本文主要是介绍闭包表(Closure Table)存储和查询树形数据结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
闭包表通过在关系表中记录树节点之间的直接和间接关系来表示节点之间的层次结构,目的是支持高效的树遍历和查询操作。
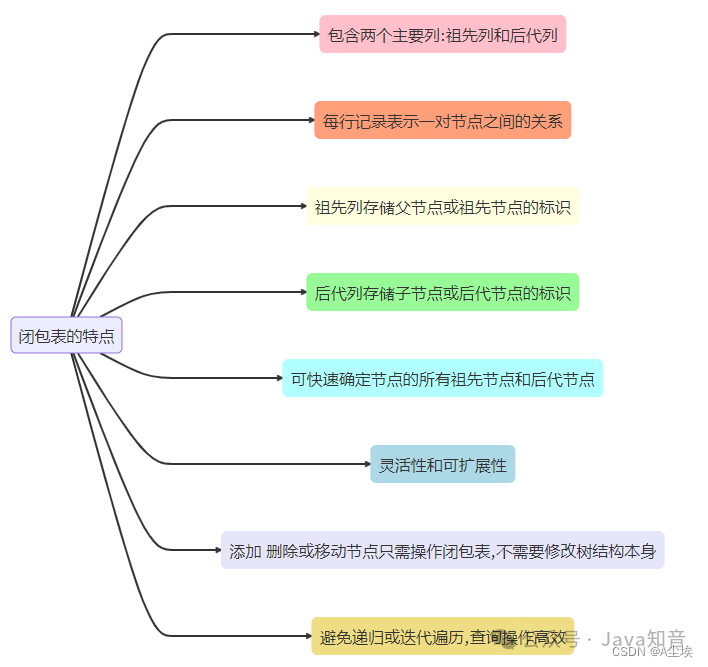
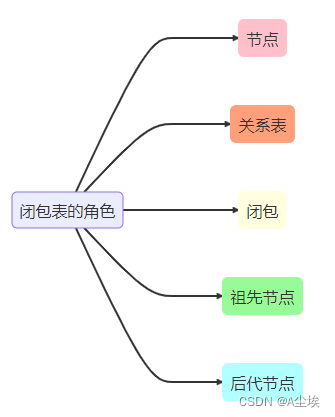
一、创建闭包表
CREATE TABLE `departments` (`id` int NOT NULL COMMENT 'ID',`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '部门名称',`parent_id` int DEFAULT NULL COMMENT '父ID',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='部门表';
CREATE TABLE `departments_closure_table` (`ancestor` int NOT NULL COMMENT '祖先节点',`descendant` int NOT NULL COMMENT '后代节点',PRIMARY KEY (`ancestor`,`descendant`),KEY `fk_descendant` (`descendant`),CONSTRAINT `fk_ancestor` FOREIGN KEY (`ancestor`) REFERENCES `departments` (`id`) ON DELETE RESTRICT ON UPDATE RESTRICT,CONSTRAINT `fk_descendant` FOREIGN KEY (`descendant`) REFERENCES `departments` (`id`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='部门信息闭包表';
初始化部门表
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (1, '集团总部', NULL);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (2, '华北总部', 1);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (3, '华南总部', 1);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (4, '华东总部', 1);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (5, '华中总部', 1);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (6, '华西总部', 1);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (7, '北京子公司', 2);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (8, '天津子公司', 2);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (9, '河北子公司', 2);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (10, '广东子公司', 3);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (11, '广西子公司', 3);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (12, '海南子公司', 3);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (13, '四川子公司', 6);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (14, '重庆子公司', 6);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (15, '贵州子公司', 6);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (16, '云南子公司', 6);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (17, '成都办事处', 13);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (18, '广元办事处', 13);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (19, '雅安办事处', 13);
INSERT INTO `hytto_cs`.`departments`(`id`, `name`, `parent_id`) VALUES (20, '绵阳办事处', 13);
初始化闭包表
-- 初始化自身关系
INSERT INTO departments_closure_table (ancestor, descendant, depth)
SELECT id, id, 0
FROM departments;-- 初始化父子关系
INSERT INTO departments_closure_table (ancestor, descendant, depth)
SELECT ct.ancestor, d.id, ct.depth + 1
FROM departments_closure_table AS ct
JOIN departments AS d ON ct.descendant = d.parent_id
where ct.depth + 1 = 1;-- 初始化爷孙关系
INSERT INTO departments_closure_table (ancestor, descendant, depth)
SELECT ct.ancestor, d.id, ct.depth + 1
FROM departments_closure_table AS ct
JOIN departments AS d ON ct.descendant = d.parent_id
where ct.depth + 1 = 2;-- 初始化四代关系
INSERT INTO departments_closure_table (ancestor, descendant, depth)
SELECT ct.ancestor, d.id, ct.depth + 1
FROM departments_closure_table AS ct
JOIN departments AS d ON ct.descendant = d.parent_id
where ct.depth + 1 = 3;
或者如下初始化:
INSERT INTO departments_closure_table (ancestor, descendant, depth)
WITH RECURSIVE cte AS (SELECT id as ancestor, id as descendant, 0 as depthFROM departmentsUNION ALLSELECT cte.ancestor, departments.id, cte.depth + 1FROM cteJOIN departments ON cte.descendant = departments.parent_id
)
SELECT ancestor, descendant, depth
FROM cte
WHERE ancestor != descendant;
二、闭包表的查询
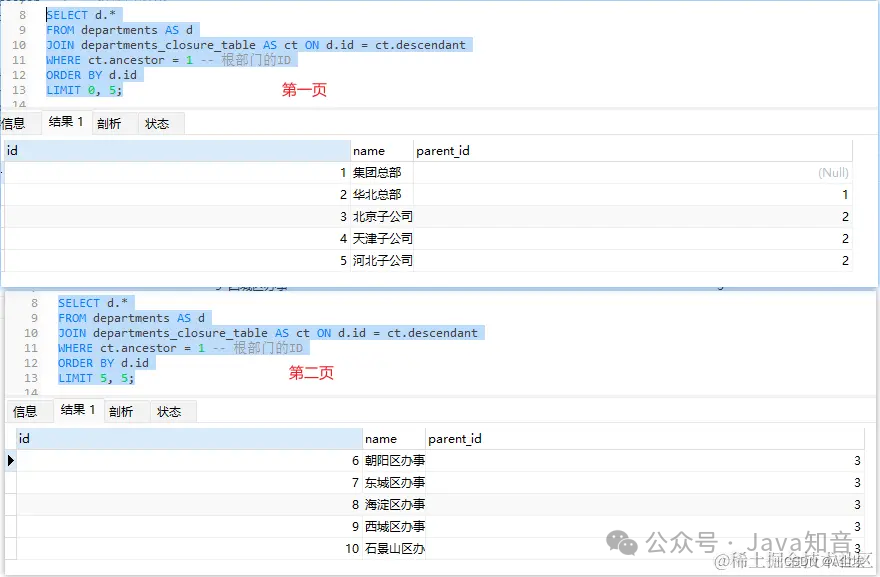
①、闭包表来进行树形结构的分页查询。假设我们想要按照部门ID升序进行分页查询,每页显示5个部门
SELECT d.*
FROM departments AS d
JOIN departments_closure_table AS ct ON d.id = ct.descendant
WHERE ct.ancestor = 1 -- 根部门的ID
ORDER BY d.id
LIMIT 0, 5;
三、闭包表的更新
①、清空现有闭包表
DELETE FROM departments_closure_table;
②、使用递归重新生成闭包表数据并插入到departments_closure_table表中:
INSERT INTO departments_closure_table (ancestor, descendant, depth)
WITH RECURSIVE cte AS (SELECT id, id, 0FROM departmentsUNION ALLSELECT cte.ancestor, departments.id, cte.depth + 1FROM cteJOIN departments ON cte.descendant = departments.parent_id
)
SELECT ancestor, descendant, depth
FROM cte
WHERE ancestor != descendant;
这篇关于闭包表(Closure Table)存储和查询树形数据结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







