本文主要是介绍论文阅读:FCB-SwinV2 Transformer for Polyp Segmentation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是对FCBFormer的改进,我的关于FCBFormer的论文阅读笔记:论文阅读FCN-Transformer Feature Fusion for PolypSegmentation-CSDN博客
1,整体结构
依然是一个双分支结构,总体结构如下:
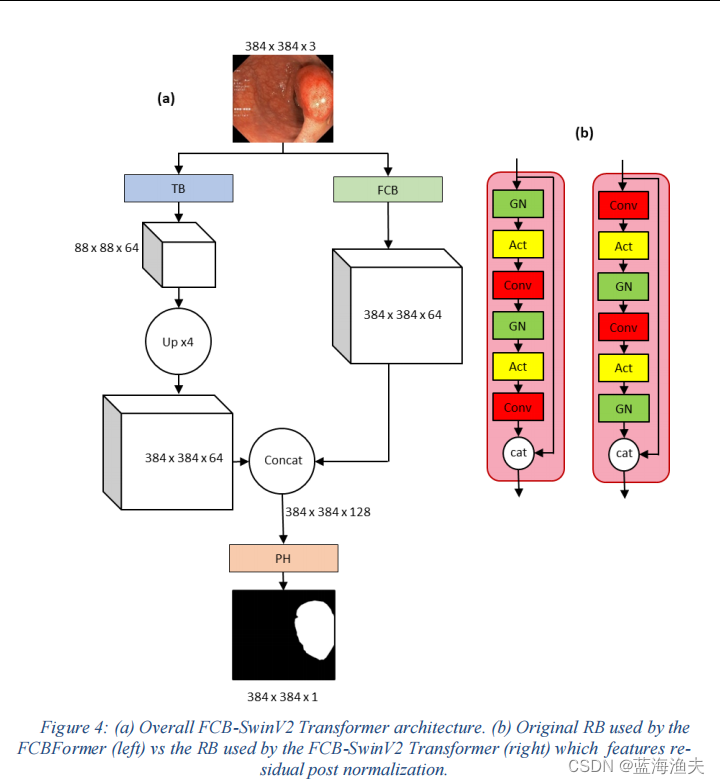
其中一个是全卷积分支,一个是Transformer分支。
和FCBFormer不同的是,对两个分支都做了一些修改。
2,FCB分支
本文没有画FCB分支的整体结构,我们借用一下FCBFormer的结构图看一下:
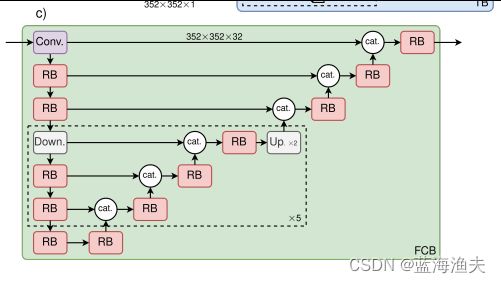
相比FCBFormer,FCB-SwinV2 Transformer模型中的FCB分支进行了以下主要改进:
1)通道维度增加:FCB分支的通道维度被增加,以匹配从SwinV2 Transformer-UNET分支输出的通道维度数量。这样做是为了确保两个分支的输出可以在合并之前具有相同的维度,从而更有效地结合两种架构的优势。
2)组归一化顺序调整:在FCB分支的残差块(RB)中,组归一化(GN)的顺序被调整,以适应SwinV2 Transformer中的残差后归一化(residual post normalization)方法。RB模块的调整如下:
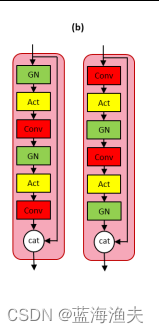
左边为原来的RB模块,右边是本文用的RB模块。主要是把先归一化再卷积,调整为先卷积再做归一化。
3)残差块改进:残差块的设计受到了SwinV2 Transformer中残差后归一化方法的启发。在FCB-SwinV2 Transformer中,残差块的归一化步骤被放置在卷积层之后,这与原始FCBFormer中的顺序不同。
3,TB分支
TB模块采用了SwinV2 Transformer作为其核心,SwinV2 Transformer通过引入“残差后归一化”(residual post normalization)和修改注意力机制来优化原始的Swin Transformer。
解码器模块(scse)如下:
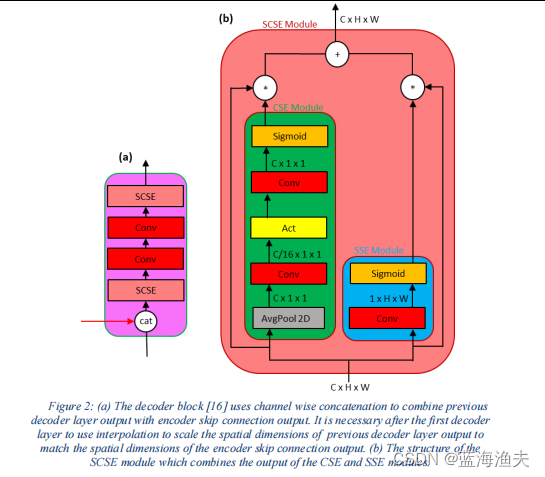
scse模块由cse和sse两个子模块构成。
1)CSE(Channel Squeeze and Excitation)模块是一种注意力机制,它通过显式地建模通道间的依赖关系来增强网络的特征表示能力。
CSE整体结构:
输入特征图: F
1. 通道全局平均池化: G = Global_Average_Pooling(F)
2. 卷积和激活: H = Activation(Conv(G))
3. 逐元素乘法: Output = H * F2)SSE(Spatial Squeeze and Excitation)模块是一种用于增强特征图中空间特征的注意力机制。
SSE整体结构:
输入特征图: F
1. 通道压缩: G = Conv(F) # 使用1x1卷积核
2. 空间激励: H = Activation(G)
3. 逐元素乘法: Output = H * F把编码器和解码器按照UNET的结构组合起来就是TB分支。
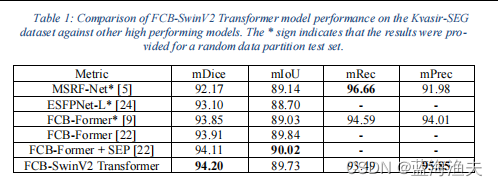
4,实验结果:
这篇关于论文阅读:FCB-SwinV2 Transformer for Polyp Segmentation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)