len(hot_searches)+1)))
plt.barh(x, y, tick_label=hot_searches, height=0.8) # 调整条形图的高度# 添加标题和标签
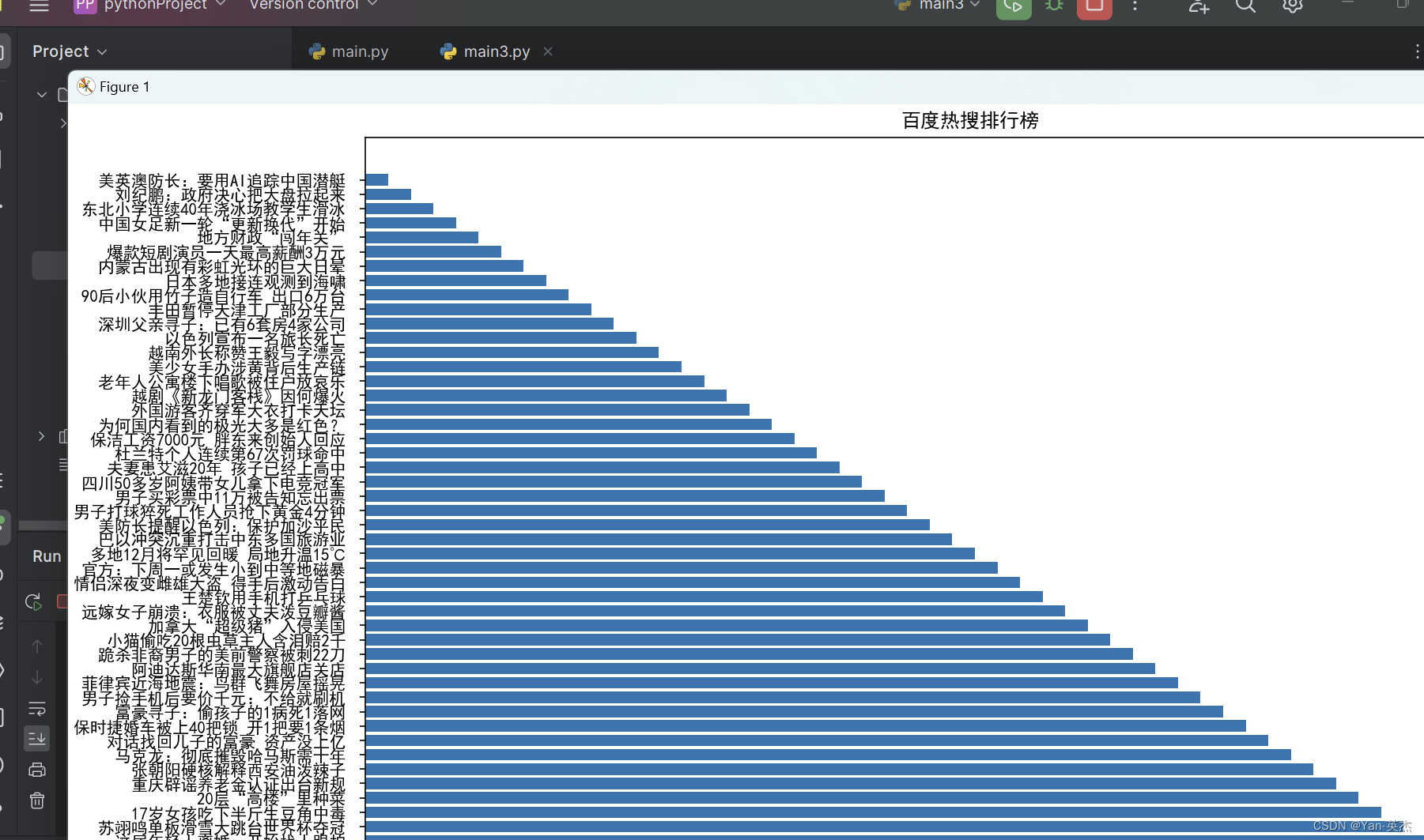
plt.title('百度热搜排行榜')
plt.xlabel('排名')
plt.ylabel('关键词')# 调整坐标轴刻度
plt.xticks(range(1, len(hot_searches)+1))# 调整条形图之间的间隔
plt.subplots_adjust(hspace=0.8, wspace=0.5)# 显示图形
plt.tight_layout()
plt.show()
效果图:
【文末送书】
参与活动
1️⃣参与方式:关注、点赞、收藏,评论(人生苦短,我用python)
2️⃣获奖方式:程序随机抽取 3位,每位小伙伴将获得一本书
3️⃣活动时间:截止到 2024-1- 3 22:00:00

内容简介
《Pandas数据分析》详细阐述了与Pandas数据分析相关的基本解决方案,主要包括数据分析导论、使用PandasDataFrame、使用Pandas进行数据整理、聚合Pandas DataFrame、使用Pandas和Matplotlib可视化数据、使用Seabom和自定义技术绘图、金融分析、基于规则的异常检测、Python机器学习入门、做出更好的预测、机器学习异常检测等内容。此外,该书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。
《Pandas数据分析》适合作为高等院校计算机及相关专业的教材和教学参考书,也可作为相关开发人员的自学用书和参考手册。
购买链接:
京东:https://item.jd.com/14065178.html
当当:http://product.dangdang.com/29599087.html
注:活动结束后会在我的主页动态如期公布中奖者,包邮到家。
这篇关于【python】爬取百度热搜排行榜Top50+可视化【附源码】【送数据分析书籍】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








