本文主要是介绍【海贼王的数据航海】栈和队列,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1 -> 栈
1.1 -> 栈的概念及结构
1.2 -> 栈的实现
1.2.1 -> Stack.h
1.2.2 -> Stack.c
1.2.3 -> Test.c
2 -> 队列
2.1 -> 队列的概念及结构
2.2 -> 队列的实现
2.2.1 -> Queue.h
2.2.2 -> Queue.c

1 -> 栈
1.1 -> 栈的概念及结构
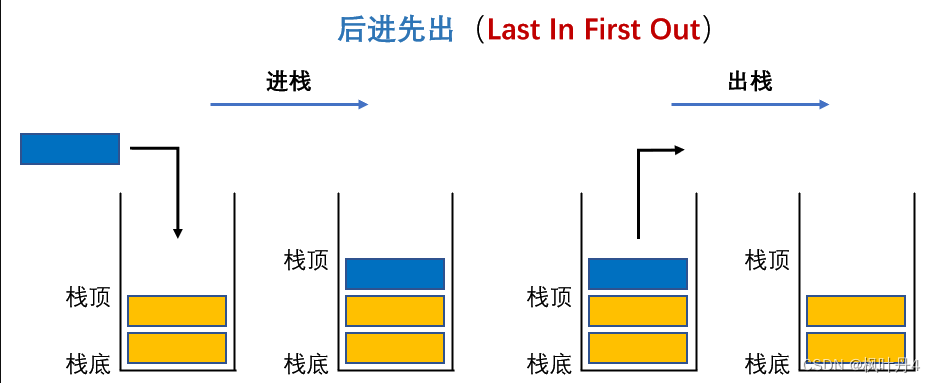
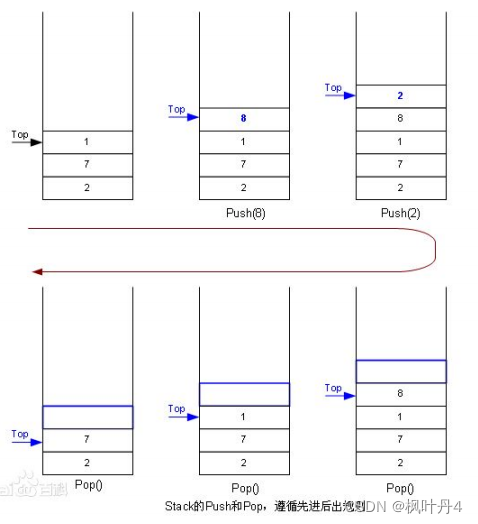
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。
压栈:栈的插入操作叫进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈。出数据也在栈顶。
1.2 -> 栈的实现
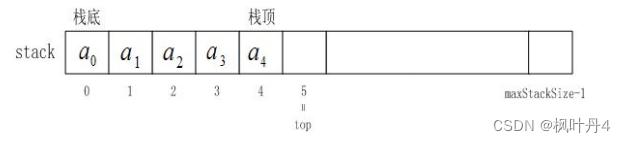
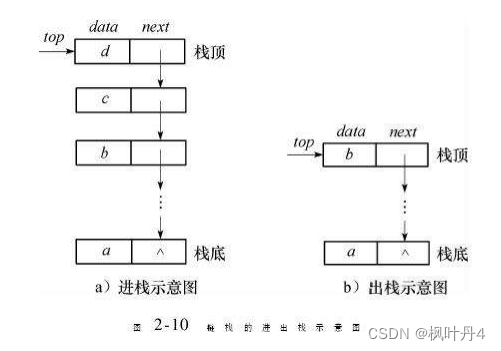
栈的实现一般可以使用数组或链表实现,相对而言数组的结构实现更优。因为数组在尾上插入数据的代价比较小。
1.2.1 -> Stack.h
#pragma once#define _CRT_SECURE_NO_WARNINGS 1#include <stdio.h>
#include <assert.h>
#include <stdbool.h>// 定长的静态栈的结构,实际中一般不实用
//typedef int STDataType;
//#define N 10
//typedef struct Stack
//{
// STDataType a[N];
// int top;
//}ST;// 动态增长的栈
typedef int STDataType;
typedef struct Stack
{STDataType* a;int top;int capacity;
}ST;// 栈的初始化
void STInit(ST* pst);// 栈的销毁
void STDestroy(ST* pst);// 入栈
void STPush(ST* pst, STDataType x);// 出栈
void STPop(ST* pst);// 获取栈顶元素
STDataType STTop(ST* pst);// 判空
bool STEmpty(ST* pst);// 栈的有效元素个数
int STSize(ST* pst);1.2.2 -> Stack.c
#include "Stack.h"// 栈的初始化
void STInit(ST* pst)
{assert(pst);pst->a = NULL;pst->top = 0;pst->capacity = 0;
}// 栈的销毁
void STDestroy(ST* pst)
{assert(pst);free(pst->a);pst->a = NULL;pst->top = 0;pst->capacity = 0;
}// 入栈
void STPush(ST* pst, STDataType x)
{if (pst->top == pst->capacity){int newCapacity = pst->capacity == 0 ? 4 : pst->capacity * 2;STDataType* tmp = (STDataType*)realloc(pst->a, newCapacity * sizeof(STDataType));if (tmp == NULL){perror("realloc fail");return;}pst->a = tmp;pst->capacity = newCapacity;}pst->a[pst->top] = x;pst->top++;
}// 出栈
void STPop(ST* pst)
{assert(pst);assert(!STEmpty(pst));pst->top--;
}// 获取栈顶元素
STDataType STTop(ST* pst)
{assert(pst);assert(!STEmpty(pst));return pst->a[pst->top - 1];
}// 判空
bool STEmpty(ST* pst)
{assert(pst);return pst->top == 0;
}// 栈的有效元素个数
int STSize(ST* pst)
{assert(pst);return pst->top;
}1.2.3 -> Test.c
#include "Stack.h"void Test1()
{ST st;STInit(&st);STPush(&st, 1);STPush(&st, 2);printf("%d\n", STTop(&st));STTop(&st);STPush(&st, 3);STPush(&st, 4);STPush(&st, 5);while (!STEmpty(&st)){printf("%d ", STTop(&st));STPop(&st);}STDestroy(&st);
}int main()
{Test1();return 0;
}2 -> 队列
2.1 -> 队列的概念及结构
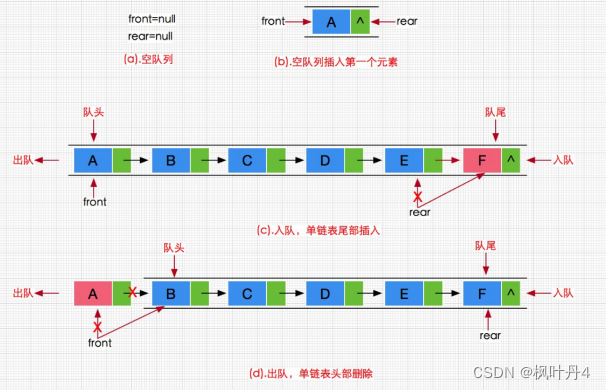
队列:只允许一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(First In First Out)。
入队列:进行插入操作的一端称为队尾。
出队列:进行删除操作的一端称为队头。

2.2 -> 队列的实现
队列也可以用数组和链表的结构实现,使用链表的结构实现更优,因为如果使用数组的结构,出队列在数组头上出数据,效率较低。
2.2.1 -> Queue.h
#pragma once#define _CRT_SECURE_NO_WARNINGS 1#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>// 链式结构: 表示队列
typedef int QDataType;typedef struct QueueNode
{struct QueueNode* next;QDataType data;
}QNode;typedef struct Queue
{QNode* phead;QNode* ptail;int size;
}Queue;// 队列的初始化
void QueueInit(Queue* pq);// 队列的销毁
void QueueDestroy(Queue* pq);// 队尾入队列
void QueuePush(Queue* pq, QDataType x);// 队头出队列
void QueuePop(Queue* pq);// 获取队头元素
QDataType QueueFront(Queue* pq);// 获取队尾元素
QDataType QueueBack(Queue* pq);// 获取队列中有效元素个数
int QueueSize(Queue* pq);// 判空
bool QueueEmpty(Queue* pq);2.2.2 -> Queue.c
#include "Queue.h"// 队列的初始化
void QueueInit(Queue* pq)
{assert(pq);pq->phead = NULL;pq->ptail = NULL;pq->size = 0;
}// 队列的销毁
void QueueDestroy(Queue* pq)
{assert(pq);QNode* cur = pq->phead;while (cur){QNode* next = cur->next;free(cur);cur = next;}pq->phead = NULL;pq->ptail = NULL;pq->size = 0;
}// 队尾入队列
void QueuePush(Queue* pq, QDataType x)
{assert(pq);QNode* newnode = (QNode*)malloc(sizeof(QNode));if (newnode == NULL){perror("malloc fail");return;}newnode->data = x;newnode->next = NULL;if (pq->ptail == NULL){assert(pq->phead == NULL);pq->phead = newnode;pq->ptail = newnode;}else{pq->ptail->next = newnode;pq->ptail = newnode;}pq->size++;
}// 队头出队列
void QueuePop(Queue* pq)
{assert(pq);assert(!QueueEmpty(pq));if (pq->phead->next == NULL){free(pq->phead);pq->phead = NULL;pq->ptail = NULL;}else{QNode* next = pq->phead->next;free(pq->phead);pq->phead = next;}pq->size--;
}// 获取队头元素
QDataType QueueFront(Queue* pq)
{assert(pq);assert(!QueueEmpty(pq));return pq->phead->data;
}// 获取队尾元素
QDataType QueueBack(Queue* pq)
{assert(pq);assert(!QueueEmpty(pq));return pq->ptail->data;
}// 获取队列中有效元素个数
int QueueSize(Queue* pq)
{assert(pq);return pq->size;
}// 判空
bool QueueEmpty(Queue* pq)
{assert(pq);return pq->size == 0;
}感谢各位大佬支持!!!
互三啦!!!
这篇关于【海贼王的数据航海】栈和队列的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






