本文主要是介绍JVM垃圾收集器-serial.parNew,parallelScavnge,serialOld,parallelOld,CMS,G1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
垃圾收集器
分代模型
适用于新生代:
serial
parNew
parallel Scaavenge
适用于老年代:
CMS
serial Old(msc)
paraller Old
分区模型
适用于超大容量:
G1

分代模型
serial /serial Old收集器
1.单线程收集器
2.收集时会暂停其他线程(用户体验不好)
3.新生代是复制算法,老年代是标记整理算法
4.参数配置
-XX: +UseSerialGC #新生代使用serial收集器
-XX: +UseSerialOldGC #老年代使用serial收集器
优点:
1.简单高效,无其他线程的开销
2.对于多核cpu,依旧采用单线程,浪费cpu资源

parNew 收集器
1.serial 收集器的多线程版本
2.线程数与cpu 核数相关
3.参数设置
-XX: +UseParNewGC
4.搭配CMS收集器使用

parallel Scavenge/parallelOld 收集器
1.关注的是吞吐量,使更高效的利用CPU,
3.参数配置
-XX +UseParallelGC
-XX +UseParallelOldGC

CMS收集器(重点)(低停顿)(标记清除算法)
1.采用标记清除算法
2.只能使用在老年代
3.尽量减少停顿时间(低停顿)
垃圾清理过程:
1.初始标记:该阶段会暂停其他线程,标记初与GCroot 根 直接 关联的对象,其余可达对象不会被标记
2.并发标记:标记出GCroot 根所有的可达对象(耗时长,占整个收集的80%时间,但是和用户线程一起执行)
3.重新标记:该阶段会暂停其他线程,将 并发标记时 新产生的对象进行标记
4.并发清理:将对象进行清除
缺点:
1.并发标记和并发清除时,会和用户线程抢夺cpu资源
2.在并发清理时:会有用户线程产生新的垃圾,这些垃圾不会被回收
3.采用 标记清除算法,会产生不连续的碎片(补救办法:通过参数-XX +UseCMSCompactAtFullCollection 设置清除完后进行整理)
4.时间不确定性,在一次没收集完后,直接进入下一次收集,导致收集失败,(补救办法:使用serial Old收集器,但会产生停顿)
参数配置
设置线程数,设置是否做整理以及fullGC多少次后做整理,设置fullGC之前是否再来一次minorGC来减少标记时开销
-XX: +UseConcMarkSweepGC #使用收集器
-XX: ConcGCThreads #并发GC线程数
-XX: +UseCMSCompactAtFullCollection # FUllGC后是否做整理
-XX: CMSFullGCsBeroreCompaction # 多少次FUllGC后做整理,默认是0,代表每次都做整理
-XX: CMSInitatingOccupancyFraction #设置老年代的使用到多少时,会触发FullGC
-XX:+UseCMSInitatingOccupancyOnly #设置回收阀值,不指定的话,除了第一次外,之后jvm会自动调整
-XX: +CMSSvacavengeBeroreRemark #在FullGC之前,进行minorGC 目的是通过减少对象引用,减少标记阶段的开销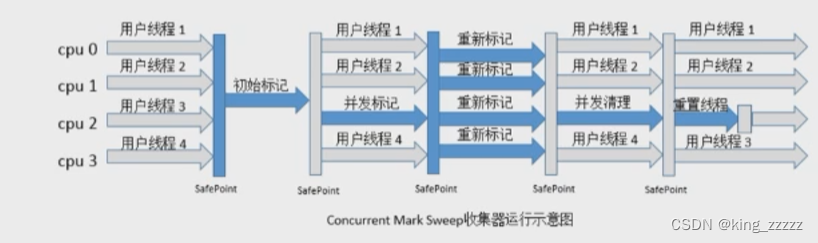
分区模型
G1收集器(面向大容量)(筛选回收)(复制算法)
大容量:指的是给堆内存分配十几个G以上
1.将堆区分成多个区(最多可以有2048个区,每个区的大小是堆内存/2048),且每个区可以是任意年轻代,老年代。
2.年轻代默认占比是整个堆区的5%(可以通过参数配置,但不能超过60%)
3.Humongous 区:大对象区,将超过一个区的50%,就会直接放到大对象区,大对象区在FullGC的时候进行回收
优点:避免大对象进入老年代,占用老年代的空间而触发FullGC。
垃圾收集过程:
1.初始标记:标记GCroot根直接关联的对象
2.并发标记:标记GCroot根可达到的所有对象
3.最终标记:将有变动的对象进行再次标记
4.筛选回收:通过设置回收时间-XX : MaxGCPauseMillis #指定回收时间 ,默认200ms,堆区的回收价值和成本进行排序,然后在设定的时间内回收
5.复制算法:将每个区存活对象,复制到空白区。
收集器分类:
1.youngGC
当Eden区满了后,计算回收当前Eden区需要多长时间,然后与设置的回收时间比较 -XX : MaxGCPauseMillis 若是远远小于,则对新生代进行扩容(增加区),若接近,则进行youngGC
2.mixedGC
老年代占用整个堆区的设定的值-XX:InitiatingHeapOccupancyPrencet 的值,会进行mixedGC,进行时会将部分年轻代,部分老年代,部分大对象区进行回收
3.FullGC
对象在复制的时候,空白的区放不下存活的对象,就会触发FullGC,采用单线程回收,标记清除,整理对象,会停止用户线程

ZGC收集器
JDK11 推出的低延迟收集器 (10ms)
堆区的划分
将堆区分为小页面,中页面,大页面
Small Region:2MB,主要用于放置小于 256 KB 的小对象。
Medium Region:32MB,主要用于放置大于等于 256 KB 小于 4 MB 的对象。
Large Region:N * 2MB。这个类型的 Region 是可以动态变化的,不过必须是 2MB 的整数倍,最小支持 4 MB。每个 Large Region 只放置一个大对象,并且是不会被重分配的。

安全点
JVM进行检查,业务线程没有对象的创建和引用的改变,就可以进行STW
判断垃圾的方式
传统垃圾收集器,使用可达性分析,GC 信息保存在对象头的 Mark Word 中,回收时需要进行对象遍历,查看对象头
ZGC:着色指针
着色指针
在 64 位的指针上,高 16 位都是 0,暂时不用来寻址。剩下的 48 位支持的内存可以达到 256 TB(2 ^48),这可以满足多数大型服务器的需要了。不过 ZGC 并没有把 48 位都用来保存对象信息,而是用高 4 位保存了四个标志位,这样 ZGC 可以管理的最大内存可以达到 16 TB(2 ^ 44)
JVM 可以从指针上直接看到对象的三色标记状态(Marked0、Marked1)、是否进入了重分配集(Remapped)、是否需要通过 finalize 方法来访问到(Finalizable)

标记垃圾的方式:着色指针

GC过程
1.初始标记
将GCroots 根直接关联的对象进行标记(会进行STW)
2.并发标记
3.再标记
4.并发转移准备
5.初始转移
6.并发转移

这篇关于JVM垃圾收集器-serial.parNew,parallelScavnge,serialOld,parallelOld,CMS,G1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





