本文主要是介绍Pandas中的五种数据查询方法--【数值,列表,区间,条件,函数查询】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Pandas查询数据
Pandas查询数据的几种方法
1.df.loc方法,根据行、列的标签值查询
2. df.iloc方法,根据行、列的数字位置查询
3. df.where方法
4. df.query方法
.loc既能查询,又能覆盖写入,强烈推荐!
Pandas使用df.loc查询数据的方法
1.使用单个label值查询数据
2.使用值列表批量查询
3.使用数值区间进行范围查询
4.使用条件表达式查询
5.调用函数查询
·以上查询方法,既适用于行,也适用于列·注意观察降维dataFrame>Series>值
import pandas as pd1、读取数据
北京2018年全年天气预报
df=pd.read_csv('./datas/beijing_tianqi/beijing_tianqi_2018.csv',index_col='ymd')
df.head()
df.index
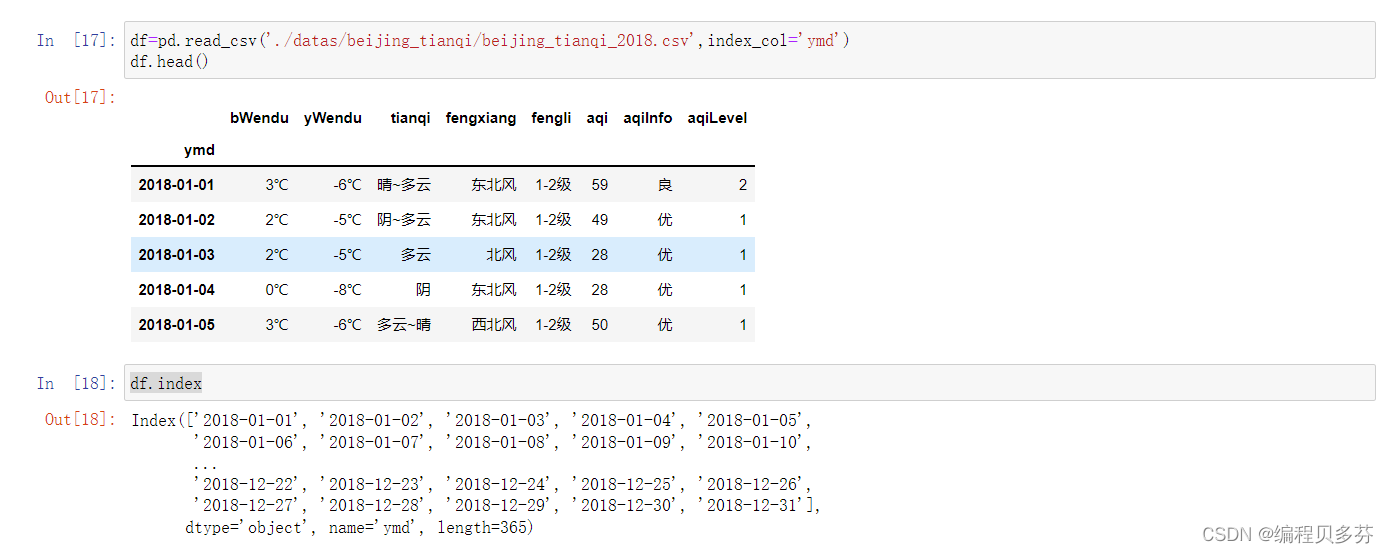
设置索引为日期,方便按日期筛选
inplace=True 表示直接在原存储空间上进行更改,不是重新开辟一块空间进行更改
#设置索引为日期,方便按日期筛选
#inplace=True 表示直接在原存储空间上进行更改,不是重新开辟一块空间进行更改
df.set_index('ymd',inplace=True)
df.head()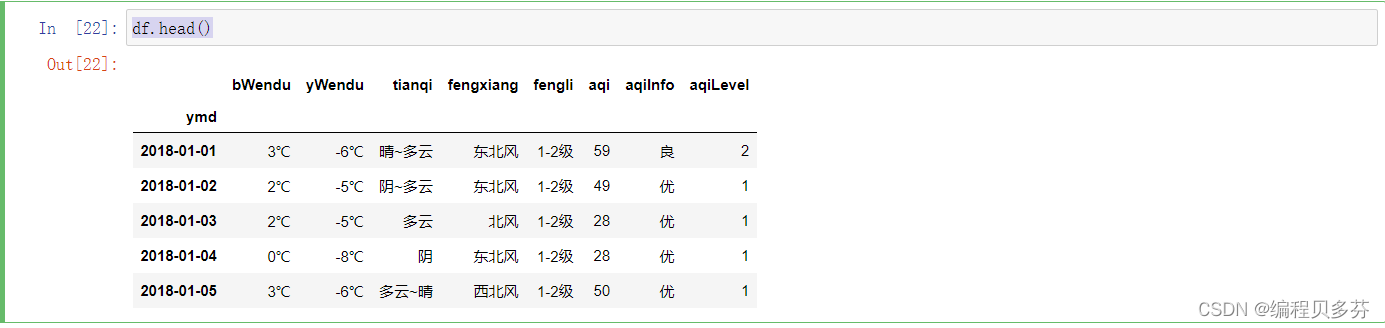
替换掉温度后的℃
其实还是使用切片操作,首先筛选出所有的行,在筛选出yWendu中一列,带着类型replace修改完之后,在对修改后的类型进行转换
df.loc[:,'bWendu']=df['bWendu'].str.replace('℃','').astype('int32')
df.loc[:,'yWendu']=df['yWendu'].str.replace('℃','').astype('int32')
df.head()
df.dtypes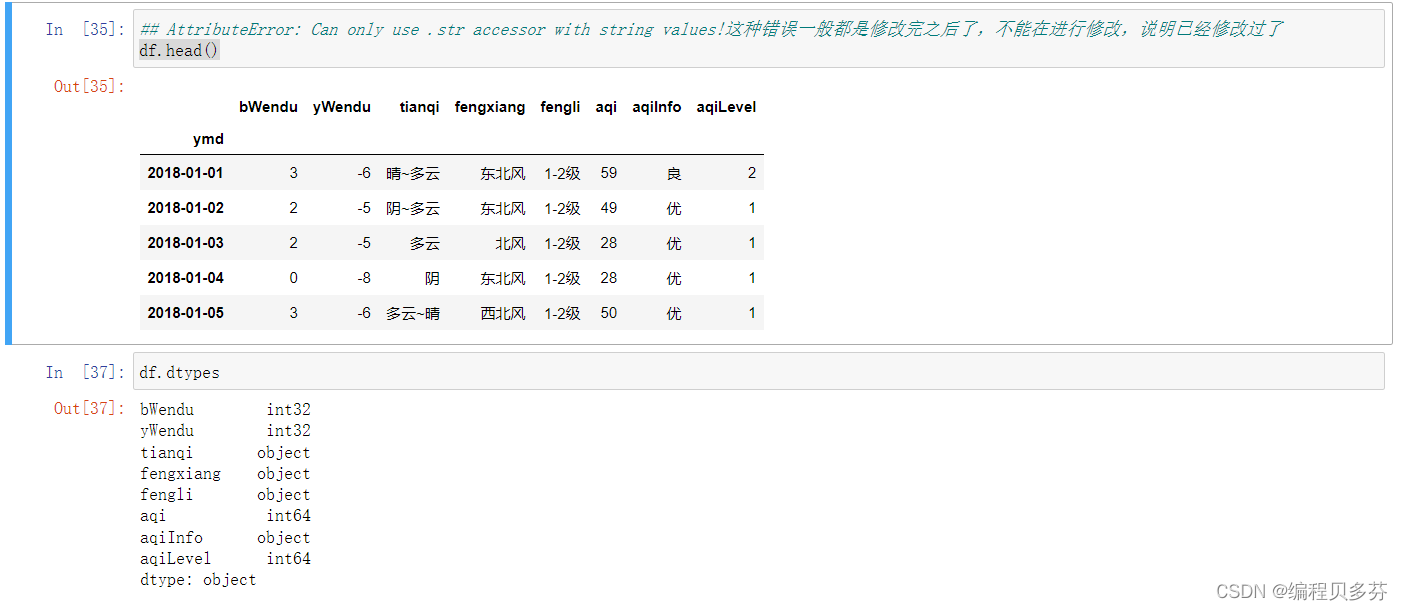
值得注意的是:
AttributeError: Can only use .str accessor with string values!这种错误一般都是修改完之后了,不能在进行修改,说明已经修改过了
1、使用单个label值查询数据¶
行或列,都可以只传入单个值,实现精确匹配
查询一个单元格,只会返回一个数字值
#查询一个单元格,只会返回一个数字值
df.loc['2018-01-01','bWendu']对于列的筛选,会产生一列,得到一个Series
#对于列的筛选,会产生一列,得到一个Series
df.loc['2018-01-01',['bWendu','yWendu']]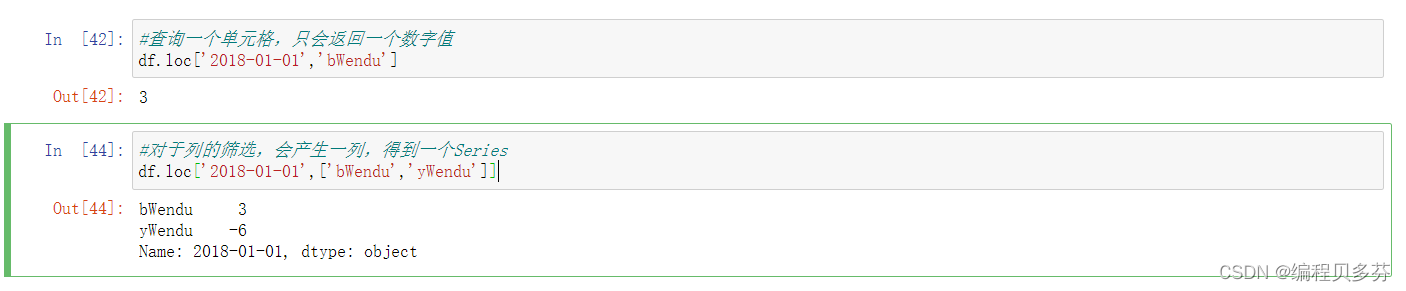
2、使用值列表批量查询
得到Series
#得到Series
df.loc[['2018-01-02','2018-01-03','2018-01-04'],'bWendu']得到DataFrame
#得到DataFrame
df.loc[['2018-01-02','2018-01-03','2018-01-04'],['bWendu','yWendu']]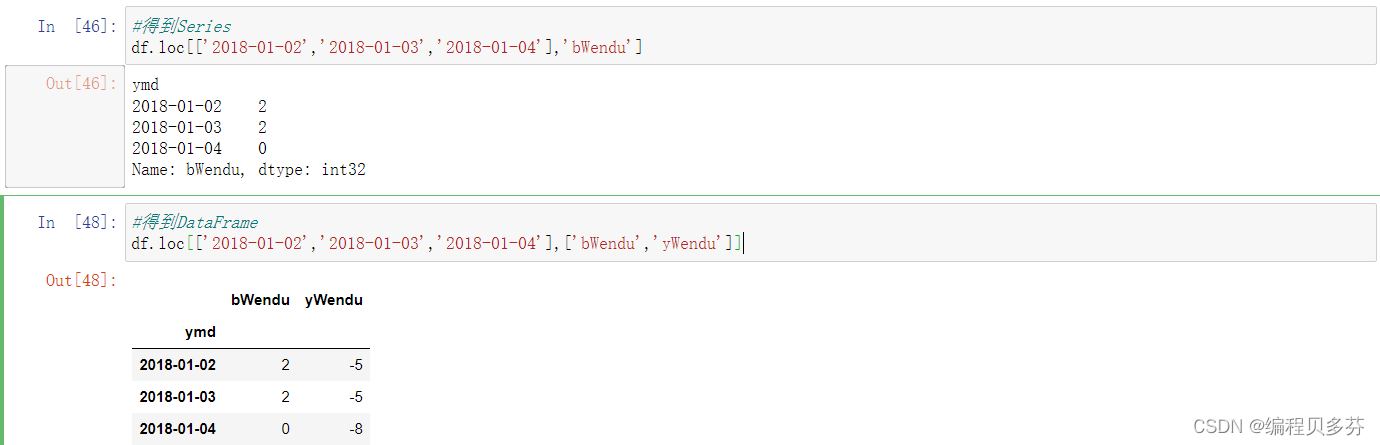
3、使用数值区间进行范围查询
注意:区间既包括开始,也包括结束
行index按区间,切片操作的时候不用加双【】
列index按区间
行和列都按区间查询
#行index按区间,切片操作的时候不用加双【】
df.loc['2018-01-03':'2018-01-05','bWendu']#列index按区间
df.loc['2018-01-03','bWendu':'fengxiang']#行和列都按区间查询
df.loc['2018-01-03':'2018-01-05','bWendu':'fengxiang']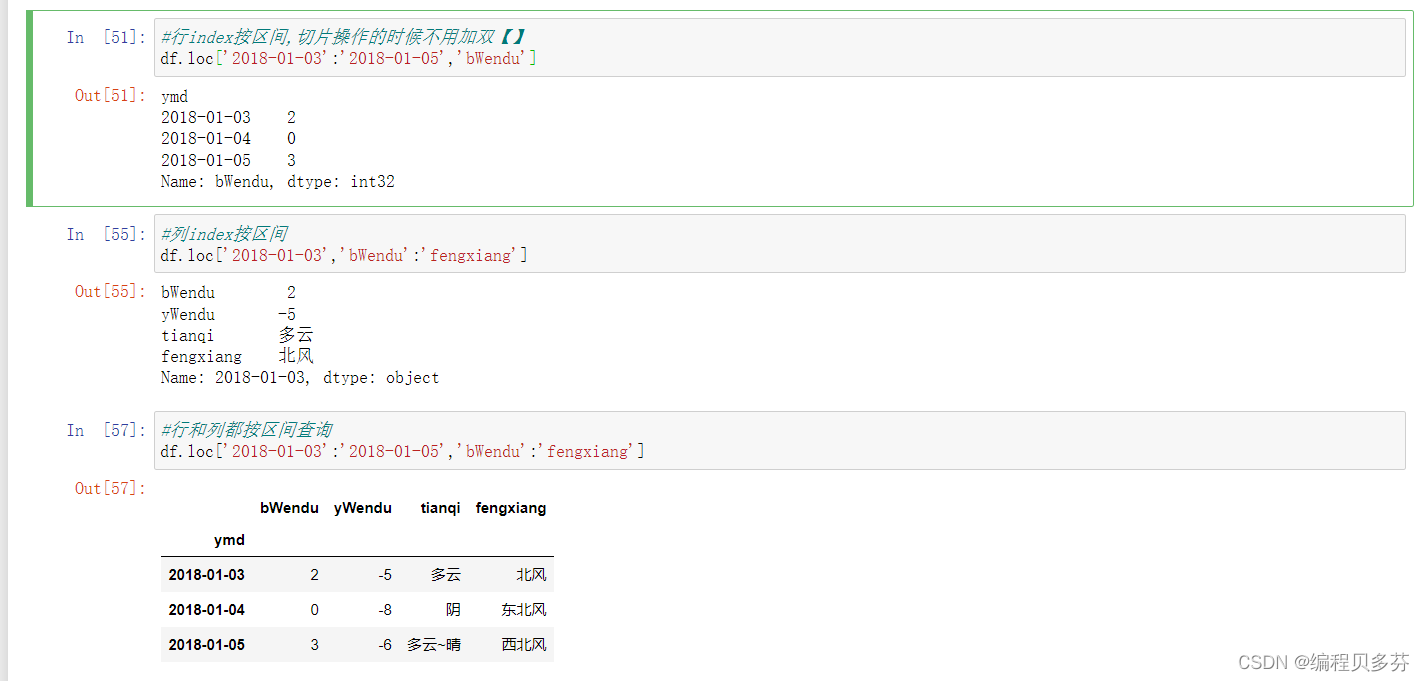
4、使用条件表达式查询¶
bool列表的长度等于行数或者列数
简单条件查询,最低温度低于-10度的列表
#简单条件查询,最低温度低于-10度的列表
df.loc[df['yWendu']<-10,:]观察这里的boolean条件
#观察这里的boolean条件
df['yWendu']<-10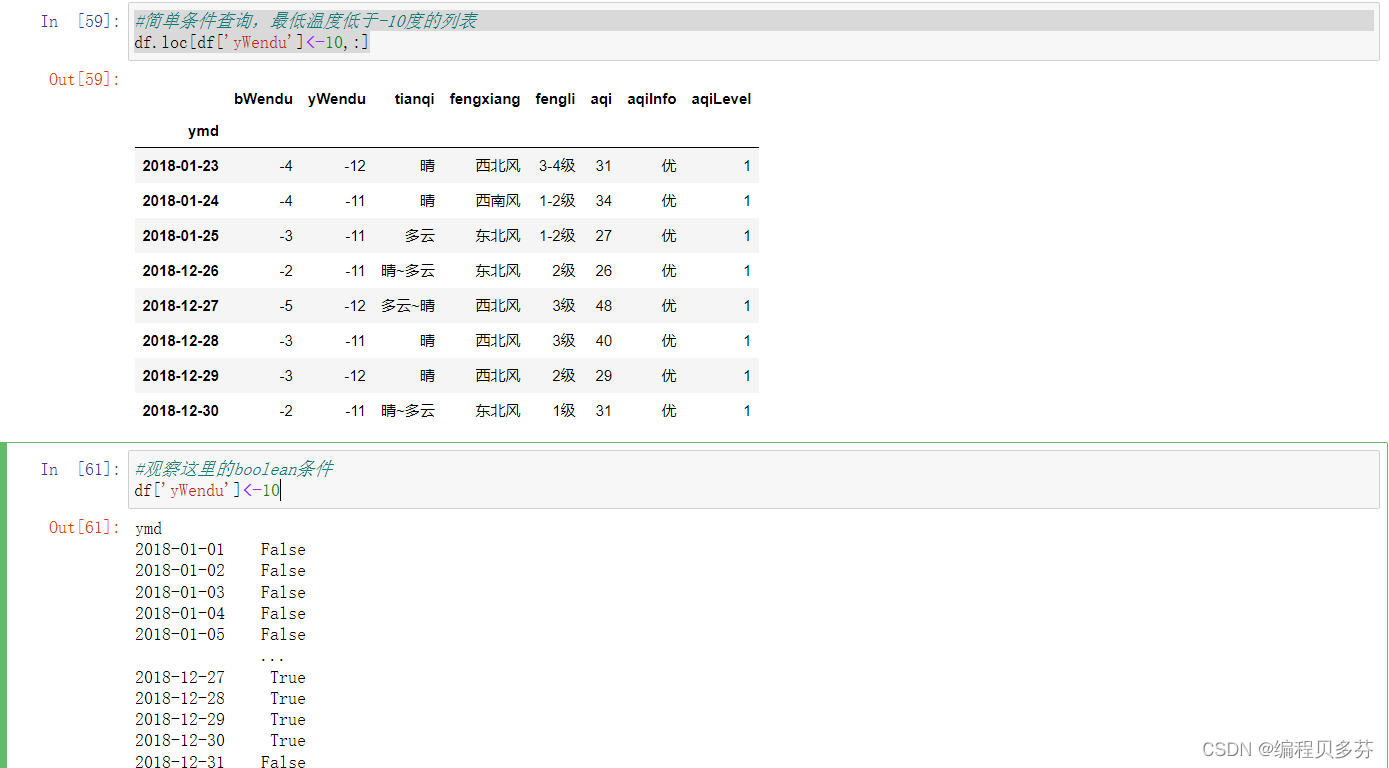
复杂条件查询,查完美天气
注意,组合条件&符号合并,每个条件判断都得带括号
查询最高温度小于30度,最低温度大于15度,晴天,天气为优的数据
#查询最高温度小于30度,最低温度大于15度,晴天,天气为优的数据
df.loc[(df['bWendu']<=30) & (df['yWendu']>=15) & (df['tianqi']=='晴') & (df['aqiLevel']==1),:]观察这里boolean的条件
#观察这里boolean的条件
(df['bWendu']<=30) & (df['yWendu']>=15) & (df['tianqi']=='晴') & (df['aqiLevel']==1)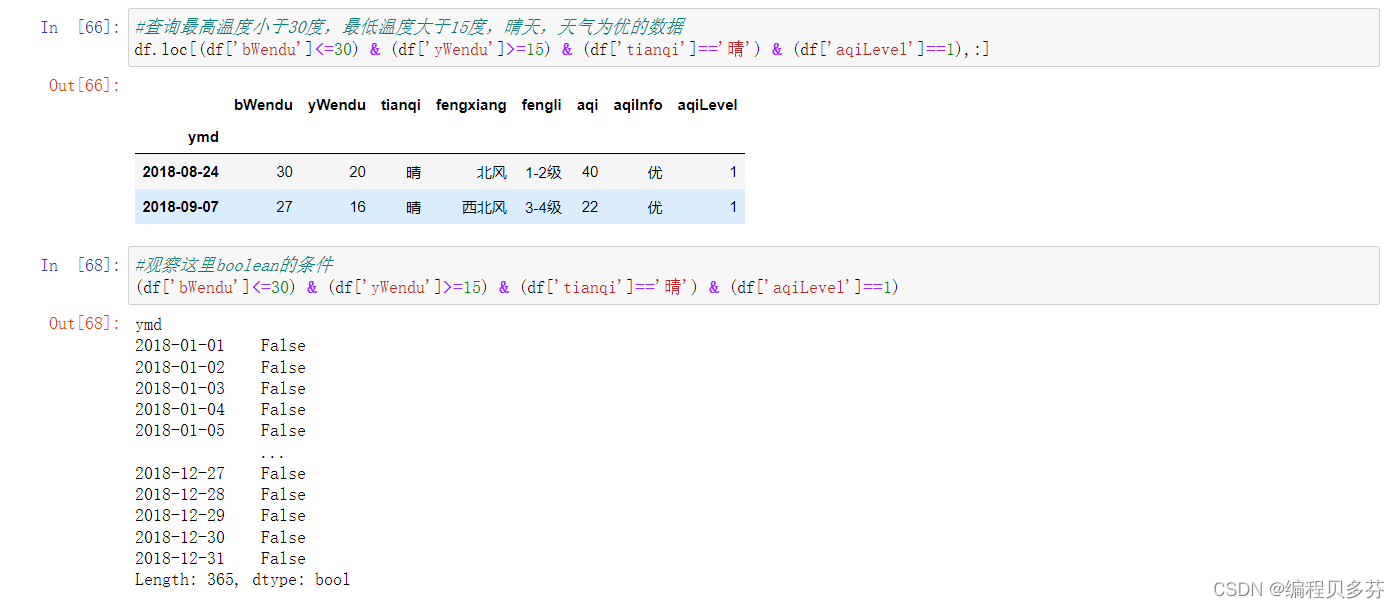
5、调用函数查询
直接写lambda表达式
# 直接写lambda表达式
df.loc[lambda df :(df['bWendu']<=30)&(df['yWendu']>=15),:]直接编写函数,查询9月份,空气质量好的数据
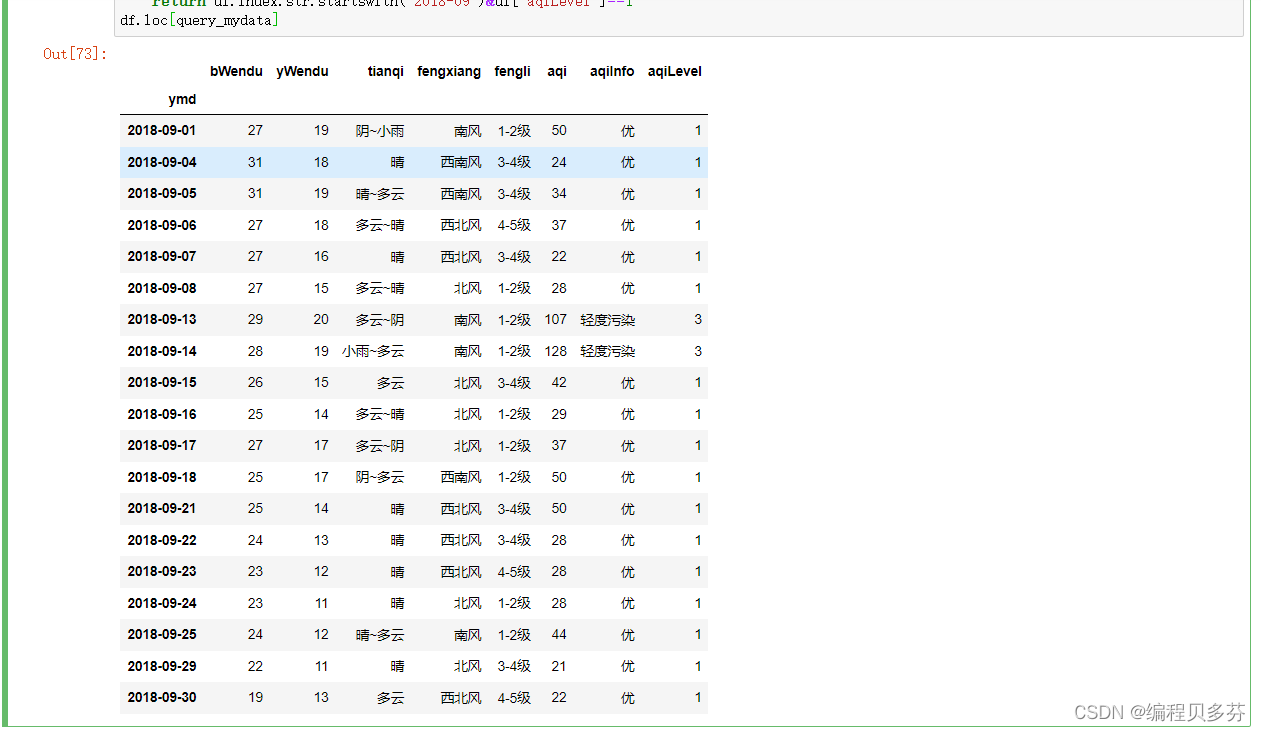
#直接编写函数,查询9月份,空气质量好的数据
def query_mydata(df):return df.index.str.startswith('2018-09')&df['aqiLevel']==1
df.loc[query_mydata]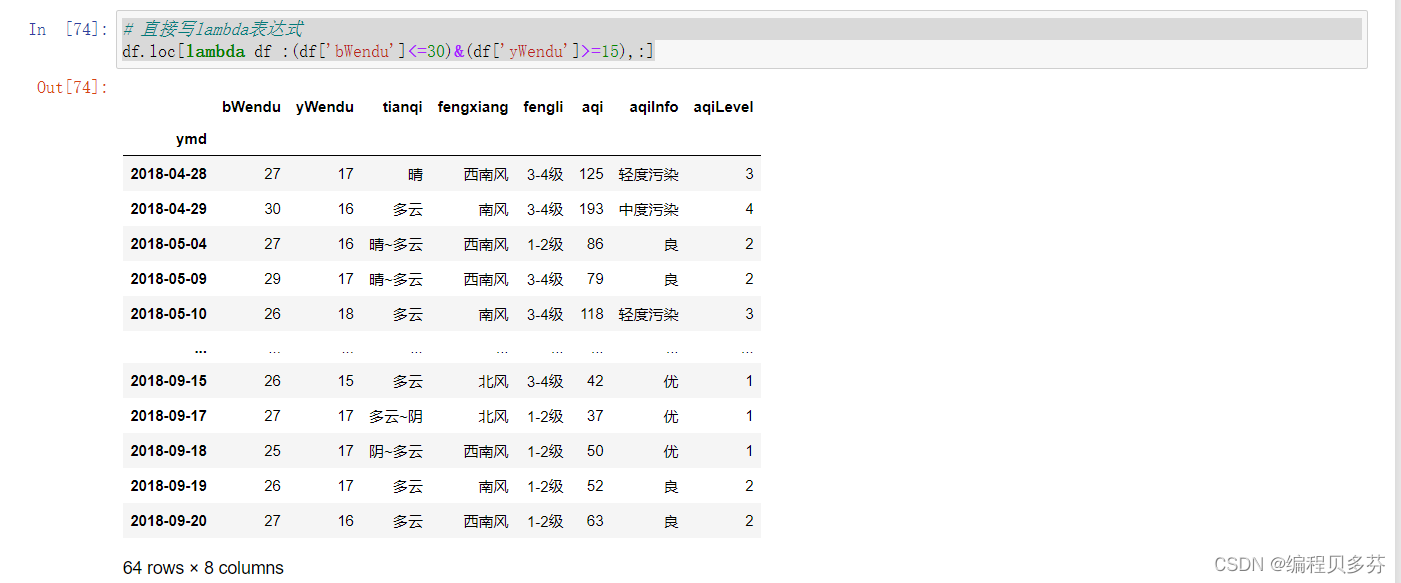
注意:
函数式编程的本质:函数自身可以像变量一样传递
这篇关于Pandas中的五种数据查询方法--【数值,列表,区间,条件,函数查询】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




