本文主要是介绍PCIe系列专题之三:3.2 数据链路层Ack/Nak机制解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、故事前传
前面的文章针对PCIe的一部分内容已经做了解析。
较为详细解释请见之前的文章:
1. PCIe技术概述;
2.0~2.8 PCIe Transaction layer事务层详细解析;
3.0 PCIe数据链路层概述;
3.1 PCIe数据链路层DLLP结构与类型介绍;
二、Ack/Nak机制
在上一篇文章"DLLP结构与类型"中,我们有说到,数据链路层会产生多个DLLP。其中有两个DLLP分别是Ack DLLP和Nak DLLP。这两个DLLP均是由接收端传至发送端,也可以理解为一种反馈机制。
Ack DLLP: 表示接收端收到了来自发送端的正确的TLP报文;
Nak DLLP: 表示接收端有来自发送端的TLP报文没有被正确接收,需要发送端重新发送。
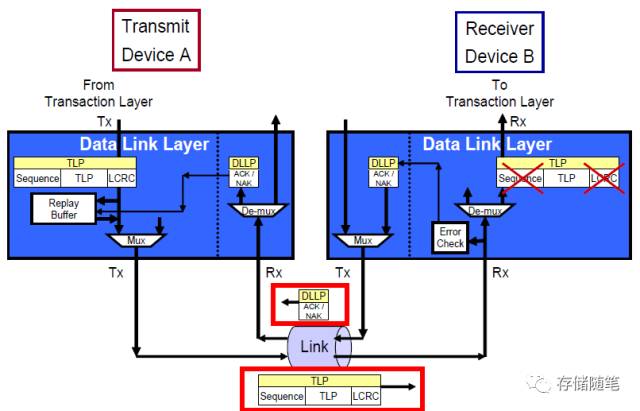
我们通过下面这张图,先来大致了解一下Ack/Nak的工作机制:
发送端数据链路层传送一个TLP(Sequence+TLP+LCRC),通过Link,到达接收端。
接收端接收到来自发送端数据链路层的TLP报文之后,先检验LCRC,在检验Sequence ID。
当Sequence ID和LCRC检验均正确时,接收端返回Ack DLLP告知发送端:"您发送的TLP,我方已正确接收,请知悉!"。
当Sequence ID或者LCRC检验中,发现哪怕一个错误,接收端都会返回Nak DLLP告知发送端:"对不起,您发送的TLP没有被正确接收,请您再发送一下"。
现在大概知道Ack/Nak的工作机制了吧?继续往下看,再来一张图。

是不是有点晕?小编第一次看到的时候也晕~
上面这幅图是数据链路层Ack/Nak机制详细的结构图,理解了上面这幅图就基本掌握了Ack/Nak机制。
不要被上面这幅图吓到,我们下面就一步一步地解析:
1. 从发送端事务层传送的TLP达到数据链路层
如下图红色圈内所示。
不过,这里需要注意的是:当Retry buffer是满的或者正在执行重新发送TLP的状态,数据链路层将会锁定TLP传送,不再接收。

2. 为TLP分配Sequence ID
当TLP到达数据链路层之后,第一件事就是被分配Sequence ID。也可以理解为给TLP一个身份编号,以便于后续的检验工作。
这里还要提一个参数:NEXT_TRANSMIT_SEQ, 简称NTS,是一个12位的Sequence ID计数器,初始值为0,最大取值为4095。一个TLP被分配Sequence ID之后,NTS会加1,然后把累加后的数值再赋值给下一个TLP。
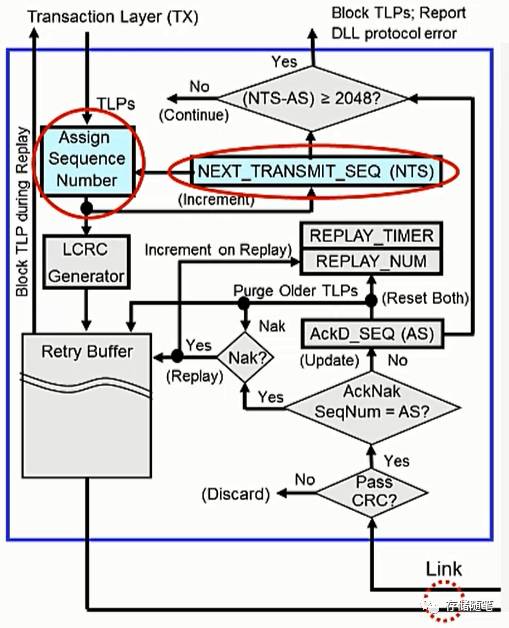
3. 为TLP增加LCRC
TLP分配Sequence ID之后,下一步就是生成LCRC。

LCRC为32位,基于事务层传送的TLP和数据链路层分配的Sequence ID生成。

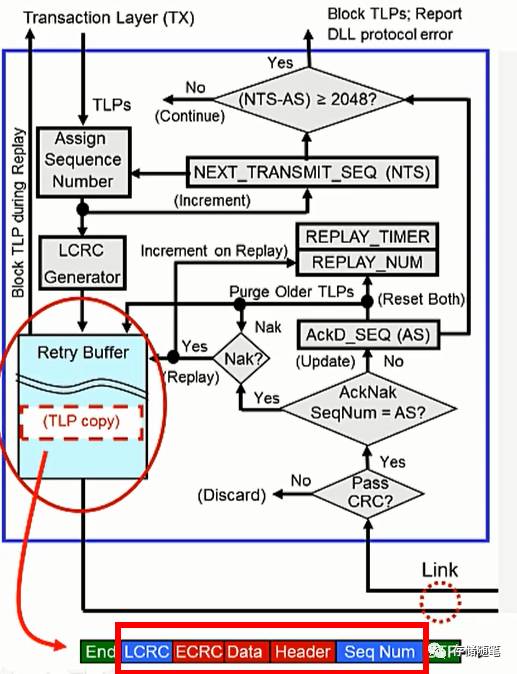
4. 将TLP在Retry Buffer备份
TLP在加上前缀Sequence ID和后缀LCRC之后,会在Retry Buffer里面完整备份。
单个TLP最大占用的Retry Buffer大小为:4122 Bytes ( 2 bytes Sequence ID + 16 bytes Header + 4096 bytes Data + 4 bytes ECRC + 4 bytes LCRC ).
PCIe Spec中并没有规定Retry Buffer大小,不同的设计采用的大小不同,但是必须保证在TLP传输的过程中不能遇到瓶颈.
5. 接收端对接收的TLP进行LCRC检查

接收端接收到发送端传来的TLP后会先根据Sequence ID, Header, Data, ECRC计算LCRC,然后再跟传进来的LCRC对比,检查是否一致。

6. LCRC检查fail
当LCRC检查fail时,会舍弃刚才传进来的TLP,并将NAK_SCHEDULED标志位置起来,给发送端回报NAK DLLP。此外将期望接收到
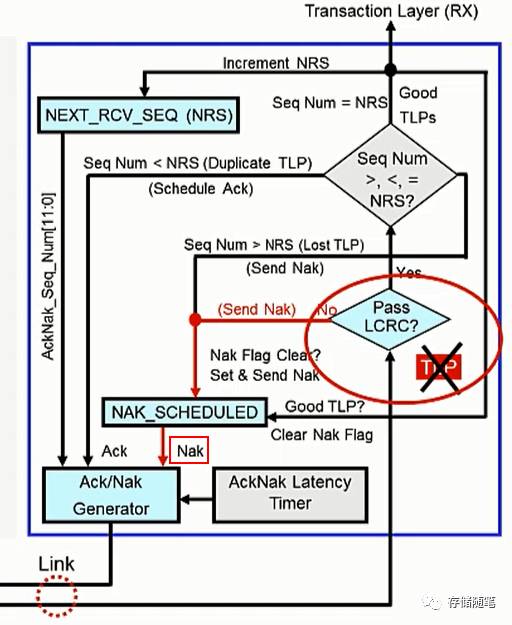
7. LCRC检查OK,检查Sequence ID。
当TLP的LCRC检查OK之后,接收端继续检查Sequence ID。这里出现了新的参数:NEXT_RSV_SEQ,简称NRS,用于追踪下一个期望获得的TLP的Sequence ID,NRS有12位,取值范围0~4095。
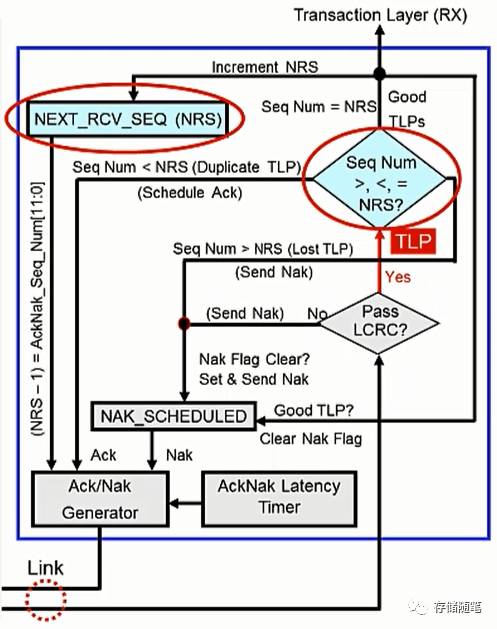
检查Sequence ID时分为三个情况:
Sequence ID=NRS, 代表是TLP接收正确;
Sequence ID<NRS, 代表是TLP是重复的;
Sequence ID>NRS, 代表是TLP有发生丢失的情况;
(1) 当Sequence ID=NRS时,
这个情况下,正确接收TLP,并将TLP传送至上次事务层。同时NRS要加1,准备接收下一个TLP。另外还要给发送端回报Ack DLLP告知发送端已正确接收TLP。
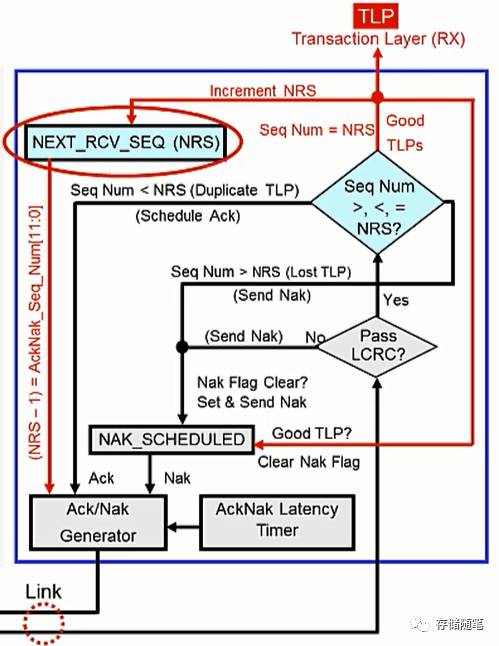
(2) 当Sequence ID<NRS时,
这个情况下,代表接收端收到了重复的TLP。当下收到的这个TLP会被舍弃,此时NRS保持原有数值,并给发送端回报上一个有效TLP的Ack DLLP。

(3) 当Sequence ID>NRS时,
这个情况下,代表当下Sequence ID之前的TLP丢失。当下收到的这个TLP会被舍弃,此时NRS保持原有数值,NAK_SCHEDULED标志位被置起,并给发送端回报上一个有效TLP的Ack DLLP。

8. Ack/Nak Latency Timer
接收端还有一个重要的参数:Ack/Nak Latency Timer。延迟时间不是固定的,与Link Width, Max Payload有关。
Latency timer超时,Ack/Nak生成器会给发送端发送Ack DLLP。发送Ack DLLP之后,Latency Timer会重置。

9. 发送端检查接收端返回的DLLPs
当发送端收到接收端返回Ack/Nak DLLPs之后,会先检查其CRC,如下图红色圈内所示。

发送端会根据Ack/Nak DLLPs的Byte0~3计算CRC,并与传进来的CRC作对比,验证是否一致。

(1) CRC检查 fail
只要CRC检查fail, 当下的Ack/Nak DLLPs就会被舍弃。
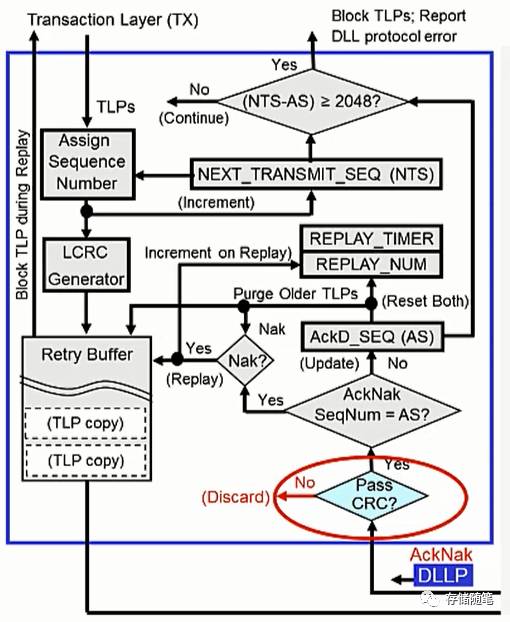
(2) CRC检查OK之后,继续后续步骤
10. 发送端检查AS参数
这里有一个新的参数:Acknowledged Sequence Numbers, 简化标记为AckD_SEQ, 缩写为AS。AckD_SEQ是一个12位的计数器,用于记载最近收到的Ack/Nak DLLP中的Sequence ID。
当发送端收到的Ack/Nak DLLP中的Sequence ID大于AS时,代表TLPs传输正在进行中。

11. 接收到Nak DLLP,TLP retry
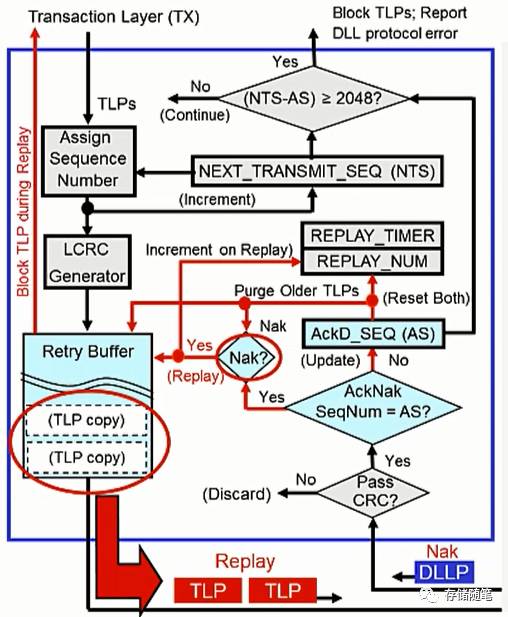
当发送端接收到一个Nak DLLP时,代表前面传送的TLP有问题,需要重新发送。此时会有两种情况:
(1) 如果Nak DLLP的Sequence ID=AS:
这个情况下,说明没有新的TLP传输。此时需要将Retry buffer中所有的TLPs重新发送,并且更新Relay_NUM加1.
(2) 如果Nak DLLP的Sequence ID>AS:
这个情况下,说明有新的TLP传输。此时需要将Retry buffer中Nak DLLP中Sequence ID之前的TLP全部清空,并将当下的TLP重新发送。与此同时,将Replay_TIMER以及Replay_NUM重置,并且Replay_NUM重置后加1.
12. NTS-AS>=2048?
发送端在接收到Ack/Nak DLLPs最后一步要检验NTS-AS差值,NTS-AS差值最小为2048.
如果NTS-AS>=2048不成立,则说明数据链路层有协议错误。
如果NTS-AS>=2048成立,则数据链路层继续传输TLPs。

看完上面的理论之后是不是还有点晕晕的~我们再来看两个例子加深一下理解。
例1: TLPs丢失
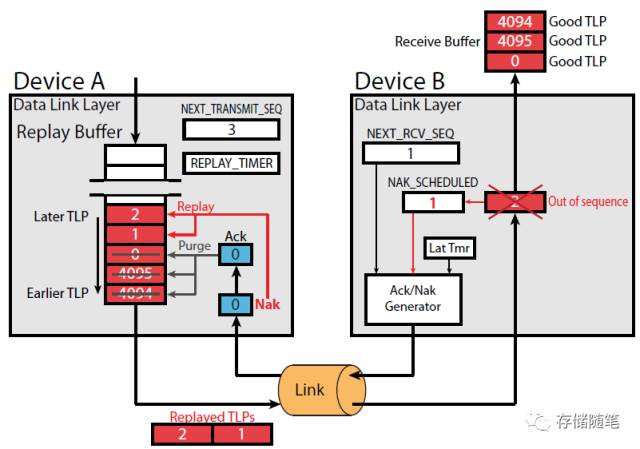
(1) 下图中,Device A要给Device B传输5个TLPs, Sequence ID分别是4094,4095,0,1,2.
(2) TLP 4094第一个被成功接收,返回Ack DLLP给Device A, 同时Next_RCV_SEQ加1(也就是=4095)。
(3) TLP 4095第二个被成功接收,返回Ack DLLP给Device A, 同时Next_RCV_SEQ加1(也就是=0,因为4095+1超过了Next_RCV_SEQ的最大取值4095,从0开始记)。
(4) TLP 4094第三个被成功接收,返回Ack DLLP给Device A, 同时Next_RCV_SEQ加1(也就是=1)。
(5) 在TLP 0被成功接收之后,AckNak_LATENCY_TIMER超时,重新发送Sequence ID=0对应的Ack DLLP。
(6) TLP1在传输的过程中由于某些原因(比如物理层的Error)丢失,TLP 2继续传输。但是在Device B端在等待TLP 1。比较Sequen ID (=2)与NRS(=1)发现,Sequence ID>NRS, Device B端才知道有TLP丢失。此时将TLP 2丢弃,并回报 NRS-1( 1-1=0)对应的Nak,也就是Nak 0.
(7) Device A端接收到Sequence ID=0对应的Ack DLLP之后,重新发送TLP 1和TLP2,并且将Sequence ID=0之前的TLPs(4094,4095,0)全部从Retry Buffer里面清除。
例2: Nak DLLP错误
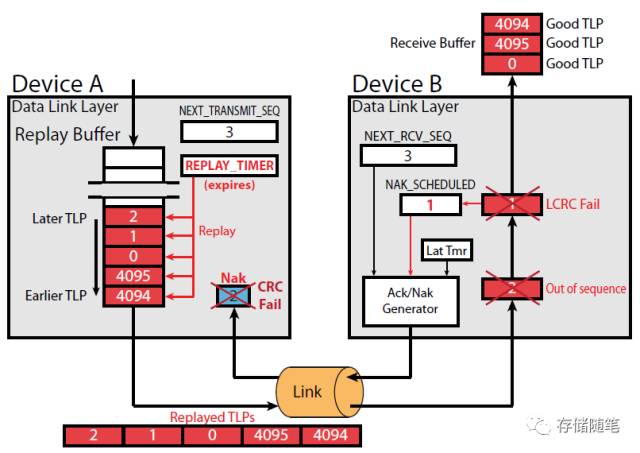
(1) 下图中,Device A要给Device B传输5个TLPs, Sequence ID分别是4094,4095,0,1,2.
(2) TLP 4094,4095, 0被依次成功接收,此时Next_RCV_SEQ=1。
(3) 在TLP 1到达Device B端,检查32-bit LCRC fail. 此时,返回NRS-1对应的Nak DLLP,也就是Nak 0。
(4) Nak 0到达Device A端,检查16-bit CRC fail,Nak 0则被丢弃。
(5) Nak 0被丢弃后,Device B不会再发送任何Ack或者Nak。由于长时间没有收到Device B的反馈(Ack/Nak),Replay_TIMER超时,Device A将Retry buffer中所有的TLPs重新发送。
(6) TLP 4094,4095,0重新发送后在Device B端会被识别到时重复的TLPs, 然后被丢弃。TLP1,2继续正确传输。
这篇关于PCIe系列专题之三:3.2 数据链路层Ack/Nak机制解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




