本文主要是介绍作为网工有必要了解一下什么是SRv6,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
知识改变命运,技术就是要分享,有问题随时联系,免费答疑,欢迎联系!

①微思网络,始于2002年!专注IT认证培训22年。
② 领取学习资料/课程咨询:+小美老师(wx):18106083689 ,加好友即送学习大礼包,邀请您加入IT精英学习群(每天分享技术文档、行业资讯,免费公开课)。
③ 微思有哪些培训及考证?
网络管理(华为认证HCIA/HCIP/HCIE;思科认证);Linux(红帽RHCE/RHCA);K8S&容器(CKA/CKS
);数据库(ORACLE OCP/OCM;MySQL);虚拟化( VMware VCP/VCAP);热门安全认证(CISP体系/CISSP/ CISA/CCSK/CISAW);管理类(PMP 项目管理;软考中/高项;ITIL体系;Togaf)等等
④ 循环开班,面授班&直播班,免费重听,学会为止
SRv6(Segment Routing IPv6,基于IPv6转发平面的段路由)简单来讲即SR(Segment Routing)+IPv6,是新一代IP承载协议。其采用现有的IPv6转发技术,通过灵活的IPv6扩展头,实现网络可编程。
SRv6简化了网络协议类型,具有良好的扩展性和可编程性,可满足更多新业务的多样化需求,提供高可靠性,在云业务中有良好的应用前景。
为什么需要SRv6?
传统网络困局
全球信息化的进程使得互联网应用得到了迅速而蓬勃的发展,随着网络规模的扩大以及云时代的到来,网络业务种类越来越多,不同业务对网络的要求不尽相同,传统IP/MPLS网络遇到不少挑战:
- IP承载网的孤岛问题。MPLS统一了承载网,但是IP骨干网、城域网、移动承载网之间是独立的MPLS域,是相互分离的,需要使用跨域VPN等复杂的技术来互联,导致端到端业务的部署非常复杂。 而且在L2VPN、L3VPN多种业务并存的情况下,设备中可能同时存在LDP、RSVP、IGP、BGP等协议,管理复杂,不适合大规模业务部署。
- IPv4与MPLS的可编程空间有限。当前很多新业务需要在转发平面加入更多的转发信息,但IETF已经发表声明,停止为IPv4制定更新的标准;另外MPLS只有20bit的标签空间,且标签字段固定、长度固定,缺乏可扩展性,导致很难满足未来业务的网络编程需求。
- 应用与承载网隔离。目前应用与承载网的解耦,导致网络自身的优化困难,难以提升网络的价值。当前运营商普遍面临被管道化的挑战,无法从增值应用中获得相应的收益;而应用信息的缺失,也使得运营商只能采用粗放的方式进行网络调度和优化,造成资源的浪费。MPLS也曾试图更靠近主机和应用,但因为其本身网络边界多、管理复杂度大等多方面的原因,均以失败告终。
- 传统网络数据面和控制面紧密耦合,相互绑定销售,在演进上相互依赖,业务上线周期长,难以应对现在新兴业务快速发展的局面。
SRv6的出现解决了上述一系列问题,推动网络进入一个全新的时代。
SRv6技术价值
SRv6是基于IPv6转发平面的SR技术,其结合了SR源路由优势和IPv6简洁易扩展的特质,具有其独特的优势。SRv6技术特点及价值可以归纳为以下三点:
- 智慧:
-
- SRv6具有强大的可编程能力。SRv6具有网络路径、业务、转发行为三层可编程空间,使得其能支撑大量不同业务的不同诉求,契合了业务驱动网络的大潮流。
- SRv6完全基于SDN架构,可以跨越APP和网络之间的鸿沟,将APP的应用程序信息带入到网络中,可以基于全局信息进行网络调度和优化。
- 极简:
-
- SRv6不再使用LDP/RSVP-TE协议,也不需要MPLS标签,简化了协议,管理简单。EVPN和SRv6的结合,可以使得IP承载网简化归一。

-
- SRv6打破了MPLS跨域边界,部署简单,提升了跨域体验。
- 纯IP化:SRv6基于Native IPv6进行转发。SRv6是通过扩展报文头来实现的,没有改变原有IPv6报文的封装结构,SRv6报文依然是IPv6报文,普通的IPv6设备也可以识别SRv6报文。SRv6设备能够和普通IPv6设备共同部署,对现有网络具有更好的兼容性,可以支撑业务快速上线,平滑演进。另外基于Native IPv6,使得其可以进入数据中心网络,甚至用户终端,促进云网融合。
SRv6基于以上特点,成为构建“智简IP”的利器。同时也为IPv6的发展带来了转机,开启了IPv6+新时代。
什么是Segment Routing?
前面提到,SRv6即SR+IPv6。IPv6大家都知道,那什么是SR呢?
SR技术是SDN竞争压力下的产物,其核心思想是将报文转发路径切割为不同的分段,并在路径起始点往报文中插入分段信息,中间节点只需要按照报文里携带的分段信息转发即可。这样的路径分段,称之为“Segment”,并通过SID(Segment Identifier,段标识)来标识。
SR的设计理念在现实生活中屡见不鲜,下面举一个例子,来更好的理解其原理。假设你从上海出发去巴黎旅游,需要在维也纳转机。那你的出行路线分为两段,上海→维也纳、维也纳→巴黎。则你只需要在上海买好上海途经维也纳到巴黎的票,按照计划根据机票,经过两段,飞到巴黎即可。

上海到巴黎出行图
报文在SR技术的转发过程也是类似的。由上可知,SR技术关键在于两点:对路径进行分段(Segment)以及在起始节点对路径进行排序组合(Segment List),确定出行路径。
在SR技术中,将代表不同功能的Segment进行组合,可以实现对路径的编程,满足不同路径服务质量的需求。
SR技术支持MPLS和IPv6两种转发平面,基于MPLS转发平面的SR称为SR-MPLS(Segment Routing MPLS),其SID为MPLS标签(Label);基于IPv6转发平面的SR称为SRv6,其SID为IPv6地址。
SRv6如何实现网络编程?
SR技术中,通过对Segment的组合,实现路径编程。那SRv6是如何实现网络编程的呢?
SRv6将网络比作计算机,类比计算机编程,将网络承载的业务翻译成发给沿途网络设备的一系列转发指令,从而实现网络编程,满足业务的定制化需求。
SRH
为基于IPv6转发平面实现SR技术,在IPv6路由扩展头新增SRH(Segment Routing Header)扩展头,该扩展头指定一个IPv6的显式路径,存储IPv6的Segment List信息。Segment List即对段和网络节点进行有序排列得到的一条转发路径。报文转发时,依靠Segments Left和Segment List字段共同决定IPv6目的地址(IPv6 DA)信息,从而指导报文的转发路径和行为。
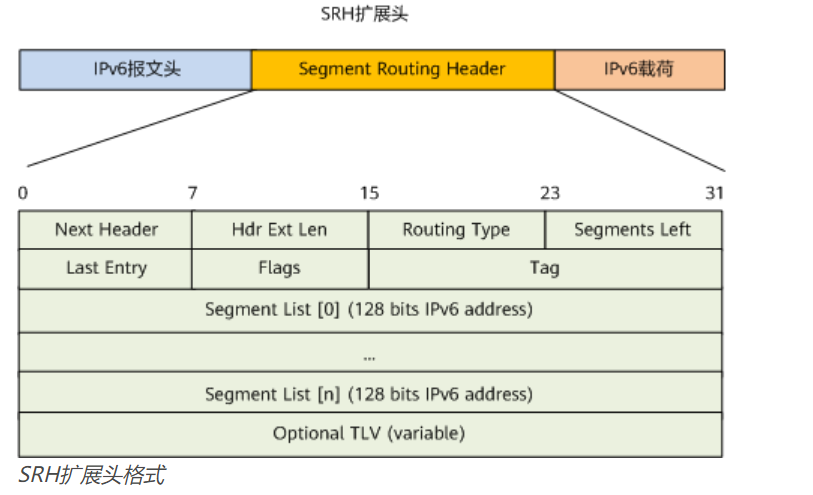
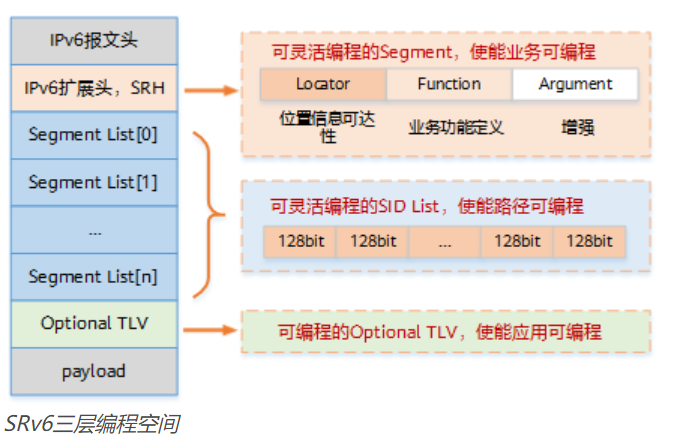
三层可编程空间
SRv6的可编程能力来源于三部分:
- Segment序列。如前所述,可以将多个Segment组合起来,形成SRv6路径,即路径可编辑。
- 对SRv6 SID 128bit的运用。SRv6 Segment定义了SRv6网络编程中的网络指令,指示要去哪,怎么去。标识SRv6 Segment的ID被称为SRv6 SID。SRv6 SID是一个128bit的值,为IPv6地址形式,由Locator、Function和Arguments三部分组成。
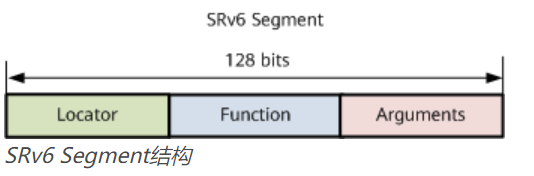
-
- Locator:具有定位功能。提供IPv6的路由能力,报文通过该字段实现寻址转发。此外,Locator对应的路由也是可聚合的。
- Function:用来表达该设备指令要执行的转发动作,不同的转发行为由不同的Function来表达。
- Arguments:可选字段,是对Function的补充,是指令在执行时对应的参数,这些参数可能包含流、服务或任何其他相关的信息。
- SRv6的每个Segment是128bit,可以灵活分为多段,每段功能和长度可以自定义,由此具备灵活编程能力,即业务可编辑。
- Segment序列之后的Optional TLV(Type-Length-Value)。报文在网络中传送时,需要在转发面封装一些非规则的信息,可以通过SRH中TLV的灵活组合来完成,即应用可编辑。
SRv6通过以上三层编程空间,具备了更强大的网络编程能力,可以更好地满足不同的网络路径需求,和SDN技术完美融合,实现网络与应用的互动,使能业务驱动的可编程网络。
SRv6在网络中是如何工作的?
SRv6具有超强的网络编程能力,那其在网络中具体是怎样工作的呢?下面我们通过SRv6报文转发流程和SRv6的工作模式两方面来讲其在网络中的工作实现。
报文转发流程
采用示例说明SRv6的报文转发流程。
如图所示,假设有报文需要从主机1转发到主机2,主机1将报文发送给节点A处理。节点A、B、D、E均支持SRv6,节点C不支持SRv6,只支持IPv6。我们在源节点A上进行网络编程,希望报文经过B-C、C-D链路,送达节点E,由E节点送达主机2。

报文转发流程分为以下几步:
- 源节点A将SRv6路径信息封装在SRH中,指定B-C,C-D链路的SID,另外封装E点发布的SID A5::10(此SID对应于节点E的一个IPv4 VPN),共3个SID,按照逆序形式压入SID序列。此时SL(Segment Left)=2,将Segment List[2]值复制到目的地址DA字段,按照最长匹配原则查找IPv6路由表,将其转发到节点B。
- 报文到达节点B,B节点查找本地SID表(存储本节点生成的SRv6 SID信息),命中自身的SID(End.X SID),执行SID对应的指令动作。SL值减1,并将Segment List[1]值复制到DA字段,同时将报文从SID绑定的链路(B-C)发送出去。
- 报文到达节点C,C无SRv6能力,无法识别SRH,按照正常IPv6报文处理流程,按照最长匹配原则查找IPv6路由表,将其转发到当前目的地址所代表的节点D。
- 节点D收报文后根据目的地址A4::45查找本地SID表,命中自身的SID(End.X SID)。同节点B,SL值减1,将A5::10作为DA,并将报文发送出去。
- 节点E收到报文后根据A5::10查找本地SID表,命中自身SID(End.DT4 SID),执行对应的指令动作,解封装报文,去除IPv6报文头,并将内层IPv4报文在SID绑定的VPN实例的IPv4路由表中进程查表转发,最终将报文发送给主机2。
SRv6工作模式
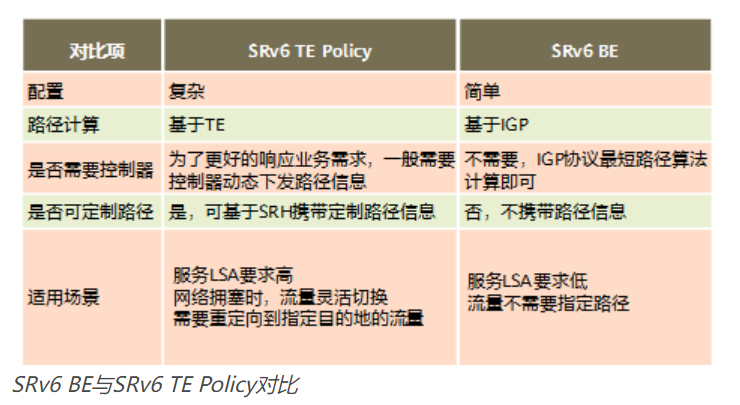
SRv6工作模式分为两种:SRv6 BE(Segment Routing IPv6 Best Effort)和SRv6 TE Policy(Segment Routing IPv6 Traffic Engineering Policy)。两种模式都可以用来承载传统业务,比如L3VPN、EVPN L3VPN、EVPN VPLS 、EVPN VPWS、公网IP等。
SRv6 TE Policy
SRv6 TE Policy利用Segment Routing的源路由机制,通过在头节点封装一个有序的指令列表(路径信息)来指导报文穿越网络。SRv6 TE Policy用于实现流量工程,提升网络质量,满足业务的端到端需求。其和SDN结合,更好的契合于业务驱动网络的大潮流,也是SRv6主推的工作模式。
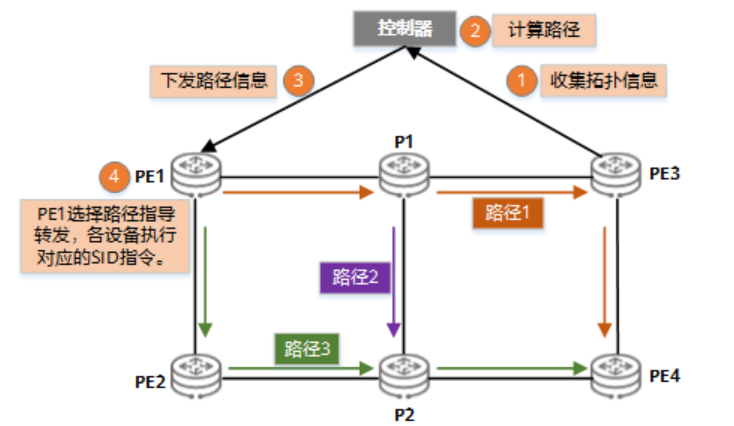
SRv6 TE Policy工作流程
SRv6 TE Policy的工作流程可分为四步:
- 转发器(PE3)通过BGP-LS将网络拓扑信息上报给控制器。拓扑信息包括节点链路信息、链路的开销/带宽/时延等TE属性。
- 控制器对收集到的拓扑信息进行分析,按照业务需求计算路径,符合业务的SLA。
- 控制器将路径信息下发给网络的头节点(PE1),头节点生成SRv6 TE Policy。其中包括头端地址、目的地址和Color(扩展团体属性)等关键信息。
- 网络的头节点(PE1)为业务选择合适的SRv6 TE Policy指导转发。转发时,各转发器按照SRv6报文中携带的信息,执行自己发布的SID指令。
SRv6 BE
SRv6 BE类似于MPLS网络中的LDP,是指基于IGP最短路径算法计算得到最优SRv6路径,仅使用一个业务SID来指引报文在链路中的转发,是一种尽力而为的工作模式。其没有流量工程能力,一般用于承载普通VPN业务,用于快速开通业务。
以L3VPNv4 over SRv6 BE为例,讲述SRv6 BE的业务实现。如图所示,网络中部署VPN,PE1和PE2部署SRv6,P部署IPv6。

路由发布阶段:
- PE2上配置Locator。
- PE2通过IGP协议将SRv6 SID对应的Locator网段路由2001:DB8:2::/64发布给PE1。PE1安装路由到自己的IPv6路由表。
- PE2在Locator范围内配置VPN实例的SID 2001:DB8:2::B100,生成Local SID表。
- PE2收到CE2发布的私网IPv4路由后,将私网IPv4路由转换成BGP VPNv4路由,通过BGP邻居关系发布给PE1。此路由携带SRv6 VPN SID属性,也就是VPN实例的SID 2001:DB8:2::B100。
- PE1接收到VPNv4路由后,将其交叉到对应的VPN实例路由表,然后转换成普通IPv4路由,对CE1发布。
数据转发阶段:
- CE1向PE1发送一个普通IPv4报文。
- PE1从绑定了VPN实例的接口上收到私网报文以后,查找对应VPN实例的路由转发表,匹配目的IPv4前缀,查找到关联的SRv6 VPN SID以及下一跳信息。然后直接使用SRv6 VPN SID 2001:DB8:2::B100作为目的地址封装成IPv6报文。
- PE1然后按照最长匹配原则,匹配到路由2001:DB8:2::/64,按最短路径转发到P设备。
- P设备按照最长匹配原则,匹配到路由2001:DB8:2::/64,按最短路径转发到PE2。
- PE2使用2001:DB8:2::B100查找Local SID表,匹配到SID对应的转发动作,将IPv6报文头去除,然后根据SID匹配VPN实例,查找VPN实例路由表进行转发。报文恢复成普通IPv4报文。
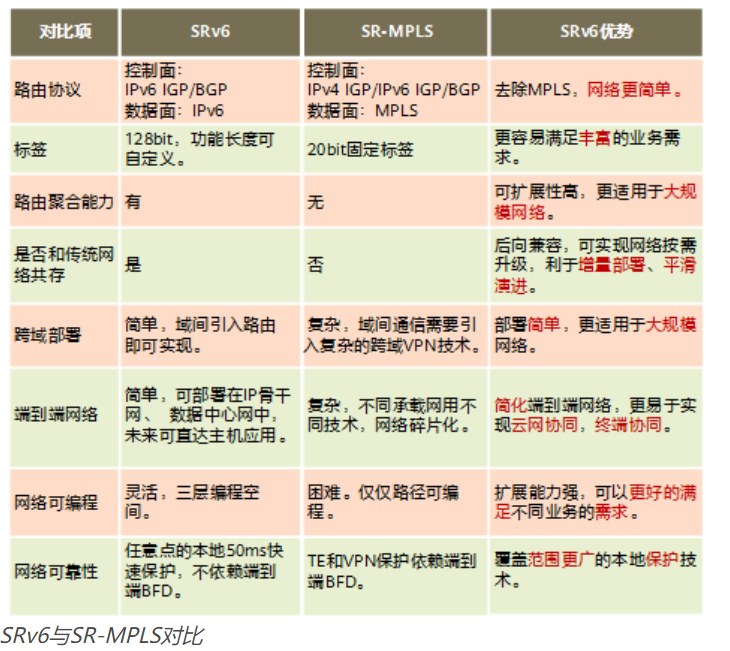
SRv6 vs SR-MPLS
SR技术支持MPLS和IPv6两种转发平面,基于MPLS转发平面的SR为SR-MPLS,基于IPv6转发平面的SR为SRv6。
为什么说SRv6是新一代IP承载协议呢?SRv6相比SR-MPLS有哪些优势呢?
这篇关于作为网工有必要了解一下什么是SRv6的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!