本文主要是介绍优化LSTM(鹈鹕POA-LSTM),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LSTM的核心是记忆单元(Memory Cell),其中包含了一个遗忘门(Forget Gate)、输入门(Input Gate)和输出门(Output Gate)。遗忘门决定了前一时刻记忆的保留程度,输入门决定了当前时刻输入的重要程度,输出门则控制了输出的内容。

LSTM的流程如下:
- 输入层接收序列数据,并通过全连接层传递给LSTM层。
- LSTM层中,通过遗忘门、输入门和输出门对输入信息进行筛选、更新和输出。
- 记忆单元根据遗忘门和输入门的控制,决定是否保留前一时刻的记忆,并将当前时刻的输入信息加入到记忆中。
- 经过计算和更新后,输出门控制着记忆单元中的信息输出到下一层或最终输出层。
- 根据网络的具体任务,在输出层进行适当的处理和预测
鹈鹕优化算法(Pelican Optimization Algorithm)是一种基于鹈鹕觅食行为的优化算法,用于解决优化问题。该算法模拟了鹈鹕觅食过程中的搜索行为和群体协作,以寻找最优解。
鹈鹕优化算法的原理如下:
初始化种群:随机生成一定数量的候选解(个体),每个个体代表一个潜在的解决方案。
评估适应度:根据问题的适应度函数,对每个个体进行评估,得到其适应度值。
个体行为更新:根据个体的当前位置和速度,计算其下一时刻的位置和速度,并更新个体的状态。
群体行为更新:根据个体之间的信息交流和合作,更新整个群体的状态。这包括通过觅食行为(Foraging Behavior)来搜索新的解空间,并通过交流行为(Communication Behavior)来分享信息和知识。
重复迭代:重复进行个体和群体的行为更新,直到满足终止条件,如达到最大迭代次数或找到满意的解。
输出最优解:根据最终种群中个体的适应度值,选择适应度最高的个体作为最优解。
鹈鹕优化法通过模拟鹈鹕觅食行为中的搜索和合作机制,以一种自适应的方式寻找最优解。个体之间通过搜索和信息交流来获取更多的解空间信息,从而提高整个群体的搜索效率和优化能力。
鹈鹕优化算法优化lstm参数流程
以下是使用鹈鹕优化算法(Pelican Optimization Algorithm)来优化LSTM模型参数的基本流程:
1. 数据准备:首先,准备好用于训练和验证的数据集。将数据集划分为训练集和验证集,通常使用时间序列数据作为LSTM模型的输入。
2. 构建LSTM模型:使用深度学习框架(如TensorFlow、PyTorch等)构建LSTM模型。包括定义模型的结构、选择合适的激活函数、选择合适的损失函数等。
3. 定义适应度函数:根据LSTM模型的性能指标(如均方误差损失函数、准确率等),定义适应度函数。适应度函数的值越小越好。
4. 参数初始化:使用鹈鹕优化算法初始化LSTM模型的参数。初始化每个参数的取值范围,鹈鹕算法将根据这些范围内随机生成的初始参数进行优化。
5. 鹈鹕优化算法迭代:在每一代迭代中,通过计算适应度函数来评估当前最优参数的性能。然后,利用鹈鹕的独特搜索策略,更新参数值。
6. 终止条件:设置终止条件,例如达到最大迭代次数、适应度函数收敛等。
7. 模型评估和验证:使用验证集评估经过优化后的LSTM模型,计算性能指标(如准确率、均方误差等)来检验模型的性能。
8. 参数输出和应用:将经过优化的LSTM模型的参数保存下来,并应用于实际的预测任务中。
最终得到预测结果以预测为例图示

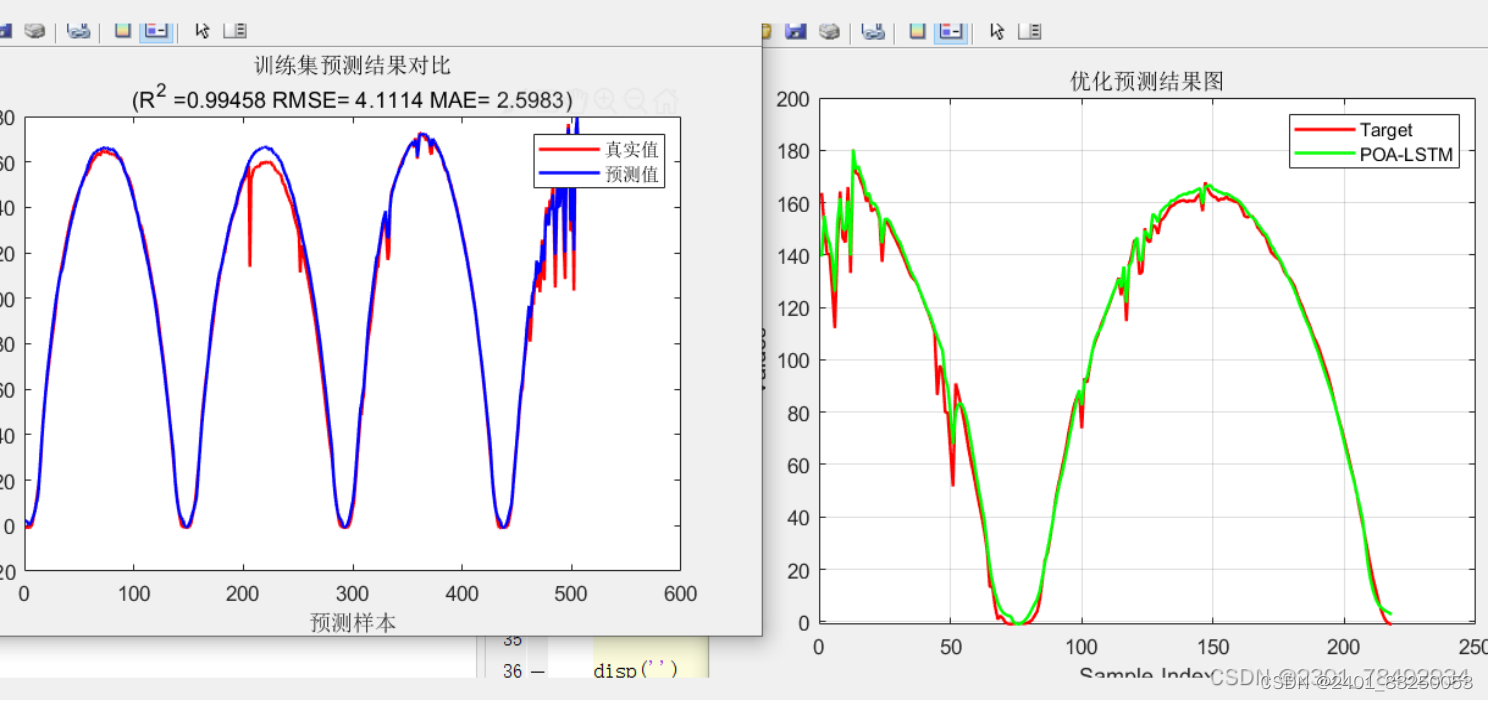
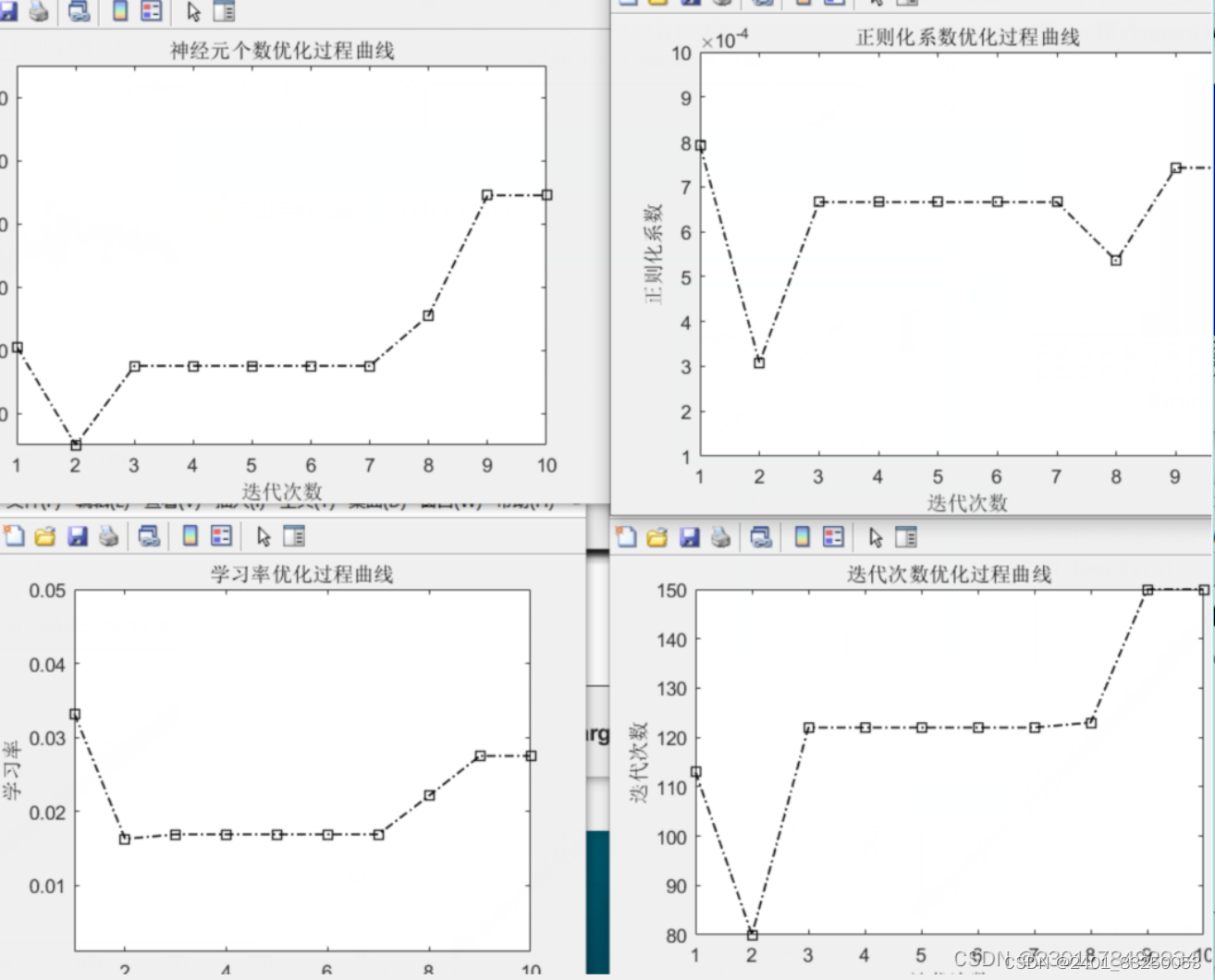
其中所优化的参数随迭代次数 的变化如图所示
这篇关于优化LSTM(鹈鹕POA-LSTM)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

