本文主要是介绍爬虫入门到精通_实战篇12(使用Redis+Flask维护动态Cookies池),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 目标
为什么要用Cookies池
- 网站需要登录才可爬取,例如新浪微博
- 爬取过程中如果频率过高会导致封号
- 需要维护多个账号的Cookies池实现大规模爬取
Cookies池的要求
- 自动登录更新
- 定时验证筛选
- 提供外部接口
2 流程框架
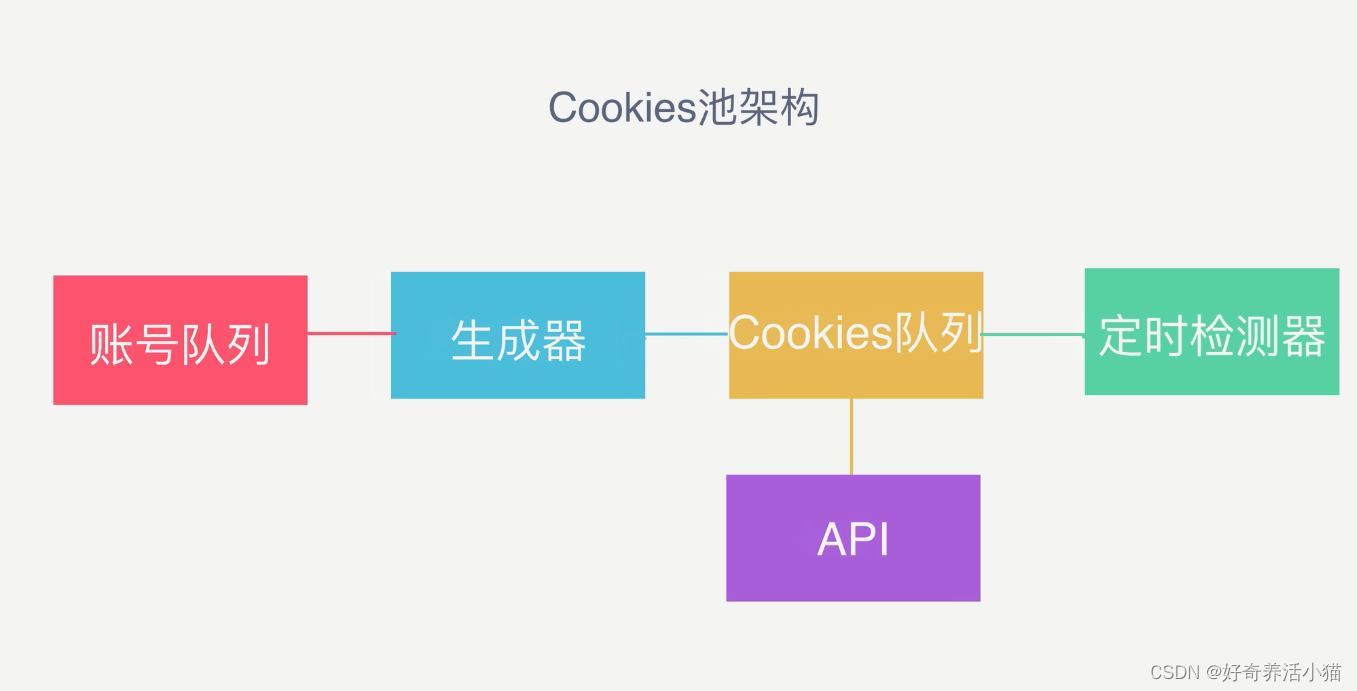
首先,需要有一个账号队列,把一些账号密码存到数据库里,生成器即程序从队列里面拿出账号密码,自动地进行登录,并获取登录的Cookies,然后放到Cookies队列里。定时检测器从Cookies队列里定期地随机选出一些Cookies,并用这些Cookies请求网页,如果请求成功就放回队列,否则从队列里剔除,这样就能做到实时更新,保证Cookies队列里的Cookies都是可用的。此外,还需要提供一个API接口,使外部程序能够从队列里获取到Cookies。
3 代码
代码下载
https://github.com/Germey/CookiesPool
https://github.com/Python3WebSpider/CookiesPool
代码结构
代码分析
config.py
配置文件

进程开关,可以模拟每次只生效其中一个

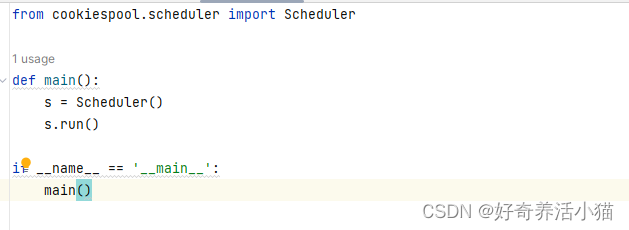
run.py
函数入口
scheduler.py
调度器方法
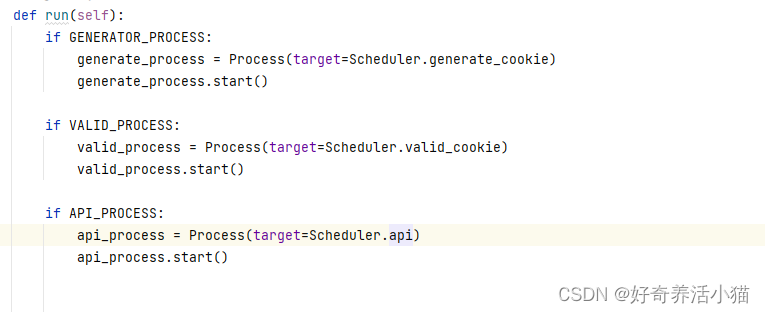
分别对应配置文件里的参数,判断生效的进程

GENERATOR_MAP:这里有多少网站,就会验证多少网站,易于扩展.
验证器

产生器

api,传入api地址和端口
db.py
redis数据库相关操作
RedisClient:通用数据库操作
CookiesRedisClient:管理Cookies的对象的数据库操作
AccountRedisClient:账号的管理的数据库操作
error.py
自定义错误

tester.py
验证器的相关操作
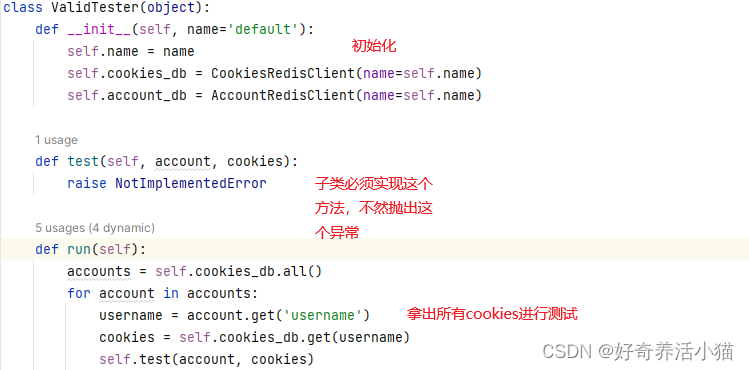
ValidTester:定义一些相关通用方法
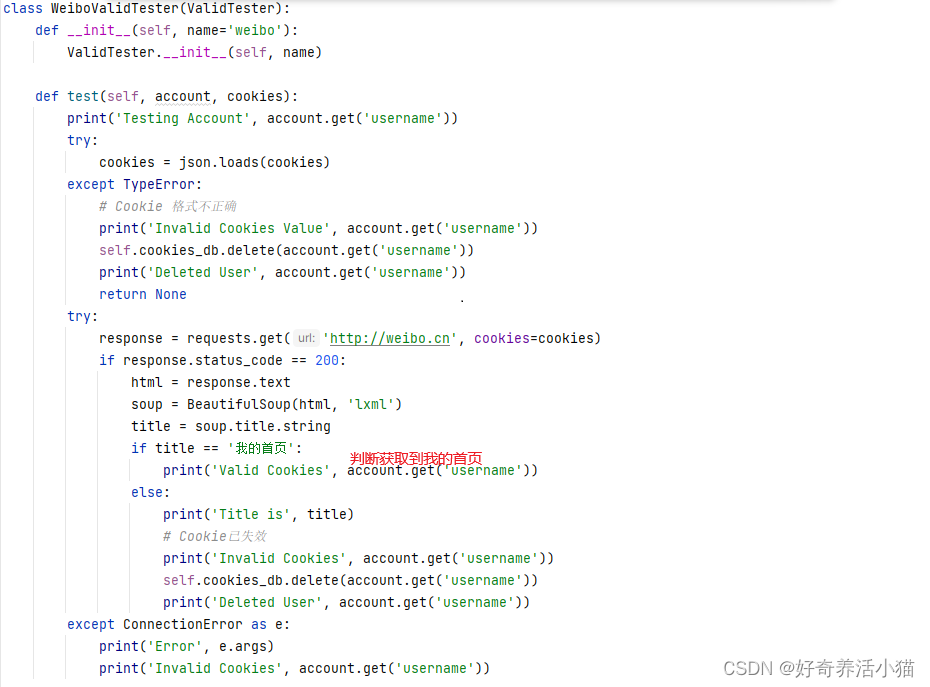
WeiboValidTester和MWeiboValidTester继承ValidTester
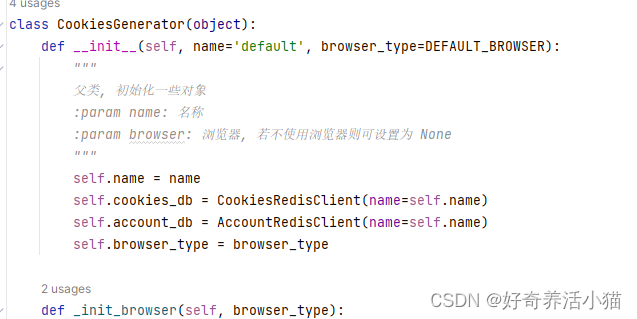
generator.py
拿出db里的账号,去微博里验证,验证后的cookies存入db.

CookiesGenerator:一些共通方法
WeiboCookiesGenerator和MWeiboCookiesGenerator继承CookiesGenerator
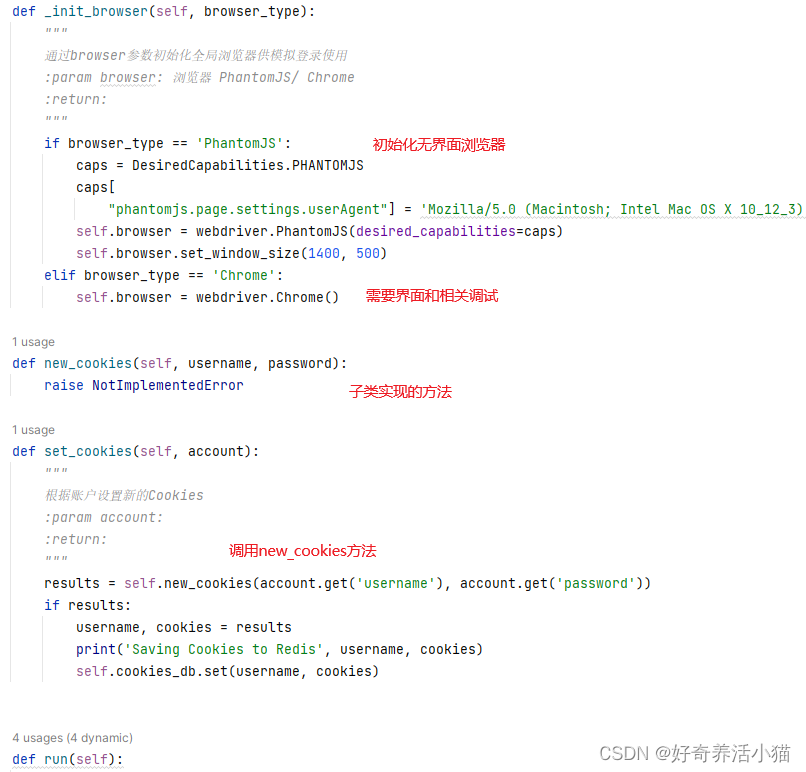
初始化操作

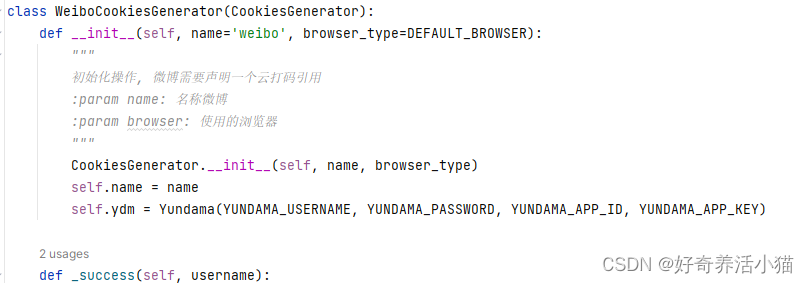
微博初始化时,一些验证码的操作Yundama.
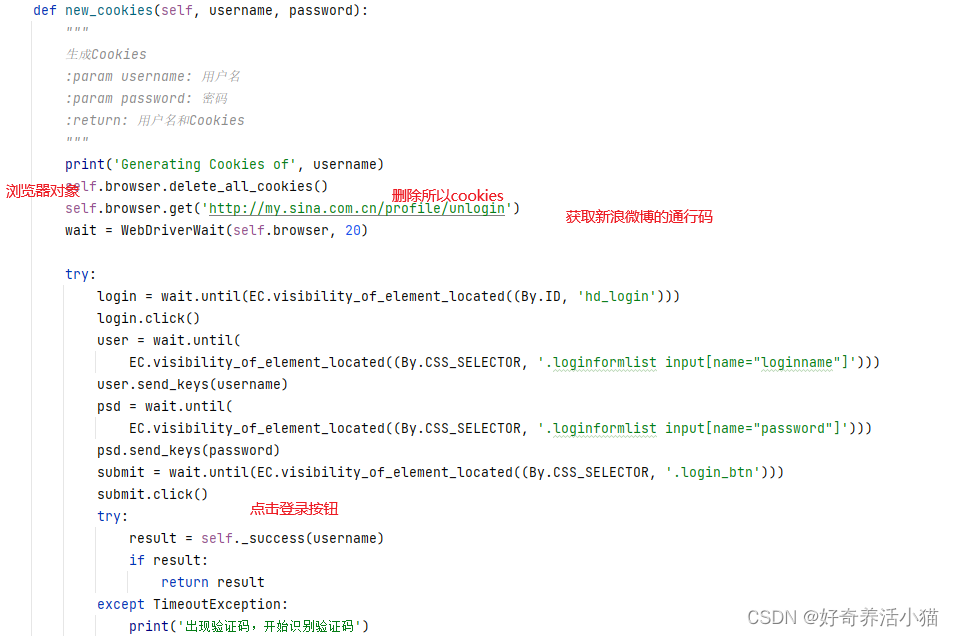
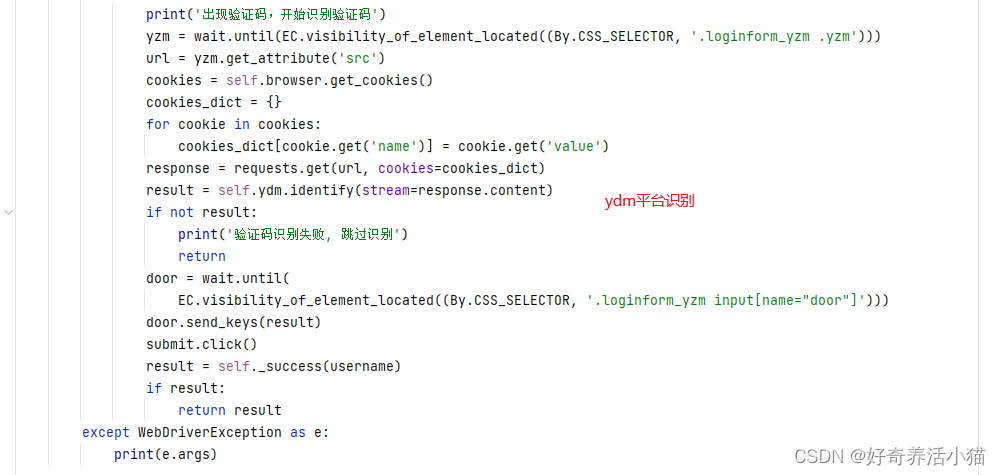
verify.py
ydm验证码的改写
这篇关于爬虫入门到精通_实战篇12(使用Redis+Flask维护动态Cookies池)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






