本文主要是介绍算法刷题Day6 | 242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1. 两数之和,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 0 哈希表 哈希函数
- 1 有效的字母异位词
- 1.1 string的回顾
- 1.2 我的代码
- 2 两个数组的交集
- 2.1 unordered_set 介绍
- 2.2 我的解题(set)
- 3 快乐数
- 3.1 我的解题(set)
- 4 两数之和
- 4.1 暴力求解
- 4.2 map的使用
- 4.3 哈希表(map)

- 🙋♂️ 作者:海码007
- 📜 专栏:算法专栏
- 💥 标题:算法刷题Day6 | 242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1. 两数之和
- ❣️ 寄语:书到用时方恨少,事非经过不知难!
0 哈希表 哈希函数
- 🎈 文档讲解:代码随想录
- 🎈 视频讲解:b站视频
下面是我对这两个概念的一些理解:
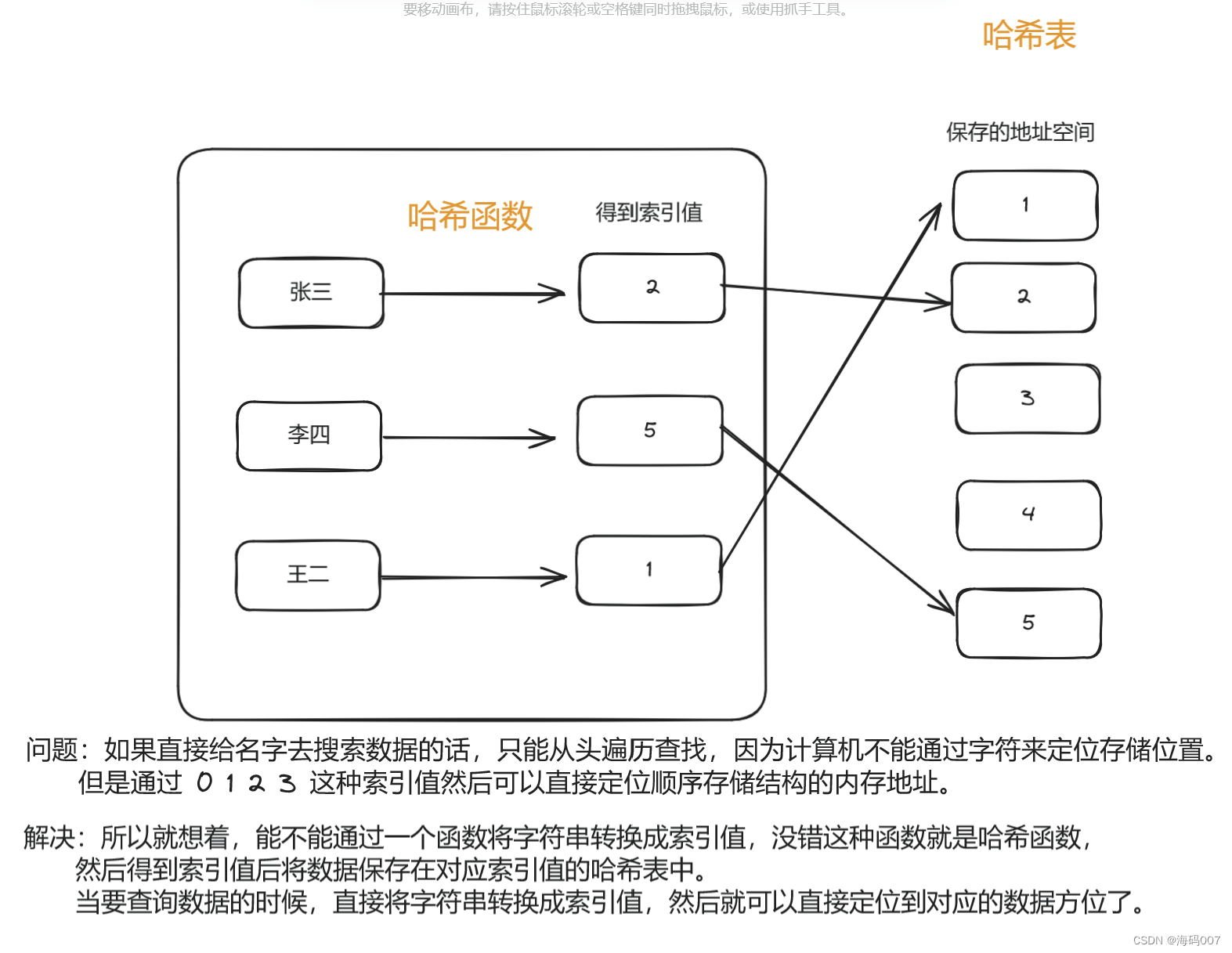
想使用哈希方法解决问题的时候(一般遇到判断某个元素是否在某个集合中出现的时候就用哈希表),一般常用如下三种数据结构
- 数组
- set(集合)
- map(映射)
1 有效的字母异位词
- 🎈 文档讲解:代码随想录
- 🎈 视频讲解:
- 🎈 做题状态:顺利写出来
1.1 string的回顾
不足:string字符串的遍历有点忘记了,下面总结一下遍历string字符串的几种方式:
- 使用 operator [] 进行遍历。 string s; s[0]
- 使用迭代器遍历,因为string也是属于stl中的容器,所以也可以使用迭代器。 string::iterator sit = s.begin()
- 使用 auto subS :s 的方式进行遍历
- operator [ ]
int StrToInt1(string s)
{int value = 0;for (size_t i = 0; i < s.size(); i++){value *= 10;value += s[i] - '0';}return value;
}- 迭代器
int StrToInt2(string s)
{int value = 0;string::iterator sit = s.begin();while (sit != s.end()){value *= 10;value += *sit - '0';sit++;}return value;
}- 新式for循环 auto
int StrToInt3(string s)
{int value = 0;for (auto e : s){value *= 10;value += e - '0';}return value;
}1.2 我的代码
思路:首先将 单个字符 和 ASCII码 联系起来,这样利用ASCII码作为数组的下标索引,然后保存对应的 字符数据。
可以发现这就是哈希的思想,计算机不能直接对 字符 进行索引,但是我们可以将字符转换成 整数index 这样保存到数组中就可以直接索引到元素。
class Solution {
public:bool isAnagram(string s, string t) {// a的ASCII码是97,z的ASCII码是122// 新建一个数组,大小为(122-97+1)int arr[26] = {0};// 遍历字符串s,数组对应下标元素加一for (auto subS : s){int index = subS - 97;arr[index]++;}// 遍历字符串t,数组对应下标元素减一for (auto subT : t){int index = subT - 97;arr[index]--;}// 遍历 arr 数组如果元素全部为0,则返回truefor (int i = 0; i < 26; i++){if (arr[i] != 0){return false;}}return true;}
};
2 两个数组的交集
- 🎈 文档讲解:
- 🎈 视频讲解:https://www.bilibili.com/video/BV1ba411S7wu/?vd_source=d499e7f3a8e68e2b173b1c6f068b2147
- 🎈 做题状态:题目意思一开始理解错了,原来只要找到有相同元素的就行。我理解成要找出一个子序列相交
2.1 unordered_set 介绍
当然!让我们谈谈 C++ 中的 std::unordered_set。这是一个有趣的容器,它提供了快速的搜索、插入和删除唯一对象的功能。以下是关键要点:
-
std::unordered_set是什么?std::unordered_set是 C++ 中的一种 关联容器。- 它保存了一组指定类型(我们称之为
Key)的 唯一对象。 - 与
std::set不同,std::unordered_set中的元素 不按特定顺序排序。 - 内部根据它们的哈希值将元素组织到 桶 中。
-
复杂度:
- 搜索、插入和删除操作的 平均时间复杂度 都是常数时间。
- 实际性能取决于哈希函数的质量和元素数量。
-
成员函数:
begin()、end()、empty()、size()、insert()、erase()、clear()等等。- 你还可以使用
emplace()来高效地插入元素。
-
哈希:
- 哈希函数决定了元素属于哪个桶。
- 如果需要,你可以自定义哈希函数。
-
示例用法:
#include <iostream> #include <unordered_set>int main() {std::unordered_set<int> mySet;mySet.insert(42);mySet.insert(17);mySet.insert(99);for (const auto& value : mySet) {std::cout << value << " ";}// 输出:99 42 17return 0; } -
记住:
std::unordered_set中的元素是 唯一的(没有重复项)。- 当你需要快速查找且不关心顺序时,可以使用它。
想要了解更多细节,请查阅 C++ 参考文档 或者探索一些实际示例! 🚀🔍
2.2 我的解题(set)
- 使用数组(由于题目中,数组总数量不超过1000,所以可以直接用数组作为哈希表,这样可以提高效率)
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {unordered_set<int> result;// 初始化哈希set,这样重复的数字直接去除了int hashMap[1001] = {0};for (int i = 0; i < nums1.size(); i++){// 将 nums1 数组映射到 hashMap 中hashMap[nums1[i]] = 1;}for (int i = 0; i < nums2.size(); i++){// 将 nums1 数组映射到 hashMap 中if (hashMap[nums2[i]] == 1){result.insert(nums2[i]);}}vector<int> v_result(result.begin(), result.end());return v_result;}
- 使用 unordered_set 制作哈希表,当哈希表元素总量不确定时,用 unordered_set 容器比较好
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {// 初始化哈希set,这样重复的数字直接去除了unordered_set<int> hashMap(nums1.begin(), nums1.end());unordered_set<int> result;for (int i = 0; i < nums2.size(); i++){auto search = hashMap.find(nums2[i]);if (search != hashMap.end()){// 如果找到一个元素有交集,则插入result中result.insert(nums2[i]);}}vector<int> v_result(result.begin(), result.end());return v_result;}
};
3 快乐数
- 🎈 文档讲解:https://programmercarl.com/0202.%E5%BF%AB%E4%B9%90%E6%95%B0.html#%E6%80%9D%E8%B7%AF
- 🎈 视频讲解:
- 🎈 做题状态:对怎么样进去数的拆分求和都忘记了
3.1 我的解题(set)
注意点: hashMap.find(sum) != hashMap.end() 表示找到相同的元素。 有点反逻辑明明是相同,判断条件里确实 != 。
让我们来解释一下:
-
首先,让我们看一下
hashMap.find(sum)的含义。在 C++ 中,std::unordered_map的find函数用于查找给定键(sum)是否存在于哈希表中。如果找到了相应的键,则返回指向该键的迭代器;否则,返回指向哈希表末尾的迭代器(即hashMap.end())。 -
现在,我们来看看条件
hashMap.find(sum) != hashMap.end():- 如果
hashMap.find(sum)返回的迭代器不等于hashMap.end(),那么表示找到了相同的元素。 - 如果
hashMap.find(sum)返回的迭代器等于hashMap.end(),那么表示没有找到相同的元素。
- 如果
因此,虽然看起来有点反直觉,但这个条件确实是用于判断是否找到了相同的元素。🙂
class Solution {
public:bool isHappy(int n) {// 将求出来的和放入哈希表中// 当放入时已经有重复出现的数的话,则直接返回false,否则知道sum等于1返回trueunordered_set<int> hashMap;int sum = 0;while(true){// 1. 对n进行拆分求和sum = 0;while(n != 0){cout << "n = " << n << endl;sum += (n%10) * (n%10);n /= 10;}cout << "sum = " << sum << endl;// 当sum为1的时候,直接返回trueif (sum == 1) return true;// 判断是否已经是第二次出现,如果不是,则将sum存入哈希表中auto search = hashMap.find(sum);if ( search != hashMap.end() ){// 如果已经是第二次出现,则直接返回falsereturn false;}hashMap.insert(sum);// 将n重新赋值n = sum;}}
};
4 两数之和
- 🎈 文档讲解:
- 🎈 视频讲解:
- 🎈 做题状态:之前已经用暴力求解做出来了,但是哈希的方式没想出来
4.1 暴力求解
class Solution {
public:std::vector<int> twoSum(std::vector<int>& nums, int target) {std::vector<int> result;int sum;for (int i = 0; i < nums.size() - 1; i++) {for (int j = i + 1; j < nums.size(); j++) { // 修改此处的循环条件sum = nums[i] + nums[j];if (sum == target) {result.push_back(i);result.push_back(j);return result;}}}// 如果没有找到符合条件的索引,可以返回一个空的 vectorreturn result;}
};4.2 map的使用
当谈到使用 unordered_map 时,我们通常是在处理键值对的无序集合。下面详细介绍了 unordered_map 的创建、插入、删除以及其他操作的方法和时间复杂度:
-
创建和定义
unordered_map:- 使用默认构造函数创建空的
unordered_map:std::unordered_map<std::string, int> umap; - 在创建时进行初始化:
std::unordered_map<std::string, std::string> umap {{"Python教程", "[9](http://c.biancheng.net/stl/)"},{"Java教程", "[10](http://c.biancheng.net/java/)"} };
- 使用默认构造函数创建空的
-
插入元素:
-
使用
emplace()方法插入键值对:umap.emplace("C++教程", "[11](http://c.biancheng.net/cplus/)"); -
insert()方法:
使用insert()方法可以将键值对元素添加到unordered_map中。语法格式有两种:- 以普通方式传递参数:
std::unordered_map<int, std::string> umap; umap.insert(std::make_pair(1, "hello")); - 以右值引用的方式传递参数(C++11 及以上版本):
umap.insert({2, "world"});
- 以普通方式传递参数:
-
insert_or_assign()方法:
使用insert_or_assign()方法可以插入元素,或者如果键已存在,则赋值给当前元素。示例:umap.insert_or_assign(3, "new value"); -
try_emplace()方法:
使用try_emplace()方法,如果键不存在,则原位插入;如果键已存在,则不做任何操作。示例:umap.try_emplace(4, "another value"); -
emplace_hint()方法:
使用emplace_hint()方法可以在指定位置原位构造元素。示例:auto hint = umap.begin(); umap.emplace_hint(hint, 5, "hinted value");
-
-
访问元素:
- 使用
[]运算符或at()方法访问元素:std::string python_url = umap["Python教程"]; // 或者 std::string java_url = umap.at("Java教程");
- 使用
-
删除元素:
- 使用
erase()方法删除指定键的元素:umap.erase("Java教程");
- 使用
-
其他操作:
- 迭代器:可以使用迭代器遍历
unordered_map中的元素。 - 大小:使用
size()方法获取元素个数。
- 迭代器:可以使用迭代器遍历
-
时间复杂度:
- 插入、查找、删除操作的平均时间复杂度为 O(1),但在最坏情况下可能为 O(n)(例如哈希冲突)。
- 注意,这里的时间复杂度是平均情况下的估计,实际性能可能受到哈希函数和数据分布的影响。
总之,unordered_map 是一个适用于需要快速插入、删除和查找数据的场景的容器。在选择使用 map 还是 unordered_map 时,需要根据具体的需求来进行选择。¹²³⁴
4.3 哈希表(map)
本题的重要三点内容:
- 为什么想到用哈希表
- 为什么使用map作为哈希表,而不是set
- 本题map是保存了什么数据,什么是键,什么是值
使用 unordered_set 作为哈希表时,存在一个问题,就是找到了那两个元素之后,只能知道元素的值和其中一个元素的下标,另一个元素的下标未知。因为 unordered_set 只保存了键。缺陷代码如下:
class Solution {
public:std::vector<int> twoSum(std::vector<int>& nums, int target) {unordered_set<int> hashMap(nums.begin(), nums.end());for (int i = 0; i < nums.size(); i++){if (hashMap.find(target - nums[i]) != hashMap.end()){cout << "找到了" << endl;// 无法确定另一个元素的索引值std::vector<int> v_result = {i, target - nums[i]};return v_result;}}return nums;}
};
所以需要使用 unordered_map 容器key用来存放元素值,value用来存放索引。
我的思路:先遍历将 vector 的元素值和索引存入 map 中,然后遍历 vector 判断 target - nums[i] 是否在 map 容器中如果存在,则返回。
代码随想录:直接遍历 vector 判断 target - nums[i] 是否在 map 容器中如果存在则返回,如果不存在则插入当前的值。
class Solution {
public:vector<int> twoSum(vector<int>& nums, int target) {std::unordered_map <int,int> map;for (int i = 0; i < nums.size(); i++){auto iter = map.find(target - nums[i]);if (iter != map.end()){return {iter->second, i};}// 将 nums 中的元素值和索引插入 map 中map.insert(pair<int, int> (nums[i], i));}return {};}
};
这篇关于算法刷题Day6 | 242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1. 两数之和的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





