本文主要是介绍Hadoop大数据应用:Yarn 节点实现扩容与缩容,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、实验
1.环境
2.Yarn 节点扩容
3.Yarn 节点缩容
二、问题
1.yarn启动服务报错
一、实验
1.环境
(1)主机
表1 主机
| 主机 | 架构 | 软件 | 版本 | IP | 备注 |
| hadoop | NameNode (已部署) SecondaryNameNode (已部署) ResourceManager(已部署) | hadoop | 2.7.7 | 192.168.204.50 | |
| node01 | DataNode(已部署) NodeManager(已部署) | hadoop | 2.7.7 | 192.168.204.51 | |
| node02 | DataNode(已部署) NodeManager(已部署) | hadoop | 2.7.7 | 192.168.204.52 | |
| node03 | DataNode(已部署) NodeManager(已部署) | hadoop | 2.7.7 | 192.168.204.53 | |
| node05 | NodeManager | hadoop | 2.7.7 | 192.168.204.55 |
(2)查看jps
hadoop节点
[root@hadoop hadoop]# jps

node01节点

node02节点
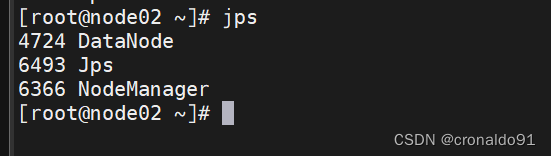
node03节点
(3) 查看节点
[root@hadoop hadoop]# ./bin/yarn node -list
24/03/14 13:40:21 INFO client.RMProxy: Connecting to ResourceManager at hadoop/192.168.204.50:8032
Total Nodes:3Node-Id Node-State Node-Http-Address Number-of-Running-Containersnode01:40551 RUNNING node01:8042 0node02:46073 RUNNING node02:8042 0node03:40601 RUNNING node03:8042 0

2.Yarn 节点扩容
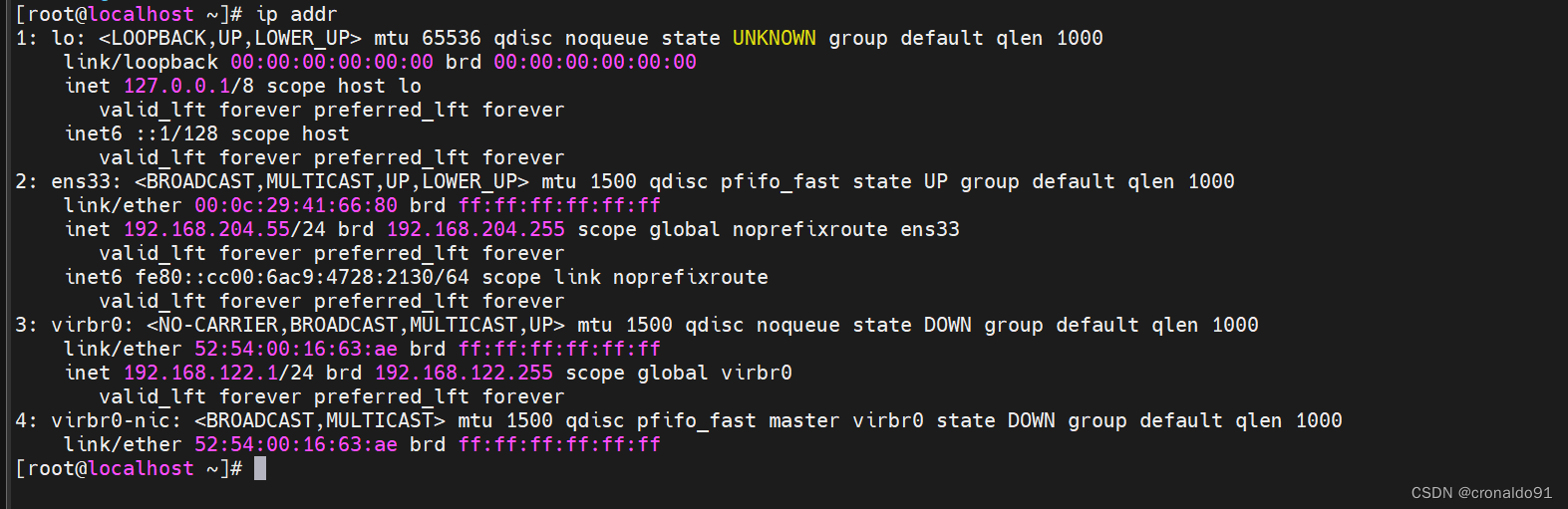
(1)查看IP
地址为192.168.204.55
[root@localhost ~]# ip addr
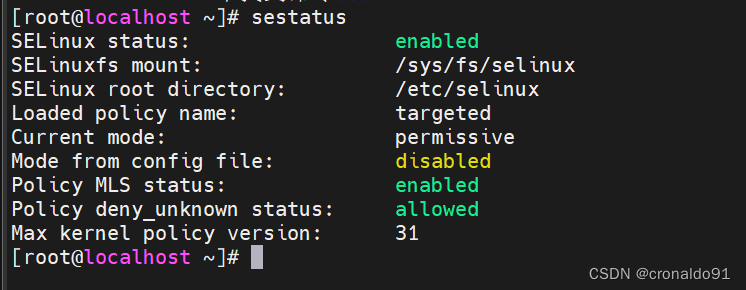
(2)安全机制
查看
[root@localhost ~]# sestatus
关闭
[root@localhost ~]# vim /etc/selinux/config
……
SELINUX=disabled
……

再次查看(需要reboot重启)
[root@localhost ~]# sestatus

(3)防火墙
关闭
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl mask firewalld

(4)安装java
[root@localhost ~]# yum install -y java-1.8.0-openjdk-devel.x86_64

查看
[root@localhost ~]# jps

(5)修改主机名
[root@localhost ~]# hostnamectl set-hostname node05
[root@localhost ~]# bash

(6)添加免密登录
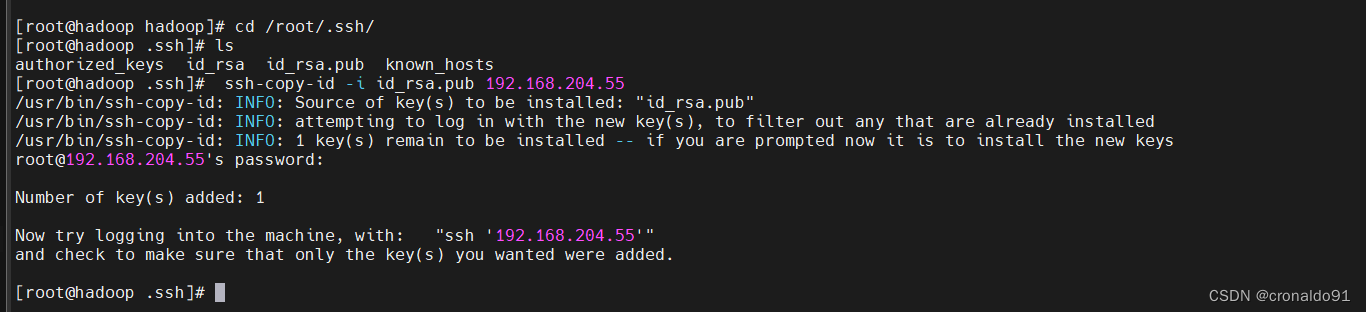
[root@hadoop ~]# cd /root/.ssh/
[root@hadoop .ssh]# ls
authorized_keys id_rsa id_rsa.pub known_hosts
[root@hadoop .ssh]# ssh-copy-id -i id_rsa.pub 192.168.204.55
验证:
[root@hadoop .ssh]# ssh 192.168.204.55

(7)域名主机名(hadoop节点)
[root@hadoop ~]# vim /etc/hosts
……
192.168.205.50 hadoop
192.168.205.51 node01
192.168.205.52 node02
192.168.205.53 node03
192.168.204.54 node04
192.168.204.55 node05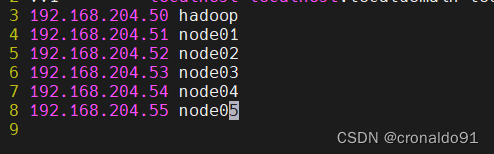
(8)同步域名配置文件
[root@hadoop ~]# rsync -av /etc/hosts node01:/etc/
sending incremental file list
hostssent 382 bytes received 41 bytes 282.00 bytes/sec
total size is 291 speedup is 0.69
[root@hadoop ~]# rsync -av /etc/hosts node02:/etc/
sending incremental file list
hostssent 382 bytes received 41 bytes 282.00 bytes/sec
total size is 291 speedup is 0.69
[root@hadoop ~]# rsync -av /etc/hosts node03:/etc/
sending incremental file list
hostssent 382 bytes received 41 bytes 846.00 bytes/sec
total size is 291 speedup is 0.69
[root@hadoop ~]# rsync -av /etc/hosts node05:/etc/
Warning: Permanently added 'node05' (ECDSA) to the list of known hosts.
sending incremental file list
hostssent 382 bytes received 41 bytes 846.00 bytes/sec
total size is 291 speedup is 0.69

(9)同步Hadoop文件
[root@hadoop ~]# rsync -aXSH --delete /usr/local/hadoop node05:/usr/local/

(10) 清除日志(node05节点)
[root@node05 ~]# cd /usr/local/hadoop/
[root@node05 hadoop]# ls
bin etc include lib libexec LICENSE.txt logs NOTICE.txt README.txt sbin share
[root@node05 hadoop]# cd logs/
[root@node05 logs]# ls
hadoop-root-balancer-hadoop.log hadoop-root-namenode-hadoop.out hadoop-root-secondarynamenode-hadoop.out yarn-root-resourcemanager-hadoop.log
hadoop-root-balancer-hadoop.out hadoop-root-namenode-hadoop.out.1 hadoop-root-secondarynamenode-hadoop.out.1 yarn-root-resourcemanager-hadoop.out
hadoop-root-namenode-hadoop.log hadoop-root-secondarynamenode-hadoop.log SecurityAuth-root.audit
[root@node05 logs]# rm -f *
[root@node05 logs]# ls
[root@node05 logs]#

(11)启动服务 (node05节点)
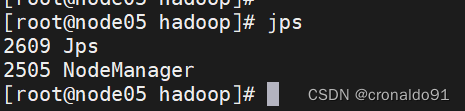
[root@node05 hadoop]# ./sbin/yarn-daemon.sh start nodemanager

查看jps 出现新角色
(15) 验证 (hadoop节点)
服务已互通
[root@hadoop hadoop]# ./bin/yarn node -list
24/03/14 18:07:06 INFO client.RMProxy: Connecting to ResourceManager at hadoop/192.168.204.50:8032
Total Nodes:4Node-Id Node-State Node-Http-Address Number-of-Running-Containersnode01:40551 RUNNING node01:8042 0node05:39920 RUNNING node05:8042 0node02:46073 RUNNING node02:8042 0node03:40601 RUNNING node03:8042 0

3.Yarn 节点缩容
(1)删除节点 (node05节点)
[root@node05 hadoop]# ./sbin/yarn-daemon.sh stop nodemanager

查看jps

(2)验证 (hadoop节点)
这时node05节点还在(因为存在检测超时)
[root@hadoop hadoop]# ./bin/yarn node -list

(3) 停止服务(hadoop节点)
[root@hadoop hadoop]# ./sbin/yarn-daemon.sh stop resourcemanager

(4)启动服务(hadoop节点)
[root@hadoop hadoop]# ./sbin/yarn-daemon.sh start resourcemanager

(5)验证 (hadoop节点)
这时暂无节点,需要等待30秒-1分钟
[root@hadoop hadoop]# ./bin/yarn node -list

(6)再次验证 (hadoop节点)
node05节点已移除
[root@hadoop hadoop]# ./bin/yarn node -list

二、问题
1.yarn启动服务报错
(1)报错
错误: 找不到或无法加载主类 nodemanager

(2)原因分析
命令错误。
(3)解决方法
修改命令,hadoop-daemon.sh 改为 yarn-daemon.sh
[root@node05 hadoop]# ./sbin/yarn-daemon.sh start nodemanager

这篇关于Hadoop大数据应用:Yarn 节点实现扩容与缩容的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




