本文主要是介绍【图像超分】论文复现:Pytorch实现FSRCNN,包含详细实验流程和与SRCNN的比较,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 1. FSRCNN网络结构
- 2. 训练FSRCNN
- 3. FSRCNN模型测试
- 4. 训练好的FSRCNN模型超分自己的图像
前言
论文地址:Accelerating the Super-Resolution Convolutional Neural Network
论文精读:
请配合上述论文精读文章使用,效果更佳!
代码地址:
不想理解原理,希望直接跑通然后应用到自己的图像数据的同学,请直接下载上面的代码,有训练好的模型,直接用即可。具体使用方式见代码中的README!有问题来本文评论区留言!
深度学习的模型训练一般遵循以下步骤:
- 准备数据集,以及数据预处理
- 搭建网络模型
- 设置参数并训练
- 测试训练好的模型
- 用训练好的模型测试自己的数据
硬件环境:windows11+RTX 2060(比这个高肯定没问题,我这个配置本机跑500个epoch一点问题没有,一会就跑完。但超分自己的图像时,如果图像很大,可能有内存溢出的错误)
运行环境:jupyter notebook/pycharm(前者好处是分代码段运行,测试方法,适合学习用;后者适合跑完整项目用)
pytorch环境:torch1.9.1+cuda11.1(其他版本没测试过,应该问题不大)
本文是在SRCNN的基础上进一步实现的,如果没看过前面SRCNN的复现文章,请先阅读那篇文章。
数据预处理与SRCNN完全相同,本文从搭建网络模型开始。
1. FSRCNN网络结构
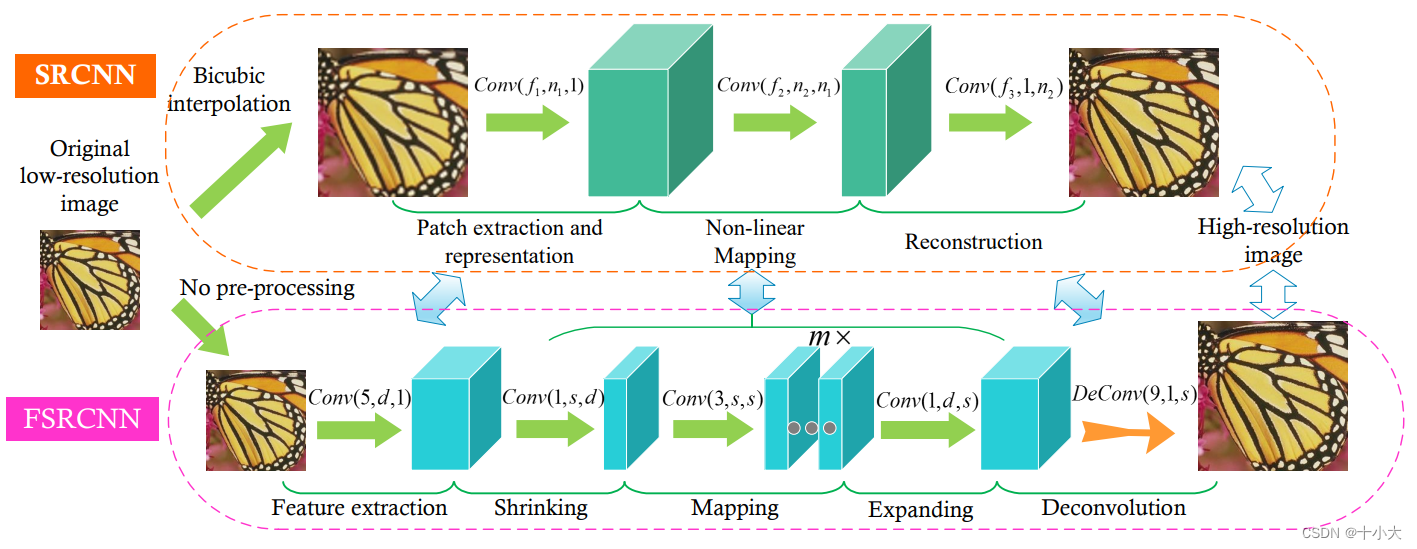
简单回顾一下FSRCNN的改进:
- 取消双三次插值,直接以低分辨率输入
- 网络最后一层为反卷积层
- SRCNN的非线性映射层改进为沙漏型的收缩、映射、扩展层
- 激活函数由ReLU变成了PReLU
- 与SRCNN相比,卷积核大小变小,但网络结构变深
- 输入和输出的图大小可以不同
网络的整体结构为:Conv(5, d, 1)−PReLU −Conv(1, s, d)−PReLU −m×Conv(3, s, s)−PReLU − Conv(1, d, s) − PReLU − DeConv(9, 1, d)
我们使用论文中4.4提到的默认网络FSRCNN (56,12,4)来实验。
网络结构的定义如下:
class FSRCNN(nn.Module):def __init__(self, scale_factor, num_channels=1, d=56, s=12, m=4):super(FSRCNN, self).__init__()# 特征提取部分self.first_part = nn.Sequential(nn.Conv2d(num_channels, d, kernel_size=5, padding=5//2),nn.PReLU(d))# 收缩层self.mid_part = [nn.Conv2d(d, s, kernel_size=1), nn.PReLU(s)]# m个映射层for _ in range(m):self.mid_part.extend([nn.Conv2d(s, s, kernel_size=3, padding=3//2), nn.PReLU(s)])# 扩展层self.mid_part.extend([nn.Conv2d(s, d, kernel_size=1), nn.PReLU(d)])# 上面三个层构成中间层self.mid_part = nn.Sequential(*self.mid_part)# 反卷积nn.ConvTranspose2d,输入输出与特征提取层相同,output_padding防止输入输入图像大小不匹配self.last_part = nn.ConvTranspose2d(d, num_channels, kernel_size=9, stride=scale_factor, padding=9//2,output_padding=scale_factor-1)self._initialize_weights()# 初始权重都是均值为0标准差为0.001的高斯分布def _initialize_weights(self):for m in self.first_part:if isinstance(m, nn.Conv2d):nn.init.normal_(m.weight.data, mean=0.0, std=math.sqrt(2/(m.out_channels*m.weight.data[0][0].numel())))nn.init.zeros_(m.bias.data)for m in self.mid_part:if isinstance(m, nn.Conv2d):nn.init.normal_(m.weight.data, mean=0.0, std=math.sqrt(2/(m.out_channels*m.weight.data[0][0].numel())))nn.init.zeros_(m.bias.data)nn.init.normal_(self.last_part.weight.data, mean=0.0, std=0.001)nn.init.zeros_(self.last_part.bias.data)def forward(self, x):x = self.first_part(x)x = self.mid_part(x)x = self.last_part(x)return x
2. 训练FSRCNN
根据论文4.1部分训练策略章节:卷积层的学习率是0.001,反卷积层的学习率是0.0001。
参照之前文章中的SRCNN训练,我们实现了FSRCNN的训练:
model = FSRCNN(1).to(device)
criterion = nn.MSELoss()
# optimizer = optim.Adam(model.parameters(), lr=1e-2)
optimizer = optim.Adam( [{"params": model.first_part.parameters(), "lr": 0.001},{"params": model.mid_part.parameters(), "lr": 0.001},{"params": model.last_part.parameters(), "lr": 0.0001},]
)
#scheduler = MultiStepLR(optimizer, milestones=[50, 75, 100], gamma=0.1) # 学习率调度器,在epoch在50,75,100时降低学习率
best_psnr = 0.0
each_psnr = []
for epoch in range(nb_epochs):# Trainepoch_loss = 0for iteration, batch in enumerate(trainloader):input, target = batch[0].to(device), batch[1].to(device)optimizer.zero_grad()out = model(input)loss = criterion(out, target)loss.backward()optimizer.step()epoch_loss += loss.item()print(f"Epoch {epoch}. Training loss: {epoch_loss / len(trainloader)}")# Valsum_psnr = 0.0sum_ssim = 0.0with torch.no_grad():for batch in valloader:input, target = batch[0].to(device), batch[1].to(device)out = model(input)loss = criterion(out, target)pr = psnr(loss)sm = ssim(input, out)sum_psnr += prsum_ssim += smprint(f"Average PSNR: {sum_psnr / len(valloader)} dB.")print(f"Average SSIM: {sum_ssim / len(valloader)} ")avg_psnr = sum_psnr / len(valloader)each_psnr.append(avg_psnr)if avg_psnr >= best_psnr:best_psnr = avg_psnrtorch.save(model, r"best_model_FSRCNN_2.pth")#scheduler.step()
数据的相关参数设置与SRCNN相同,放大倍数为2。训练500个epoch,PSNR稳定在28.43,SSIM稳定在0.9268。
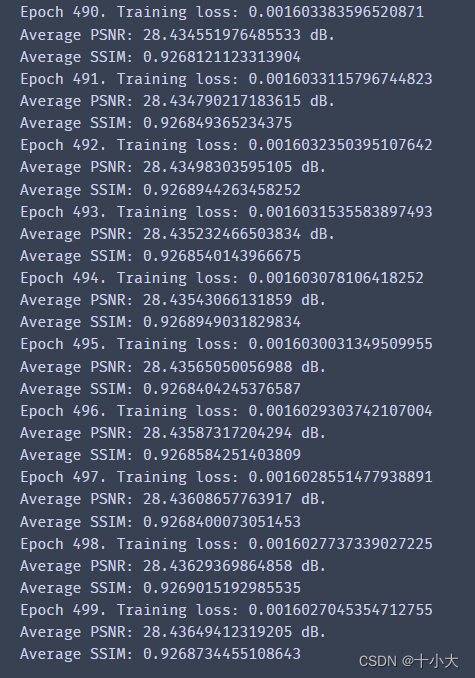
可视化epoch与PSNR的关系:
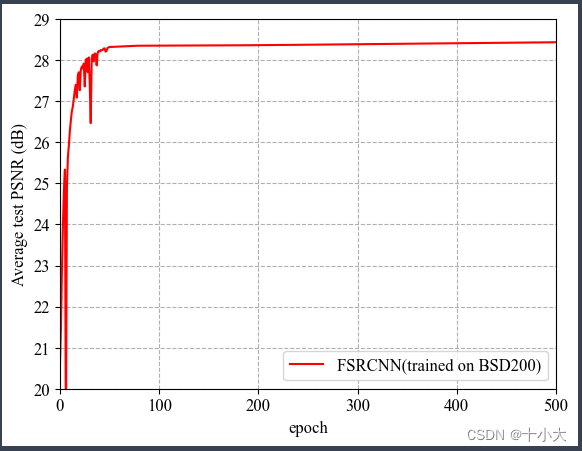
有波动和梯度骤降是因为我设置了学习率调度器,取消学习率调度器后为平滑曲线。对于BSD200数据集来说,训练100个epoch的PSNR基本保持稳定,没必要训练500个epoch。
可视化的代码如下,与SRCNN中的画图代码基本一致:
epochs = range(0,nb_epochs)# plot画图,设置颜色和图例,legend设置图例样式,右下,字体大小
plt.plot(epochs,each_psnr,color='red',label='FSRCNN(trained on BSD200)')
plt.legend(loc = 'lower right',prop={'family' : 'Times New Roman', 'size' : 12})# 横纵轴文字内容以及字体样式
plt.xlabel("epoch",fontproperties='Times New Roman',size = 12)
plt.ylabel("Average test PSNR (dB)",fontproperties='Times New Roman',size=12)# 横纵轴刻度以及字体样式
plt.xlim(0,nb_epochs)
plt.ylim(20,29)
plt.yticks(fontproperties='Times New Roman', size=12)
plt.xticks(fontproperties='Times New Roman', size=12)# 网格样式
plt.grid(ls = '--')plt.show()
3. FSRCNN模型测试
测试代码如下:
BATCH_SIZE = 4
model_path = "best_model_FSRCNN_2.pth"
testset = DatasetFromFolder(r"./data/images/test", zoom_factor)
testloader = DataLoader(dataset=testset, batch_size=BATCH_SIZE,shuffle=False, num_workers=NUM_WORKERS)
sum_psnr = 0.0
sum_ssim = 0.0
model = torch.load(model_path).to(device)
criterion = nn.MSELoss()
with torch.no_grad():for batch in testloader:input, target = batch[0].to(device), batch[1].to(device)out = model(input)loss = criterion(out, target)pr = psnr(loss)sm = ssim(input, out)sum_psnr += prsum_ssim += sm
print(f"Test Average PSNR: {sum_psnr / len(testloader)} dB")
print(f"Test Average SSIM: {sum_ssim / len(testloader)} ")
结果为:

在相同数据集上测试,FSRCNN的PSNR高于SRCNN,但是SSIM更低。
4. 训练好的FSRCNN模型超分自己的图像
代码如下:
# 参数设置
zoom_factor = 1
model = "best_model_FSRCNN_2.pth"
image = "./SEM_image_test/6.jpg"
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 读取图片
img = Image.open(image).convert('YCbCr') # PIL类型,转成YCbCr
img = img.resize((int(img.size[0] * zoom_factor), int(img.size[1] * zoom_factor)), Image.BICUBIC) # 双三次插值放大
y, cb, cr = img.split() # 划分Y,cb,cr三个通道
img_to_tensor = transforms.ToTensor() # 获得一个ToTensor对象# view中-1的含义是该维度不明,让其自动计算, input是由torch.Tensor([1,h,w])变成torch.Tensor([1,1,h,w])
# 图像Tensor格式:(batch_size, channel, h, w)
input = img_to_tensor(y).view(1, -1, y.size[1], y.size[0]).to(device) # 将y通道变换成网络输入的tensor格式# 输出图片
model = torch.load(model).to(device) # 载入模型
out = model(input).cpu() # 模型输出
out_img_y = out[0].detach().numpy() # 返回新的三维张量并转成numpy
out_img_y *= 255.0
out_img_y = out_img_y.clip(0, 255) # 取0-255内的值
out_img_y = Image.fromarray(np.uint8(out_img_y[0]), mode='L') # numpy转成PIL
out_img = Image.merge('YCbCr', [out_img_y, cb, cr]).convert('RGB') # 合并三个通道变成RGB格式# 绘图显示,上面的操作都是为了plt显示图像
fig, ax = plt.subplots(1, 2, figsize=(22, 10))
ax[0].imshow(img)
ax[0].set_title("原图")
ax[1].imshow(out_img)
ax[1].set_title("FSRCNN恢复结果")# 改dpi大小得到保存的图像清晰度,越大图片文件越大,质量越高;有的办法是保存成pdf,pdf放大不失真
plt.savefig(r"./SEM_image_test/6_FSRCNN_x1_result.png",dpi=1000,bbox_inches = 'tight')
plt.show()

视觉上感觉跟SRCNN差不多。
从指标上来看,用与SRCNN中提到的根据图像上每个像素计算PSNR和SSIM,结果为:
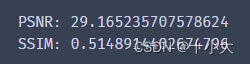
PSNR基本相同,但是SSIM降低很多。对于超分后的图像,经过FSRCNN的结构变化要比经过SRCNN大。即FSRCNN的性能更显著。
除此之外,通过对模型文件的大小观察,FSRCNN明显更小,但性能更好,也与论文相符。

后续将用91images数据集和其他数据集来测试模型,重点还是在于入门深度学习流程。
如果本文对你有所帮助,点个赞吧!
这篇关于【图像超分】论文复现:Pytorch实现FSRCNN,包含详细实验流程和与SRCNN的比较的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







