本文主要是介绍java第二十一天Lock锁 死锁现象 线程池 定时器 设计模式 设计原则,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 Lock 锁
A:Lock锁的概述
虽然我们可以理解同步代码块和同步方法的锁对象问题,
但是我们并没有直接看到在哪里加上了锁,在哪里释放了锁,
为了更清晰的表达如何加锁和释放锁,JDK5以后提供了一个新的锁对象Lock
B:Lock和ReentrantLock
void lock()
void unlock()
2 线程的状态转换图
新建 , 就绪 , 运行 , 冻结 , 死亡
新建:线程被创建出来
就绪:具有CPU的执行资格,但是不具有CPU的执行权
运行:具有CPU的执行资格,也具有CPU的执行权
阻塞:不具有CPU的执行资格,也不具有CPU的执行权
死亡:不具有CPU的执行资格,也不具有CPU的执行权


3 线程池
线程池概述
程序启动一个新线程成本是比较高的,因为它涉及到要与操作系统进行交互。
而使用线程池可以很好的提高性能,尤其是当程序中要创建大量生存期很短的线程时,更应该考虑使用线程池。
线程池里的每一个线程代码结束后,并不会死亡,而是再次回到线程池中成为空闲状态,等待下一个对象来使用。
在JDK5之前,我们必须手动实现自己的线程池,从JDK5开始,Java内置支持线程池
JDK5新增了一个Executors工厂类来产生线程池,有如下几个方法
public static ExecutorService newCachedThreadPool(): 根据任务的数量来创建线程对应的线程个数
public static ExecutorService newFixedThreadPool(int nThreads): 固定初始化几个线程
public static ExecutorService newSingleThreadExecutor(): 初始化一个线程的线程池
这些方法的返回值是ExecutorService对象,该对象表示一个线程池,可以执行Runnable对象或者Callable对象代表的线程。它提供了如下方法
Future<?> submit(Runnable task)
<T> Future<T> submit(Callable<T> task)
4 匿名内部类的方式实现多线程程序
new Thread(){代码…}.start();
new Thread(new Runnable(){代码…}).start();
5 定时器
B:Timer和TimerTask
Timer:
public Timer()
public void schedule(TimerTask task, long delay):
public void schedule(TimerTask task,long delay,long period);
public void schedule(TimerTask task, Date time):
public void schedule(TimerTask task, Date firstTime, long period):
TimerTask
public abstract void run()
public boolean cancel()
6 面试题
A:多线程有几种实现方案,分别是哪几种? 三种
B:同步有几种方式,分别是什么? 三种,一种同步代码块,一种同步方法,一种Lock锁
C:启动一个线程是run()还是start()?它们的区别? start(),如果run(),仅仅是对象调用方法,start()是让jvm调用run()
7 设计模式:
设计模式概述
设计模式(Design pattern)是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。
使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性以及代码的结构更加清晰.
单例模式(饿汉式)
class Student {private Student(){}private static Student student = new Student();public static Student getStudent(){return student;}}public class Demo1 {public static void main(String[] args) {Student s1 = Student.getStudent();Student s2 = Student.getStudent();System.out.println(s1==s2);}}单例模式(懒汉式(线程安全版本))
class Student {private Student(){}private static Student student = null;public synchronized static Student getStudent(){if (student == null) {student = new Student();}return student;}}public class Demo1 {public static void main(String[] args) {Student s1 = Student.getStudent();Student s2 = Student.getStudent();System.out.println(s1==s2);}}饿汉式与懒汉式详解
都是单例模式,即一个类中只允许有一个对象这里来进行一个比较,究竟饿汉式和懒汉式哪一个更好;饿汉式:简单来说就是空间换时间,因为上来就实例化一个对象,占用了内存,(也不管你用还是不用)懒汉式:简单的来说就是时间换空间,与饿汉式正好相反这时,会有人说,懒汉式比饿汉式更好,其实恰恰相反,这里举个例子!比如,现在有A线程和B线程,A线程刚好在这个getStudent()方法中,刚刚判断完非空(此时为null),即需要创建实例,然而,就是这么巧,B线程抢到了CPU的执行权,A线程sleep了,这时,B线程也进行了这个判断,和A一样,都需要创建实例,而这时,A也抢到了CPU,这时,B就sleep了,然后A执行了实例化后,B又抢到CPU执行权,然后B也实例化,这时,出现问题了,A和B都实例化了一个对象,这就是赤果果的两个对象呀,单例呢,唯一呢,全都没了。
--------------------- 1、线程安全:饿汉式天生就是线程安全的,可以直接用于多线程而不会出现问题,懒汉式本身是非线程安全的,为了实现线程安全有几种写法。最常见的是加synchronized关键字,2、资源加载和性能:饿汉式在类创建的同时就实例化一个静态对象出来,不管之后会不会使用这个单例,都会占据一定的内存,但是相应的,在第一次调用时速度也会更快,因为其资源已经初始化完成。而懒汉式顾名思义,会延迟加载,在第一次使用该单例的时候才会实例化对象出来,第一次调用时要做初始化,如果要做的工作比较多,性能上会有些延迟,之后就和饿汉式一样了。--------------------- 意图:保证一个类仅有一个实例,并提供一个访问它的全局访问点。主要解决:一个全局使用的类频繁地创建与销毁。何时使用:当您想控制实例数目,节省系统资源的时候。如何解决:判断系统是否已经有这个单例,如果有则返回,如果没有则创建。关键代码:构造函数是私有的。应用实例: 1、一个党只能有一个主席。 2、Windows 是多进程多线程的,在操作一个文件的时候,就不可避免地出现多个进程或线程同时操作一个文件的现象,所以所有文件的处理必须通过唯一的实例来进行。 3、一些设备管理器常常设计为单例模式,比如一个电脑有两台打印机,在输出的时候就要处理不能两台打印机打印同一个文件。优点: 1、在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如管理学院首页页面缓存)。 2、避免对资源的多重占用(比如写文件操作)。缺点:没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。使用场景: 1、要求生产唯一序列号。 2、WEB 中的计数器,不用每次刷新都在数据库里加一次,用单例先缓存起来。 3、创建的一个对象需要消耗的资源过多,比如 I/O 与数据库的连接等。注意事项:getStudent() 方法中需要使用同步锁 synchronized (Student.class) 防止多线程同时进入造成instance 被多次实例化
简单工厂模式(静态工厂)
1
public abstract class Animal {public abstract void eat();
}
2
public class Dog extends Animal {@Overridepublic void eat() {System.out.println("狗吃屎");}
}
3
public class Cat extends Animal {@Overridepublic void eat() {System.out.println("猫吃鱼");}
}4
public class AnimalFactory {public static Animal createAnimal(String s){if("Cat".equals(s)){return new Cat();}else if("Dog".equals(s)){return new Dog();}else{return null;}}
}5
public class Demo1 {public static void main(String[] args) {Animal cat = AnimalFactory.createAnimal("Cat");Animal dog = AnimalFactory.createAnimal("Dog");cat.eat();dog.eat();}}工厂方法模式
1
public abstract class Animal {public abstract void eat();
}
2
public class Dog extends Animal {@Overridepublic void eat() {System.out.println("狗吃屎");}
}
3
public class Cat extends Animal {@Overridepublic void eat() {System.out.println("猫吃鱼");}
}
4
public abstract interface BigAnimalFactory {public abstract Animal createAnimal();}5
public class CatFactory implements BigAnimalFactory {@Overridepublic Animal createAnimal() {return new Cat();}}
6
public class DogFactory implements BigAnimalFactory {@Overridepublic Animal createAnimal() {return new Dog();}
}7
public class Demo1 {public static void main(String[] args) {CatFactory catFactory = new CatFactory();Animal cat = catFactory.createAnimal();DogFactory dogFactory = new DogFactory();Animal dog = dogFactory.createAnimal();cat.eat();dog.eat();}}抽象工厂模式
//生产各种手机接口public interface PhoneProduct {public abstract void call();
}//生产各种pad接口
public interface IpadProduct {public abstract void play();
}//小米手机功能
public class xiaomiphone implements PhoneProduct {@Overridepublic void call() {System.out.println("用小米手机打电话");}
}//小米pad功能
public class xiaomiipad implements IpadProduct {@Overridepublic void play() {System.out.println("用小米pad玩");}
}//华为手机功能
public class huaweiphone implements PhoneProduct {@Overridepublic void call() {System.out.println("用华为手机打电话");}
}//华为pad功能
public class huaweiipad implements IpadProduct {@Overridepublic void play() {System.out.println("用华为pad玩");}
}--------------------------------------------------------准备//这是一个 抽象大工厂,既能生产手机,又能生产padpublic interface ProductFactory {public abstract PhoneProduct getPhone();public abstract IpadProduct getIpad();}//这是小米工厂,实现了这个大工厂,小米工厂既有手机又有pad
public class xiaomiFactory implements ProductFactory {@Overridepublic PhoneProduct getPhone() {return new xiaomiphone();}@Overridepublic IpadProduct getIpad() {return new xiaomiipad();}
}//这是华为工厂,实现了这个大工厂,华为工厂既有手机又有pad
public class huaweiFactory implements ProductFactory {@Overridepublic PhoneProduct getPhone() {return new huaweiphone();}@Overridepublic IpadProduct getIpad() {return new huaweiipad();}
}
---------------------------------------------------------工厂完毕
//测试类
public class Demo {public static void main(String[] args) {xiaomiFactory xiaomiFactory = new xiaomiFactory();PhoneProduct phone = xiaomiFactory.getPhone();phone.call();IpadProduct ipad = xiaomiFactory.getIpad();ipad.play();huaweiFactory huaweiFactory = new huaweiFactory();PhoneProduct phone1 = huaweiFactory.getPhone();phone1.call();IpadProduct ipad1 = huaweiFactory.getIpad();ipad1.play();}}
输出结果:用小米手机打电话
用小米pad玩
用华为手机打电话
用华为pad玩
简单工厂模式与工厂方法模式与抽象工厂模式详解
简单工厂中只有一个工厂,该工厂有一个创建产品的方法。根据传入参数不同,返回不同产品。举个例子:一个电视机工厂,根据客户的需要,生产海尔电视机,三星电视机。如果要新增一个产品,需要修改创建产品的方法。如果产品种类太多,代码会显得很笨重,不易维护。违背了开放-封闭原则。工厂方法模式是对简单工厂的升级,将工厂抽象出来,工厂基类定义创建产品的方法。每个工厂都需要实现该方法。每个产品对应一个工厂,一个工厂只生产对应产品。举个例子:只要是工厂都要能生产电视机。海尔工厂生产海尔电视机,三星工厂生产三星电视机。如果要新增一个产品,只需要新增对应的工厂和方法即可。遵循了开放-封闭原则。但是每新增一个产品都需要新增对应的工厂。抽象工厂模式是对工厂方法模式的升级。工厂基类除了定义创建电视机方法,还定义了创建微波炉的方法。举个例子:只要是工厂都要能生产电视机和微波炉。海尔工厂生产海尔电视机,海尔微波炉。三星工厂生产三星电视机,三星微波炉。如果要新增一个产品,也只需要新增对应的工厂和方法即可。这个层面上遵循了开放-封闭原则。但是如果需要对工厂基类进行扩展,实现生产冰箱的话。则需要对各个工厂都进行修改。三个设计模式各有利弊,需要根据场景进行使用。简单工厂用于生产少量的产品,等产品数量到了一定规模可以考虑使用工厂方法替代。工厂方法之后也可以升级为抽象工厂模式。适配器模式
适配器模式(Adapter Pattern):将一个接口转换成客户希望的另一个接口,使接口不兼容的那些类可以一起工作,其别名为包装器(Wrapper)。适配器模式既可以作为类结构型模式,也可以作为对象结构型模式。在适配器模式中,我们通过增加一个新的适配器类来解决接口不兼容的问题,使得原本没有任何关系的类可以协同工作。根据适配器类与适配者类的关系不同,适配器模式可分为对象适配器和类适配器两种,在对象适配器模式中,适配器与适配者之间是关联关系;在类适配器模式中,适配器与适配者之间是继承(或实现)关系。角色Target(目标抽象类):目标抽象类定义客户所需接口,可以是一个抽象类或接口,也可以是具体类。Adapter(适配器类):适配器可以调用另一个接口,作为一个转换器,对Adaptee和Target进行适配,适配器类是适配器模式的核心,在对象适配器中,它通过继承Target并关联一个Adaptee对象使二者产生联系。Adaptee(适配者类):适配者即被适配的角色,它定义了一个已经存在的接口,这个接口需要适配,适配者类一般是一个具体类,包含了客户希望使用的业务方法,在某些情况下可能没有适配者类的源代码。
---------------------
1 类适配器。首先有一个已存在的将被适配的类public class Adaptee {public void adapteeRequest() {System.out.println("被适配者的方法");}
}2 定义一个目标接口public interface Target {void request();
}3 怎么才可以在目标接口中的 request() 调用 Adaptee 的 adapteeRequest() 方法呢?如果直接实现 Target 是不行的public class ConcreteTarget implements Target {@Overridepublic void request() {System.out.println("concreteTarget目标方法");}
}4 如果通过一个适配器类,实现 Target 接口,同时继承了 Adaptee 类,然后在实现的 request() 方法中调用父类的 adapteeRequest() 即可实现
public class Adapter extends Adaptee implements Target{@Overridepublic void request() {//...一些操作...super.adapteeRequest();//...一些操作...}
}5 我们来测试一下
public class Test {public static void main(String[] args) {Target target = new ConcreteTarget();target.request();Target adapterTarget = new Adapter();adapterTarget.request();}
}
6 输出
concreteTarget目标方法
被适配者的方法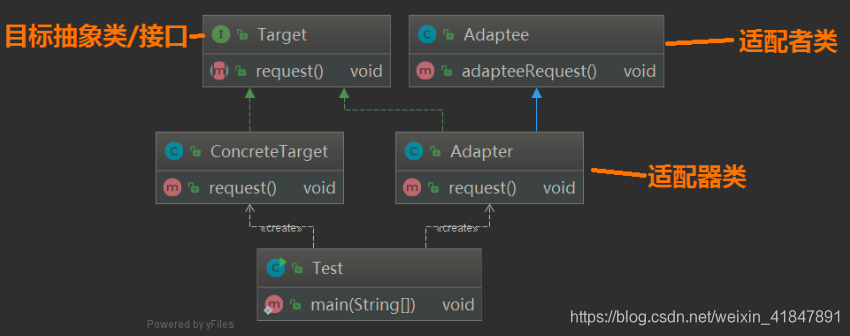
这样我们即可在新接口 Target 中适配旧的接口或类
对象适配器
对象适配器与类适配器不同之处在于,类适配器通过继承来完成适配,对象适配器则是通过关联来完成,这里稍微修改一下 Adapter 类即可将转变为对象适配器
public class Adapter implements Target{// 适配者是对象适配器的一个属性private Adaptee adaptee = new Adaptee();@Overridepublic void request() {//...adaptee.adapteeRequest();//...}
}
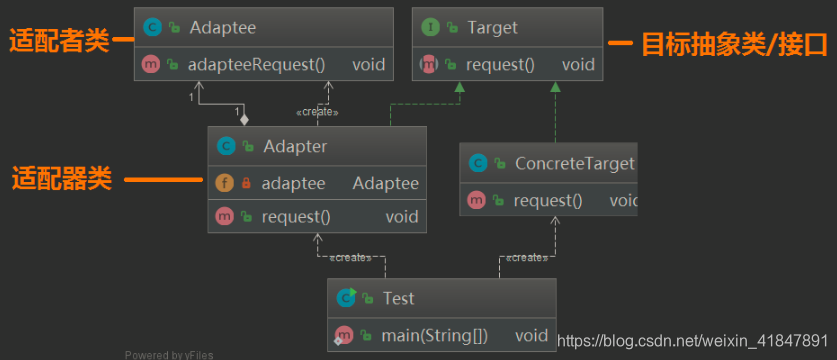
注意这里的 Adapter 是将 Adaptee 作为一个成员属性,而不是继承它
观察者模式
观察者模式:定义对象间一种一对多的依赖关系,使得每当一个对象改变状态,则所有依赖它的对象都会得到通知并自动更新
观察者模式又称为发布/订阅(Publish/Subscribe)模式
观察者设计模式涉及到两种角色:主题(Subject)和观察者(Observer)
1)Subject模块
Subjec模块有3个主要操作addObserver():注册添加观察者(申请订阅)
deleteObserver():删除观察者(取消订阅)
notifyObserver():主题状态发生变化时通知所有的观察者对象(2)Oserver模块 //相当于消息中间件
Oserver模块有1个核心操作update(),当主题Subject状态改变时,将调用每个观察者的update()方法,更新通知。被观察者Subject对象
public class Subject {//保存注册的观察者对象private List<Observer> mObervers = new ArrayList<>();//注册观察者对象public void attach(Observer observer) {mObervers.add(observer);Log.e("SZH", "attach an observer");}//注销观察者对象public void detach(Observer observer) {mObervers.remove(observer);Log.e("SZH", "detach an observer");}//通知所有注册的观察者对象public void notifyEveryOne(String newState) {for (Observer observer : mObervers) {observer.update(newState);}}
}
接着是一个具体的被观察者对象
public class ConcreteSubject extends Subject {private String state;public String getState() {return state;}public void change(String newState) {state = newState;Log.e("SZH", "concreteSubject state:" + newState);//状态发生改变,通知观察者notifyEveryOne(newState);}
}
观察者Observer对象 //相当于消息中间件
首先是一个接口,抽象出了一个及时更新的方法
public interface Observer {void update(String newState);
}接着是几个观察者对象
public class ObserverA implements Observer {//观察者状态private String observerState;@Overridepublic void update(String newState) {//更新观察者状态,让它与目标状态一致observerState = newState;Log.e("SZH", "接收到消息:" + newState + ";我是A模块,快来抢吧!!");}
}public class ObserverB implements Observer {//观察者状态private String observerState;@Overridepublic void update(String newState) {//更新观察者状态,让它与目标状态一致observerState = newState;Log.e("SZH", "接收到消息:" + newState + ";我是B模块,快来抢吧!!");}
}public class ObserverC implements Observer {//观察者状态private String observerState;@Overridepublic void update(String newState) {//更新观察者状态,让它与目标状态一致observerState = newState;Log.e("SZH", "接收到消息:" + newState + ";我是C模块,快来抢吧!!");}
}
8 注意





volatile

CSA算法

设计的七大原则
单一职责,里氏替换,迪米特法则,依赖倒转,接口隔离,合成/聚合原则,开放-封闭 。
1. 开闭原则(Open-Closed Principle, OCP)
定义:软件实体应当对扩展开放,对修改关闭。这句话说得有点专业,更通俗一点讲,也就是:软件系统中包含的各种组件,例如模块(Modules)、类(Classes)以及功能(Functions)等等,应该在不修改现有代码的基础上,去扩展新功能。开闭原则中原有“开”,是指对于组件功能的扩展是开放的,是允许对其进行功能扩展的;开闭原则中“闭”,是指对于代码的修改是封闭的,即不应该修改原有的代码。
问题由来:凡事的产生都有缘由。我们来看看,开闭原则的产生缘由。在软件的生命周期内,因为变化、升级和维护等原因需要对软件原有代码进行修改时,可能会给旧代码中引入错误,也可能会使我们不得不对整个功能进行重构,并且需要原有代码经过重新测试。这就对我们的整个系统的影响特别大,这也充分展现出了系统的耦合性如果太高,会大大的增加后期的扩展,维护。为了解决这个问题,故人们总结出了开闭原则。解决开闭原则的根本其实还是在解耦合。所以,我们面向对象的开发,我们最根本的任务就是解耦合。
解决方法:当软件需要变化时,尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来实现变化。
小结:开闭原则具有理想主义的色彩,说的很抽象,它是面向对象设计的终极目标。其他几条原则,则可以看做是开闭原则的实现。我们要用抽象构建框架,用实现扩展细节。
2. 单一职责原则(Single Responsibility Principle)
定义:一个类,只有一个引起它变化的原因。即:应该只有一个职责。
每一个职责都是变化的一个轴线,如果一个类有一个以上的职责,这些职责就耦合在了一起。这会导致脆弱的设计。当一个职责发生变化时,可能会影响其它的职责。另外,多个职责耦合在一起,会影响复用性。例如:要实现逻辑和界面的分离。需要说明的一点是单一职责原则不只是面向对象编程思想所特有的,只要是模块化的程序设计,都需要遵循这一重要原则。
问题由来:类T负责两个不同的职责:职责P1,职责P2。当由于职责P1需求发生改变而需要修改类T时,有可能会导致原本运行正常的职责P2功能发生故障。
解决方法:分别建立两个类T1、T2,使T1完成职责P1功能,T2完成职责P2功能。这样,当修改类T1时,不会使职责P2发生故障风险;同理,当修改T2时,也不会使职责P1发生故障风险。
3. 里氏替换原则(Liskov Substitution Principle)
定义:子类型必须能够替换掉它们的父类型。注意这里的能够两字。有人也戏称老鼠的儿子会打洞原则。
问题由来:有一功能P1,由类A完成。现需要将功能P1进行扩展,扩展后的功能为P,其中P由原有功能P1与新功能P2组成。新功能P由类A的子类B来完成,则子类B在完成新功能P2的同时,有可能会导致原有功能P1发生故障。
解决方法:类B继承类A时,除添加新的方法完成新增功能P2外,尽量不要重写父类A的方法,也尽量不要重载父类A的方法
小结:所有引用父类的地方必须能透明地使用其子类的对象。子类可以扩展父类的功能,但不能改变父类原有的功能,即:子类可以实现父类的抽象方法,子类也中可以增加自己特有的方法,但不能覆盖父类的非抽象方法。当子类的方法重载父类的方法时,方法的前置条件(即方法的形参)要比父类方法的输入参数更宽松。当子类的方法实现父类的抽象方法时,方法的后置条件(即方法的返回值)要比父类更严格。
4. 迪米特法则(Law Of Demeter)
定义:迪米特法则又叫最少知道原则,即:一个对象应该对其他对象保持最少的了解。如果两个类不必彼此直接通信,那么这两个类就不应当发生直接的相互作用。如果其中一个类需要调用另一个类的某一个方法的话,可以通过第三者转发这个调用。简单定义为只与直接的朋友通信。首先来解释一下什么是直接的朋友:每个对象都会与其他对象有耦合关系,只要两个对象之间有耦合关系,我们就说这两个对象之间是朋友关系。耦合的方式很多,依赖、关联、组合、聚合等。其中,我们称出现成员变量、方法参数、方法返回值中的类为直接的朋友,而出现在局部变量中的类则不是直接的朋友。也就是说,陌生的类最好不要作为局部变量的形式出现在类的内部。
问题由来:类与类之间的关系越密切,耦合度越大,当一个类发生改变时,对另一个类的影响也越大。
最早是在1987年由美国Northeastern University的Ian Holland提出。通俗的来讲,就是一个类对自己依赖的类知道的越少越好。也就是说,对于被依赖的类来说,无论逻辑多么复杂,都尽量地的将逻辑封装在类的内部,对外除了提供的public方法,不对外泄漏任何信息。迪米特法则还有一个更简单的定义:只与直接的朋友通信。
解决方法:尽量降低类与类之间的耦合。 自从我们接触编程开始,就知道了软件编程的总的原则:低耦合,高内聚。无论是面向过程编程还是面向对象编程,只有使各个模块之间的耦合尽量的低,才能提高代码的复用率。
迪米特法则的初衷是降低类之间的耦合,由于每个类都减少了不必要的依赖,因此的确可以降低耦合关系。但是凡事都有度,虽然可以避免与非直接的类通信,但是要通信,必然会通过一个“中介”来发生联系。故过分的使用迪米特原则,会产生大量这样的中介和传递类,导致系统复杂度变大。所以在采用迪米特法则时要反复权衡,既做到结构清晰,又要高内聚低耦合。
5. 依赖倒置原则(Dependence Inversion Principle)
定义:高层模块不应该依赖低层模块,二者都应该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象。中心思想是面向接口编程
问题由来:类A直接依赖类B,假如要将类A改为依赖类C,则必须通过修改类A的代码来达成。这种场景下,类A一般是高层模块,负责复杂的业务逻辑;类B和类C是低层模块,负责基本的原子操作;假如修改类A,会给程序带来不必要的风险。
解决方法:将类A修改为依赖接口I,类B和类C各自实现接口I,类A通过接口I间接与类B或者类C发生联系,则会大大降低修改类A的几率。
在实际编程中,我们一般需要做到如下3点:
1). 低层模块尽量都要有抽象类或接口,或者两者都有。
2). 变量的声明类型尽量是抽象类或接口。
3). 使用继承时遵循里氏替换原则。
采用依赖倒置原则尤其给多人合作开发带来了极大的便利,参与协作开发的人越多、项目越庞大,采用依赖导致原则的意义就越重大。
小结:依赖倒置原则就是要我们面向接口编程,理解了面向接口编程,也就理解了依赖倒置。
6. 接口隔离原则(Interface Segregation Principle)
定义:客户端不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上。
问题由来:类A通过接口I依赖类B,类C通过接口I依赖类D,如果接口I对于类A和类B来说不是最小接口,则类B和类D必须去实现他们不需要的方法
解决方法:1、 使用委托分离接口。2、 使用多重继承分离接口。3.将臃肿的接口I拆分为独立的几个接口,类A和类C分别与他们需要的接口建立依赖关系。也就是采用接口隔离原则。
举例说明:
下面我们来看张图,一切就一目了然了。
这个图的意思是:类A依赖接口I中的方法1、方法2、方法3,类B是对类A依赖的实现。类C依赖接口I中的方法1、方法4、方法5,类D是对类C依赖的实现。对于类B和类D来说,虽然他们都存在着用不到的方法(也就是图中红色字体标记的方法),但由于实现了接口I,所以也必须要实现这些用不到的方法
修改后:
如果接口过于臃肿,只要接口中出现的方法,不管对依赖于它的类有没有用处,实现类中都必须去实现这些方法,这显然不是好的设计。如果将这个设计修改为符合接口隔离原则,就必须对接口I进行拆分。在这里我们将原有的接口I拆分为三个接口
小结:我们在代码编写过程中,运用接口隔离原则,一定要适度,接口设计的过大或过小都不好。对接口进行细化可以提高程序设计灵活性是不挣的事实,但是如果过小,则会造成接口数量过多,使设计复杂化。所以一定要适度。设计接口的时候,只有多花些时间去思考和筹划,就能准确地实践这一原则。
7. 合成/聚合原则(Composite/Aggregate Reuse Principle,CARP)
定义:也有人叫做合成复用原则,及尽量使用合成/聚合,尽量不要使用类继承。换句话说,就是能用合成/聚合的地方,绝不用继承。
为什么要尽量使用合成/聚合而不使用类继承?
1. 对象的继承关系在编译时就定义好了,所以无法在运行时改变从父类继承的子类的实现
2. 子类的实现和它的父类有非常紧密的依赖关系,以至于父类实现中的任何变化必然会导致子类发生变化
3. 当你复用子类的时候,如果继承下来的实现不适合解决新的问题,则父类必须重写或者被其它更适合的类所替换,这种依赖关系限制了灵活性,并最终限制了复用性。
总结:这些原则在设计模式中体现的淋淋尽致,设计模式就是实现了这些原则,从而达到了代码复用、增强了系统的扩展性。所以设计模式被很多人奉为经典。我们可以通过好好的研究设计模式,来慢慢的体会这些设计原则。
这篇关于java第二十一天Lock锁 死锁现象 线程池 定时器 设计模式 设计原则的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





