本文主要是介绍VINS-MONO代码解读5----vins_estimator(marginalization部分),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 0. 前言
- 1.1 Marginalization Pipiline
- 1. marg factor构建
- 1.1 变量及维度理解
- 1.2 IMUFactor
- 1.3 ProjectionTdFactor(ProjectionFactor)
- 1.4 MarginalizationFactor( e p e_p ep推导更新,FEJ解决的问题)
- 1.4.1 先验残差的更新
- 1.4.2 先验Jacobian的更新
- 2. ResidualBlockInfo构建
- 3. addResidualBlockInfo()加入到MarginalizationInfo中
- 4. preMarginalize()
- 4.1 ResidualBlockInfo::Evaluate()
- 4.2 鲁棒核函数
- 5. marginalize()
- 5.1 对marg和remain排序
- 5.1 信息矩阵与误差的构建
- 5.2 Schur compliment
- 5.2.1 理论介绍
- 5.2.2 两个trick
- 6. addr_shift 内存管理
- 7. slideWindow
- 7.1 整体代码
- 7.2 slideWindowOld(理解marg视觉观测、三角化、绑定深度)
- 7.3 slideWindowNew
- 8. 总结
0. 前言
单独用一篇文章来讲解VINS-MONO中的marginalization。
marg目的:为了维护我们优化问题的复杂度在一定的范围内,
如何marg:在新变量进来之前要把旧变量剔除出去,同时要保留旧变量对剩余变量的约束信息,理论依据是Schur compliment。
1.1 Marginalization Pipiline
本文着重讲解MARGIN_OLD部分,MARGIN_NEW部分很简单。
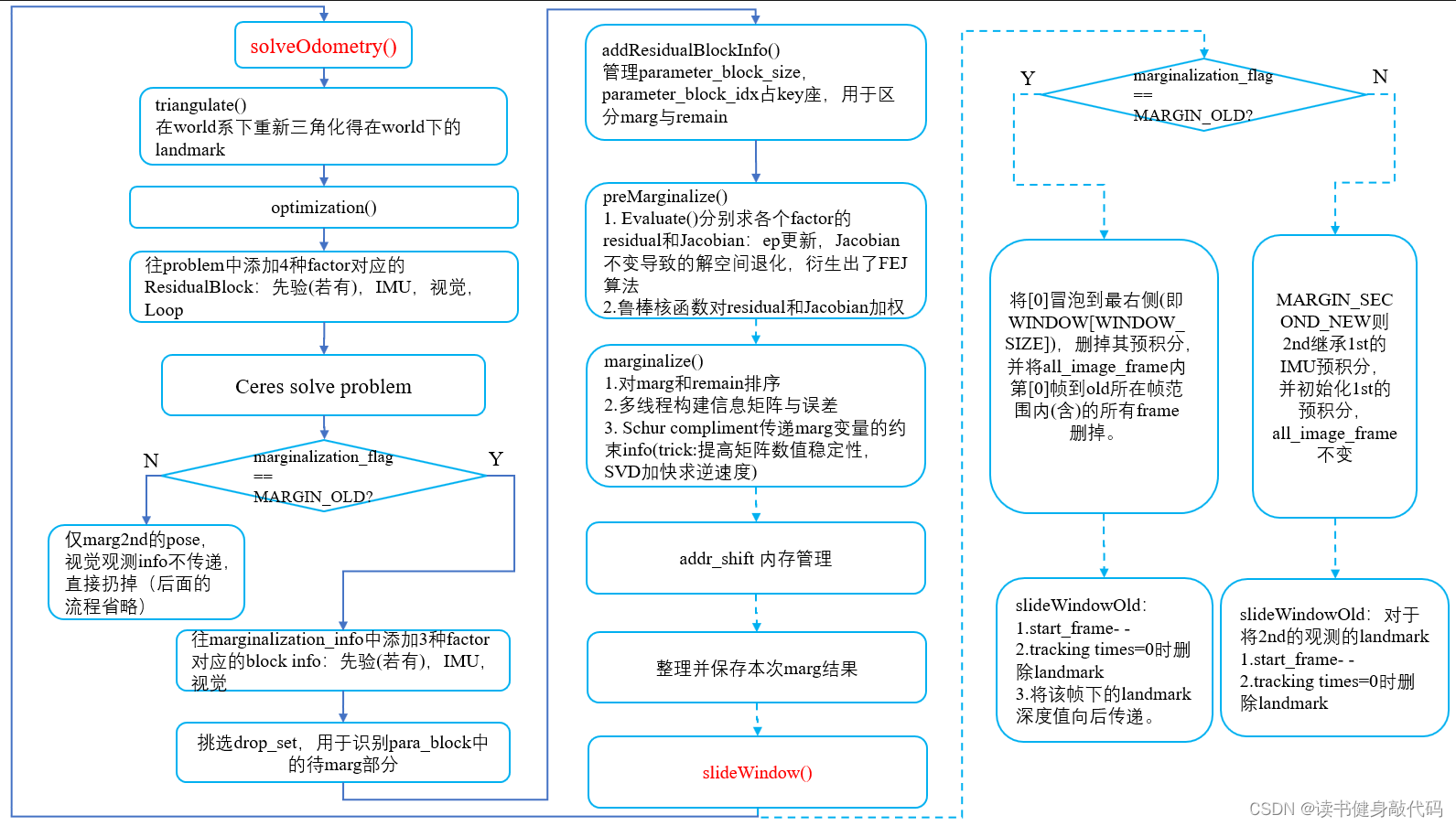
1. marg factor构建
marg_factor、ResidualBlockInfo、marg_info、ceres::problem的调用关系:

ceres::problem是整个系统的优化,在optimization()前半部分进行的,其中第一个AddResidualBlock调用的就是上一次marg的结果,即这次优化的先验,重点是理解last_marginalization_info,下面会详细介绍。
marg部分的信息矩阵由3部分构成:先验,IMU,视觉。程序里对应factor
针对每一部分factor,处理部分都是三板斧:
- 定义3种factor:
MarginalizationFactor,IMUFactor,ProjectionTdFactor(ProjectionFactor) - 构建ResidualBlockInfo
- 把addResidualBlockInfo加入到MarginalizationInfo中
分别在1.2~1.4节对这三板斧进行拆解。
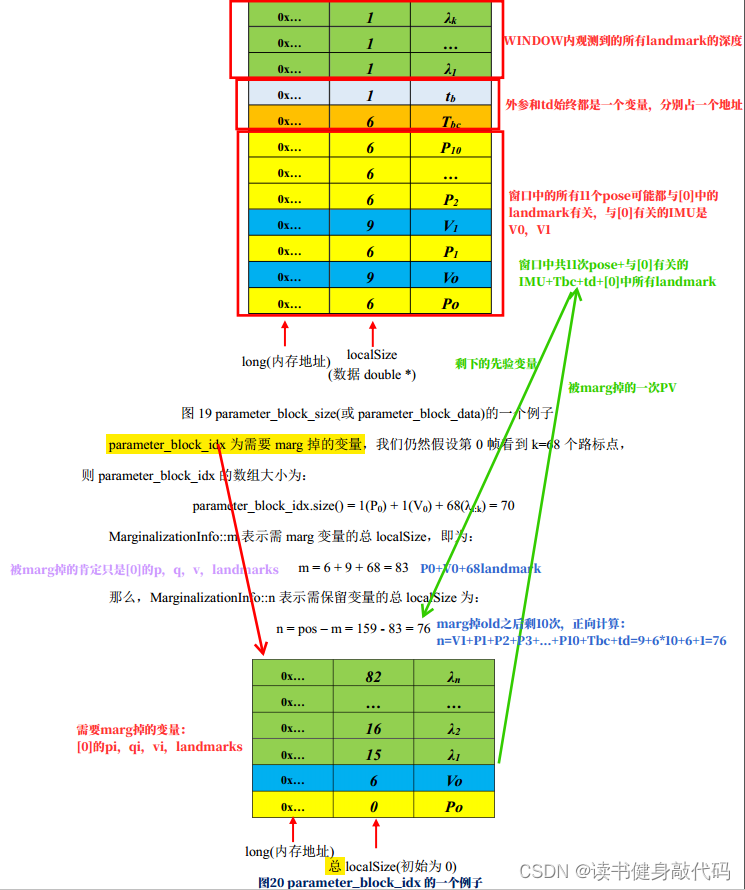
1.1 变量及维度理解
| 变量名 | 说明 |
|---|---|
marginalization_info | 保存marg的先验等信息 |
parameter_block_size | <与marg帧相关的优化变量内存地址,localSize> |
parameter_block_idx | <与marg帧相关的优化变量内存地址, idx> (前m维是marg,后n维是remain) |
parameter_block_data | <与marg帧相关的优化变量内存地址,数据> |
keep_block_data | keep_开头均与remain相关 |
m | 所有将被marg掉变量的localsize之和 |
n | 所有与将被marg掉变量有约束关系的变量的localsize之和 |
结合崔华坤PDF的解释来理解:
解释一下MARGIN_OLD为什么有11个P,因为old观测到的landmark可能被WINDOW内的pose都观测到了,marg掉old的视觉观测会对后面的视觉pose产生约束信息,所以都有residual边,所以11个都要。

在ResidualBlockInfo的Evaluate()中进行维度debug
ROS_DEBUG_STREAM("\ncost_function->num_residuals(): " << cost_function->num_residuals() <<"\ncost_function->parameter_block_sizes().size: " << cost_function->parameter_block_sizes().size());
for(int i=0; i<cost_function->parameter_block_sizes().size(); ++i) {ROS_DEBUG("\nparameter_block_sizes()[%d]: %d", i, cost_function->parameter_block_sizes()[i]);
}
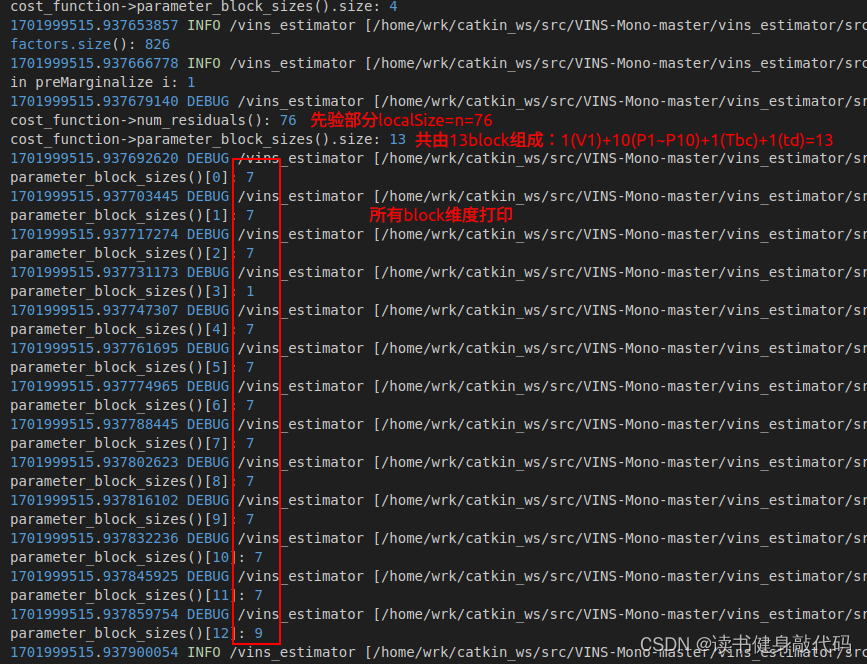
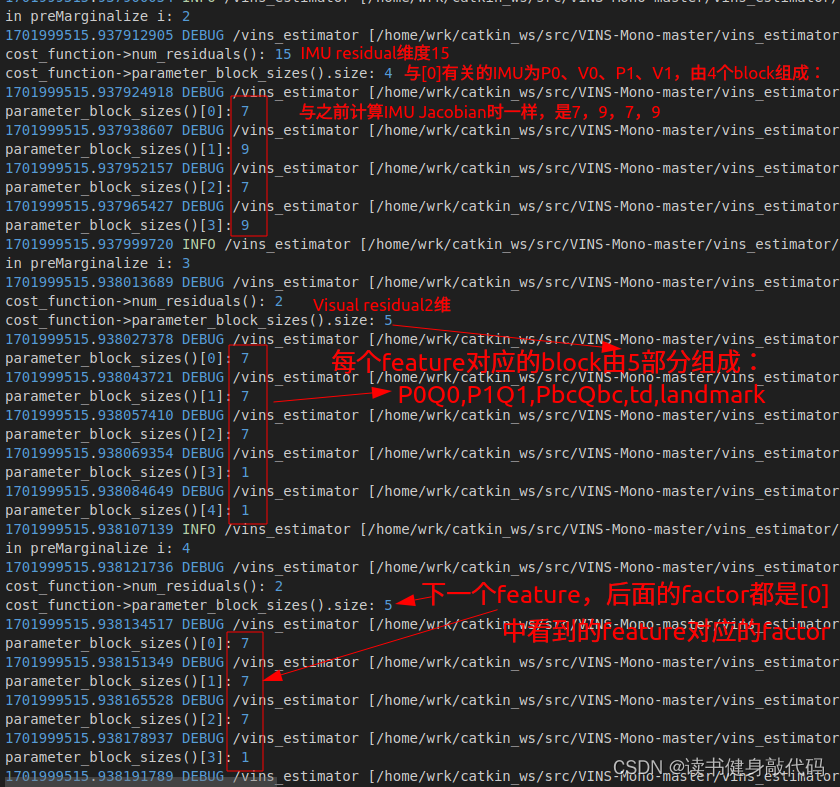
PS:后续的P的localSize函数会将维度7改为6。
1.2 IMUFactor
对应论文整体的cost function来理解

1.3 ProjectionTdFactor(ProjectionFactor)
同IMU factor。
1.4 MarginalizationFactor( e p e_p ep推导更新,FEJ解决的问题)
继承ceres::CostFunction的一个类,与前面两个factor是同一类型的类。
不同的factor是不同的类,但factor均继承ceres::CostFunction,不同factor调用evaluate()的是其各自的虚函数,属于多态。
定义了新的factor就要考虑residual如何计算、残差块的Jacobian如何计算,MarginalizationFactor中重载的虚函数Evaluate()就完成了先验残差 e p e_p ep和先验Jacobian的更新,在1.4.1和1.4.2节详细介绍。
代码注释:
//先验部分的factor,求Jacobian
bool MarginalizationFactor::Evaluate(double const *const *parameters, double *residuals, double **jacobians) const
{int n = marginalization_info->n;int m = marginalization_info->m;Eigen::VectorXd dx(n);for (int i = 0; i < static_cast<int>(marginalization_info->keep_block_size.size()); i++){int size = marginalization_info->keep_block_size[i];int idx = marginalization_info->keep_block_idx[i] - m;//因为当时存的是marg时的idx,是在m后面的,现在单看先验块的话就需要减去m//优化后,本次marg前的待优化变量Eigen::VectorXd x = Eigen::Map<const Eigen::VectorXd>(parameters[i], size);//优化前,上次maerg后的变量,即Jacobian的线性化点x0Eigen::VectorXd x0 = Eigen::Map<const Eigen::VectorXd>(marginalization_info->keep_block_data[i], size);//求优化后的变量与优化前的差,dx即公式中的δxp。//IMU block、landmark depth bolck直接相减,而camera pose block的rotation部分需使用四元数计算δxpif (size != 7)dx.segment(idx, size) = x - x0;else{//translation直接相减dx.segment<3>(idx + 0) = x.head<3>() - x0.head<3>();//rotation部分:δq=[1, 1/2 delta theta]^T(为何非要取正的?)dx.segment<3>(idx + 3) = 2.0 * Utility::positify(Eigen::Quaterniond(x0(6), x0(3), x0(4), x0(5)).inverse() * Eigen::Quaterniond(x(6), x(3), x(4), x(5))).vec();if (!((Eigen::Quaterniond(x0(6), x0(3), x0(4), x0(5)).inverse() * Eigen::Quaterniond(x(6), x(3), x(4), x(5))).w() >= 0)){dx.segment<3>(idx + 3) = 2.0 * -Utility::positify(Eigen::Quaterniond(x0(6), x0(3), x0(4), x0(5)).inverse() * Eigen::Quaterniond(x(6), x(3), x(4), x(5))).vec();}}}//更新误差:f' = f + J*δxpEigen::Map<Eigen::VectorXd>(residuals, n) = marginalization_info->linearized_residuals + marginalization_info->linearized_jacobians * dx;//Jacobian保持不变(FEJ要解决这样做带来的解的零空间变化的问题)if (jacobians){for (int i = 0; i < static_cast<int>(marginalization_info->keep_block_size.size()); i++){if (jacobians[i]){int size = marginalization_info->keep_block_size[i], local_size = marginalization_info->localSize(size);int idx = marginalization_info->keep_block_idx[i] - m;Eigen::Map<Eigen::Matrix<double, Eigen::Dynamic, Eigen::Dynamic, Eigen::RowMajor>> jacobian(jacobians[i], n, size);jacobian.setZero();jacobian.leftCols(local_size) = marginalization_info->linearized_jacobians.middleCols(idx, local_size);}}}return true;
}
1.4.1 先验残差的更新
本次solve后需要更新先验残差 e p e_p ep,如何更新呢?
先上结论: e p = e 0 + J l ∗ d x e_p=e_0+J_l*dx ep=e0+Jl∗dx
- e 0 e_0 e0是上次marg之后从信息矩阵和b中反解出来的residual,
- J l J_l Jl是上次反解出来的Jacobian
- dx是这次优化后,这次marg时的变量 x x x与上次marg时变量 x 0 x_0 x0(也即下文提到的线性化点)的差,理解为 d x = x k − x k − 1 dx=x_k-x_{k-1} dx=xk−xk−1
精简版推导(需要看):
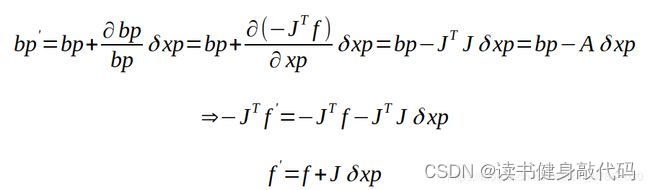
复杂版推导(可以跳过不看):
以下关于marg的推导截图自博客:



上述推导简单总结如下,发现了FEJ解决的问题所在:

1.4.2 先验Jacobian的更新
从代码中可以看出先验的Jacobian没有改变,仍然使用上一时刻的Jacobian,下面介绍为什么。
系统中两处使用到了先验的Jacobian:
- 本次solve时加入了先验(
last_marginalization_info)factor对应的ResidualBlock,ceres执行solve需要使用先验的Jacobian - 在执行marg时,构建信息矩阵也需要先验Jacobian
整体系统的Jacobian就一个,维度是pos*pos,只是我们某个factor部分的Jacobian的话,维度会比pos*pos小一点,这是因为其他一些无关变量不会算在部分的Jacobian中(如IMU的 b a b^a ba就与视觉residual无关,计算视觉Jacobian时就没有关于 b a b^a ba的部分),但是需要明确,整个系统就一个大的pos*pos的jacobian,相应的信息矩阵也就一个,只不过优化会导致Jacobian的值发生变化,而marg会导致优化变量发生变化,进而Jacobian也变化,但是需要清楚的是,我们从始至终维护的都只是这一个大的Jacobian.
在讲如何求先验的Jacobian之前,需要铺垫一下线性化点的相关内容:
记上次优化后的变量为 x 0 x_0 x0,对应的Jacobian是 J l J_l Jl,本次优化后的变量为 x ′ x^\prime x′,对应的Jacobian是 J ′ J^\prime J′,在程序中我们令 J ′ = J l J^\prime=J_l J′=Jl
J ′ J^\prime J′理应是residual对 x ′ x^\prime x′求导获得,但由于 x 0 x_0 x0中的一些变量(P0,V0,landmark等)已经在上次marg时被marg掉了,所以 x ′ x^\prime x′已经不是 x 0 x_0 x0了,但我们仍然让 J ′ = J l J^\prime=J_l J′=Jl。线性化点发生了变化,但Jacobian没变(从last_marginalization_info的信息矩阵中反解出来的),这就会导致 x x x的零空间发生变化,而FEJ算法解决的就是这个问题,只不过在VINS中没有使用,VINS认为对于小误差是有tolerance的。崔华坤PDF6.4节对于此部分有做讨论,可以去看看。
2. ResidualBlockInfo构建
这部分主要关注drop_set的表意:指定传入的_parameter_blocks中哪些是需要被marg的。
- 先验factor:old的P(
para_Pose[0]),V(para_SpeedBias[0]) - IMU factor:old的P(
para_Pose[0]),V(para_SpeedBias[0]) - Visual factor:old的P(
para_Pose[0]),从old开始观测的landmark(para_Feature[feature_index])
刚开始看代码时有个愚蠢的疑问,我们要marg的变量是通过传入drop_set来指定的,那为什么不直接传入marg的变量?为什么在代码中构建ResidualBlockInfo时还要传入P[1]V[1]这些remain的变量?原因是
- 如果不传,就不能复用之前定义的IMU和视觉的factor,需要重写不含remain的factor,重推Jacobian等。
- 也是最重要的一点,在后面构建marg信息矩阵时需要用到residual对于remain变量来说,它们需要接受marg帧传递信息,也即需要residual对remain的Jacobian,肯定要将remain变量传入。
3. addResidualBlockInfo()加入到MarginalizationInfo中
该函数完成两件事:
- 把每个factor中待优化参数的维度传给
parameter_block_size,建立 地址->size 的映射(eg:IMU factor的_parameter_blocks共有4个P0,V0,P1,V1:size分别是7,9,7,9,剩下的看Debug图理解即可) - 为要marg的变量占key的座,值为0。在
marginalize()中是否有key来区分marg和remain变量。
再贴一下1.1节的debug结果,现在理解就很容易了:
代码注释如下:
void MarginalizationInfo::addResidualBlockInfo(ResidualBlockInfo *residual_block_info)
{factors.emplace_back(residual_block_info);std::vector<double *> ¶meter_blocks = residual_block_info->parameter_blocks;//每个factor的待优化变量的地址std::vector<int> parameter_block_sizes = residual_block_info->cost_function->parameter_block_sizes();//待优化变量的维度//parameter_blocks.size//有td时,先验factor为13(9*1+6*10+6+1),IMU factor为4(7,9,7,9),每个feature factor size=5(7,7,7,1)//无td时 12 4 4for (int i = 0; i < static_cast<int>(residual_block_info->parameter_blocks.size()); i++){double *addr = parameter_blocks[i];int size = parameter_block_sizes[i];//待优化变量的维度//map没有key时会新建key-value对parameter_block_size[reinterpret_cast<long>(addr)] = size;//global size <优化变量内存地址,localSize>}//需要 marg 掉的变量for (int i = 0; i < static_cast<int>(residual_block_info->drop_set.size()); i++){double *addr = parameter_blocks[residual_block_info->drop_set[i]];//获得待marg变量的地址//要marg的变量先占个key的座,marg之前将m放在一起,n放在一起parameter_block_idx[reinterpret_cast<long>(addr)] = 0;//local size <待边缘化的优化变量内存地址,在parameter_block_size中的id>,}
}
4. preMarginalize()
代码注释:
void MarginalizationInfo::preMarginalize()
{
// ROS_INFO_STREAM("\nfactors.size(): " << factors.size());int i=0;for (auto it : factors){
// ROS_INFO_STREAM("\nin preMarginalize i: "<< ++i); //很大,能到900多,说明[0]观测到了很多landmarkit->Evaluate();//计算每个factor的residual和Jacobianstd::vector<int> block_sizes = it->cost_function->parameter_block_sizes(); //residual总维度,先验=last n=76,IMU=15,Visual=2for (int i = 0; i < static_cast<int>(block_sizes.size()); i++){long addr = reinterpret_cast<long>(it->parameter_blocks[i]);//parameter_blocks是vector<double *>,存放的是数据的地址int size = block_sizes[i];//如果优化变量中没有这个数据就new一片内存放置if (parameter_block_data.find(addr) == parameter_block_data.end()){double *data = new double[size];//dst,srcmemcpy(data, it->parameter_blocks[i], sizeof(double) * size);parameter_block_data[addr] = data;}}}
}
4.1 ResidualBlockInfo::Evaluate()
在info添加完所有的factor(先验,IMU,视觉)之后,分别求各个factor的residual和Jacobian,先验部分的residual和Jacobian的更新在1.4节已经讲解。
cost_function->Evaluate()是典型的多态。
4.2 鲁棒核函数
针对各个factor,如果传入了鲁棒核函数loss_function,则需要对residual和jacobian进行加权,简言之,计算权值并与residual、Jacobian相乘。
if (loss_function)
{double residual_scaling_, alpha_sq_norm_;double sq_norm, rho[3];sq_norm = residuals.squaredNorm();//loss_function 为 robust kernel function,in:sq_norm, out:rho out[0] = rho(sq_norm),out[1] = rho'(sq_norm), out[2] = rho''(sq_norm),loss_function->Evaluate(sq_norm, rho);//求取鲁棒核函数关于||f(x)||^2的一二阶导数//printf("sq_norm: %f, rho[0]: %f, rho[1]: %f, rho[2]: %f\n", sq_norm, rho[0], rho[1], rho[2]);double sqrt_rho1_ = sqrt(rho[1]);if ((sq_norm == 0.0) || (rho[2] <= 0.0)){residual_scaling_ = sqrt_rho1_;alpha_sq_norm_ = 0.0;}else{const double D = 1.0 + 2.0 * sq_norm * rho[2] / rho[1];//求根公式的△const double alpha = 1.0 - sqrt(D);//求根公式求方程的根residual_scaling_ = sqrt_rho1_ / (1 - alpha);alpha_sq_norm_ = alpha / sq_norm;}for (int i = 0; i < static_cast<int>(parameter_blocks.size()); i++){jacobians[i] = sqrt_rho1_ * (jacobians[i] - alpha_sq_norm_ * residuals * (residuals.transpose() * jacobians[i]));}residuals *= residual_scaling_;
}
带robust kernel function的Jacobian,总体思想是:用robust kernel function计算一个scale,用于对原residual进行缩放,对Jacobian进行加权:
- Ceres官方文档
- 参考博客
ceres官方文档如下图

对theory进行简单推导以理解代码
上述theory中重要的是核函数关于 ∣ ∣ f ( x ) ∣ ∣ 2 ||f(x)||^2 ∣∣f(x)∣∣2的一二阶导数,和 α \alpha α的求解,导数部分调用loss_function->Evaluate即可,我们需要手动求解 α \alpha α,对于公式
1 2 α 2 − α − ρ ′ ′ ρ ′ ∣ ∣ f ( x ) ∣ ∣ 2 = 0 \frac{1}{2}\alpha^2-\alpha-\frac{\rho^{\prime\prime}}{\rho^{\prime}}||f(x)||^2=0 21α2−α−ρ′ρ′′∣∣f(x)∣∣2=0
运用求根公式可求得 α \alpha α,其中
a = 1 2 b = − 1 c = − ρ ′ ′ ρ ′ ∣ ∣ f ( x ) ∣ ∣ 2 \begin{align*} &a=\frac{1}{2} \notag\\ &b=-1\notag \\ &c=-\frac{\rho^{\prime\prime}}{\rho^{\prime}}||f(x)||^2 \end{align*} a=21b=−1c=−ρ′ρ′′∣∣f(x)∣∣2
所以 α = − b ± b 2 − 4 a c 2 a = 1 ± 1 + 2 ρ ′ ′ ρ ′ ∣ ∣ f ( x ) ∣ ∣ 2 1 \alpha=\frac{-b\pm\sqrt{b^2-4ac}}{2a}=\frac{1\pm\sqrt{1+2\frac{\rho^{\prime\prime}}{\rho^{\prime}}||f(x)||^2}}{1} α=2a−b±b2−4ac=11±1+2ρ′ρ′′∣∣f(x)∣∣2
代码中D= 1 + 2 ρ ′ ′ ρ ′ ∣ ∣ f ( x ) ∣ ∣ 2 1+2\frac{\rho^{\prime\prime}}{\rho^{\prime}}||f(x)||^2 1+2ρ′ρ′′∣∣f(x)∣∣2
5. marginalize()
先上代码注释:
//线程函数
void* ThreadsConstructA(void* threadsstruct)
{ThreadsStruct* p = ((ThreadsStruct*)threadsstruct);//遍历该线程分配的所有factors,所有观测项for (auto it : p->sub_factors){//遍历该factor中的所有参数块P0,V0等for (int i = 0; i < static_cast<int>(it->parameter_blocks.size()); i++){int idx_i = p->parameter_block_idx[reinterpret_cast<long>(it->parameter_blocks[i])];int size_i = p->parameter_block_size[reinterpret_cast<long>(it->parameter_blocks[i])];if (size_i == 7) //对于pose来说,是7维的,最后一维为0,这里取左边6size_i = 6;//只提取local size部分,对于pose来说,是7维的,最后一维为0,这里取左边6维Eigen::MatrixXd jacobian_i = it->jacobians[i].leftCols(size_i);for (int j = i; j < static_cast<int>(it->parameter_blocks.size()); j++){int idx_j = p->parameter_block_idx[reinterpret_cast<long>(it->parameter_blocks[j])];int size_j = p->parameter_block_size[reinterpret_cast<long>(it->parameter_blocks[j])];if (size_j == 7)size_j = 6;Eigen::MatrixXd jacobian_j = it->jacobians[j].leftCols(size_j);//主对角线if (i == j)p->A.block(idx_i, idx_j, size_i, size_j) += jacobian_i.transpose() * jacobian_j;//非主对角线else{p->A.block(idx_i, idx_j, size_i, size_j) += jacobian_i.transpose() * jacobian_j;p->A.block(idx_j, idx_i, size_j, size_i) = p->A.block(idx_i, idx_j, size_i, size_j).transpose();}}p->b.segment(idx_i, size_i) += jacobian_i.transpose() * it->residuals;}}return threadsstruct;
}void MarginalizationInfo::marginalize()
{int pos = 0;//it.first是要被marg掉的变量的地址,将其size累加起来就得到了所有被marg的变量的总localSize=m//marg的放一起,共m维,remain放一起,共n维for (auto &it : parameter_block_idx){it.second = pos;//也算是排序1pos += localSize(parameter_block_size[it.first]);//PQ7为改为6维}m = pos;//要被marg的变量的总维度int tmp_n = 0;//与[0]相关总维度for (const auto &it : parameter_block_size){if (parameter_block_idx.find(it.first) == parameter_block_idx.end())//将不在drop_set中的剩下的维度加起来,这一步实际上算的就是n{parameter_block_idx[it.first] = pos;//排序2tmp_n += localSize(it.second);pos += localSize(it.second);}}n = pos - m;//remain变量的总维度,这样写建立了n和m间的关系,表意更强ROS_DEBUG("\nn: %d, tmp_n: %d", n, tmp_n);//ROS_DEBUG("marginalization, pos: %d, m: %d, n: %d, size: %d", pos, m, n, (int)parameter_block_idx.size());TicToc t_summing;Eigen::MatrixXd A(pos, pos);//总系数矩阵Eigen::VectorXd b(pos);//总误差项A.setZero();b.setZero();//multi thread 构建信息矩阵和误差项TicToc t_thread_summing;pthread_t tids[NUM_THREADS];//4个线程构建//携带每个线程的输入输出信息ThreadsStruct threadsstruct[NUM_THREADS];//将先验约束因子平均分配到4个线程中int i = 0;//for (auto it : factors){threadsstruct[i].sub_factors.push_back(it);i++;i = i % NUM_THREADS;}//将每个线程构建的A和b加起来for (int i = 0; i < NUM_THREADS; i++){TicToc zero_matrix;threadsstruct[i].A = Eigen::MatrixXd::Zero(pos,pos);threadsstruct[i].b = Eigen::VectorXd::Zero(pos);threadsstruct[i].parameter_block_size = parameter_block_size;threadsstruct[i].parameter_block_idx = parameter_block_idx;int ret = pthread_create( &tids[i], NULL, ThreadsConstructA ,(void*)&(threadsstruct[i]));if (ret != 0){ROS_WARN("pthread_create error");ROS_BREAK();}}//将每个线程构建的A和b加起来for( int i = NUM_THREADS - 1; i >= 0; i--){pthread_join( tids[i], NULL );//阻塞等待线程完成A += threadsstruct[i].A;b += threadsstruct[i].b;}//ROS_DEBUG("thread summing up costs %f ms", t_thread_summing.toc());//ROS_INFO("A diff %f , b diff %f ", (A - tmp_A).sum(), (b - tmp_b).sum());/*求Amm的逆矩阵时,为了保证数值稳定性,做了Amm=1/2*(Amm+Amm^T)的运算,Amm本身是一个对称矩阵,所以 等式成立。接着对Amm进行了特征值分解,再求逆,更加的快速*///数值计算中,由于计算机浮点数精度的限制,有时候数值误差可能导致 Amm 不精确地保持对称性。//通过将 Amm 更新为其本身与其转置的平均值,可以强制保持对称性,提高数值稳定性。这种对称性维护的策略在数值计算中比较常见。Eigen::MatrixXd Amm = 0.5 * (A.block(0, 0, m, m) + A.block(0, 0, m, m).transpose());Eigen::SelfAdjointEigenSolver<Eigen::MatrixXd> saes(Amm);//ROS_ASSERT_MSG(saes.eigenvalues().minCoeff() >= -1e-4, "min eigenvalue %f", saes.eigenvalues().minCoeff());//marg的矩阵块求逆,特征值分解求逆更快Eigen::MatrixXd Amm_inv = saes.eigenvectors()* Eigen::VectorXd((saes.eigenvalues().array() > eps).select(saes.eigenvalues().array().inverse(), 0)).asDiagonal()* saes.eigenvectors().transpose();//printf("error1: %f\n", (Amm * Amm_inv - Eigen::MatrixXd::Identity(m, m)).sum());Eigen::VectorXd bmm = b.segment(0, m);Eigen::MatrixXd Amr = A.block(0, m, m, n);Eigen::MatrixXd Arm = A.block(m, 0, n, m);Eigen::MatrixXd Arr = A.block(m, m, n, n);Eigen::VectorXd brr = b.segment(m, n);//Shur compliment marginalization,求取边际概率A = Arr - Arm * Amm_inv * Amr;b = brr - Arm * Amm_inv * bmm;//由于Ceres里面不能直接操作信息矩阵,所以这里从信息矩阵中反解出来了Jacobian和residual,而g2o是可以的,ceres里只需要维护H和bEigen::SelfAdjointEigenSolver<Eigen::MatrixXd> saes2(A);//对称阵Eigen::VectorXd S = Eigen::VectorXd((saes2.eigenvalues().array() > eps).select(saes2.eigenvalues().array(), 0));//对称阵的倒数阵Eigen::VectorXd S_inv = Eigen::VectorXd((saes2.eigenvalues().array() > eps).select(saes2.eigenvalues().array().inverse(), 0));Eigen::VectorXd S_sqrt = S.cwiseSqrt();//开根号Eigen::VectorXd S_inv_sqrt = S_inv.cwiseSqrt();//从H和b中反解出Jacobian和residuallinearized_jacobians = S_sqrt.asDiagonal() * saes2.eigenvectors().transpose();linearized_residuals = S_inv_sqrt.asDiagonal() * saes2.eigenvectors().transpose() * b;
5.1 对marg和remain排序
parameter_block_idx在addResidualBlockInfo时有过占key座,此时可以用来对marg和remain变量排序,将marg变量放在一起,remain放在一起,marginalize()里这段代码可以仔细欣赏一下。
5.1 信息矩阵与误差的构建
代码里使用多线程构建信息矩阵,将对不同变量的Jacobian根据parameter_block_idx和parameter_block_size放到相应的位置上去,
最终构建出下图所示的A和b:
residual共有3种:先验residual,IMU residual,Visual residual,而每个残差只和某几个状态量相关,所以对于无关项的Jacobian直接为0,

组装过程如下:
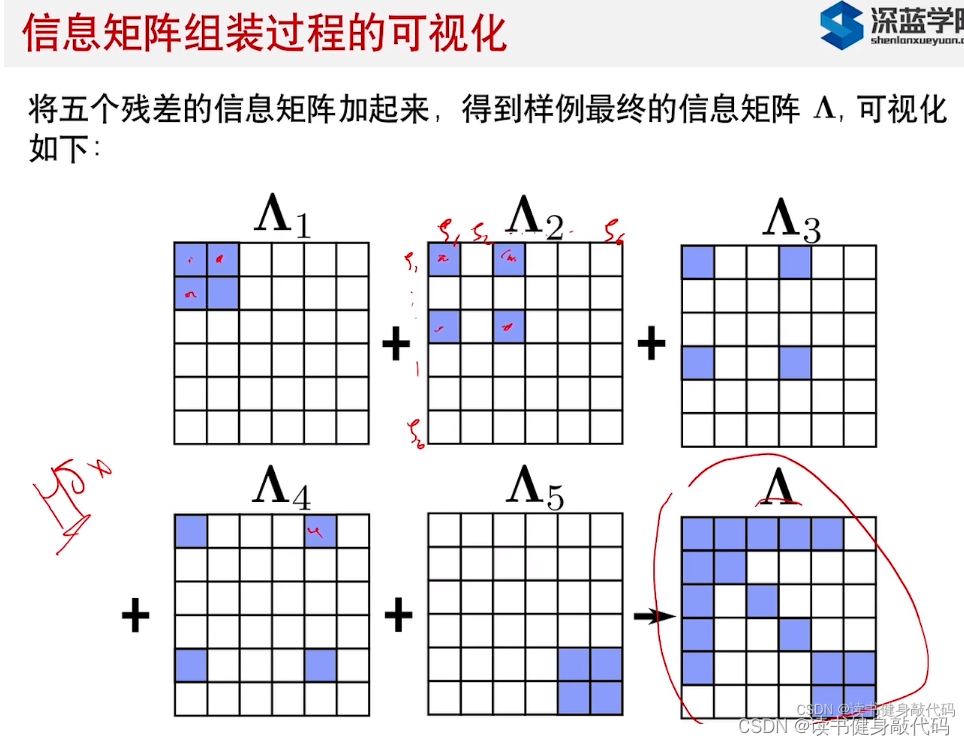
比如对于P0的信息矩阵,可能由上述3部分组成,而对于V0,可能由先验和IMU residual组成,来自不同部分的需要+=
最终构建结果如下图所示的形式:

5.2 Schur compliment
5.2.1 理论介绍
本部分理论详细介绍可参考之前的博客
核心结论就一张图:

5.2.2 两个trick
这里使用了两个trick:
- 提高对称阵
Amm的数值稳定性 - 特征值分解求解对称阵的逆
Amm_inv,加快求逆速度
//数值计算中,由于计算机浮点数精度的限制,有时候数值误差可能导致 Amm 不精确地保持对称性。
//通过将 Amm 更新为其本身与其转置的平均值,可以强制保持对称性,提高数值稳定性。这种对称性维护的策略在数值计算中比较常见。
Eigen::MatrixXd Amm = 0.5 * (A.block(0, 0, m, m) + A.block(0, 0, m, m).transpose());
Eigen::SelfAdjointEigenSolver<Eigen::MatrixXd> saes(Amm);//ROS_ASSERT_MSG(saes.eigenvalues().minCoeff() >= -1e-4, "min eigenvalue %f", saes.eigenvalues().minCoeff());//marg的矩阵块求逆,特征值分解求逆更快
Eigen::MatrixXd Amm_inv = saes.eigenvectors()* Eigen::VectorXd((saes.eigenvalues().array() > eps).select(saes.eigenvalues().array().inverse(), 0)).asDiagonal()* saes.eigenvectors().transpose();
GPT3.5:
- Amm 的逆矩阵是通过特征值分解(Eigenvalue Decomposition)来求解的。特征值分解将对称矩阵 Amm 分解为其特征向量和特征值的乘积,即 Amm = V * D * V^T,其中 V 是特征向量矩阵,D 是特征值对角矩阵。这样,逆矩阵可以用特征值的倒数替换特征值,然后再乘以特征向量的转置。
- 特别地,这里使用了 Eigen::SelfAdjointEigenSolver,它是专门用于对称矩阵的特征值分解的 Eigen 类。它返回特征值和特征向量,这样就能够轻松地进行逆矩阵的计算。
- 为什么使用特征值分解来加速求逆的过程呢?特征值分解后的矩阵形式是对角矩阵,其逆矩阵可以直接通过将对角元素取倒数得到。这个过程相较于直接对原始矩阵进行逆运算,更为高效,尤其是对于大规模矩阵。
其中最难理解的这一句
Eigen::VectorXd((saes.eigenvalues().array() > eps).select(saes.eigenvalues().array().inverse(), 0)).asDiagonal()
- saes.eigenvalues().array() > eps:首先,对 saes 对象中的特征值数组执行逐元素比较,生成一个布尔类型的数组,其中对应位置的元素为 true 表示对应的特征值大于 eps,否则为 false。
- .select(saes.eigenvalues().array().inverse(), 0):接下来,使用 select 函数,根据上一步生成的布尔数组,在大于 eps 的位置选择对应的特征值的倒数,否则选择 0。这样,小于等于 eps 的特征值都被替换为 0。
- Eigen::VectorXd(…):将上一步生成的数组转换为 Eigen 库中的列向量。
- .asDiagonal():将列向量转换为对角矩阵,其中对角线上的元素为列向量中的元素,其他位置为零。
根据之前博客marg部分线性化点的讨论,我们假设marg时线性化点为 x 0 x_0 x0,我们此时可以从J和residual中求解出 x 0 x_0 x0出对应的Jacobian和residual:

反解方法:
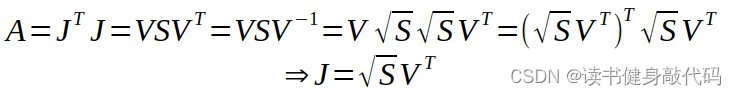
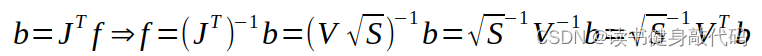
对应代码:
//由于Ceres里面不能直接操作信息矩阵,所以这里从信息矩阵中反解出来了Jacobian和residual,而g2o是可以的,ceres里只需要维护H和b
Eigen::SelfAdjointEigenSolver<Eigen::MatrixXd> saes2(A);
//对称阵
Eigen::VectorXd S = Eigen::VectorXd((saes2.eigenvalues().array() > eps).select(saes2.eigenvalues().array(), 0));
//对称阵的倒数阵
Eigen::VectorXd S_inv = Eigen::VectorXd((saes2.eigenvalues().array() > eps).select(saes2.eigenvalues().array().inverse(), 0));Eigen::VectorXd S_sqrt = S.cwiseSqrt();//开根号
Eigen::VectorXd S_inv_sqrt = S_inv.cwiseSqrt();//从H和b中反解出Jacobian和residual
linearized_jacobians = S_sqrt.asDiagonal() * saes2.eigenvectors().transpose();
linearized_residuals = S_inv_sqrt.asDiagonal() * saes2.eigenvectors().transpose() * b;
注意,marg和优化求解不同,marg只需要求出marg之后的信息矩阵即可(这里从信息矩阵中反解出了J和b),无需求解出 Δ x \Delta x Δx,也即不用求出当前的线性化点,而优化求解是需要求解出整个 Δ x \Delta x Δx,进而使用类似于LM的 ρ \rho ρ的评估标准来评估这次迭代求解的,这两个操作的目的不同。
6. addr_shift 内存管理
关于addr_shift的理解
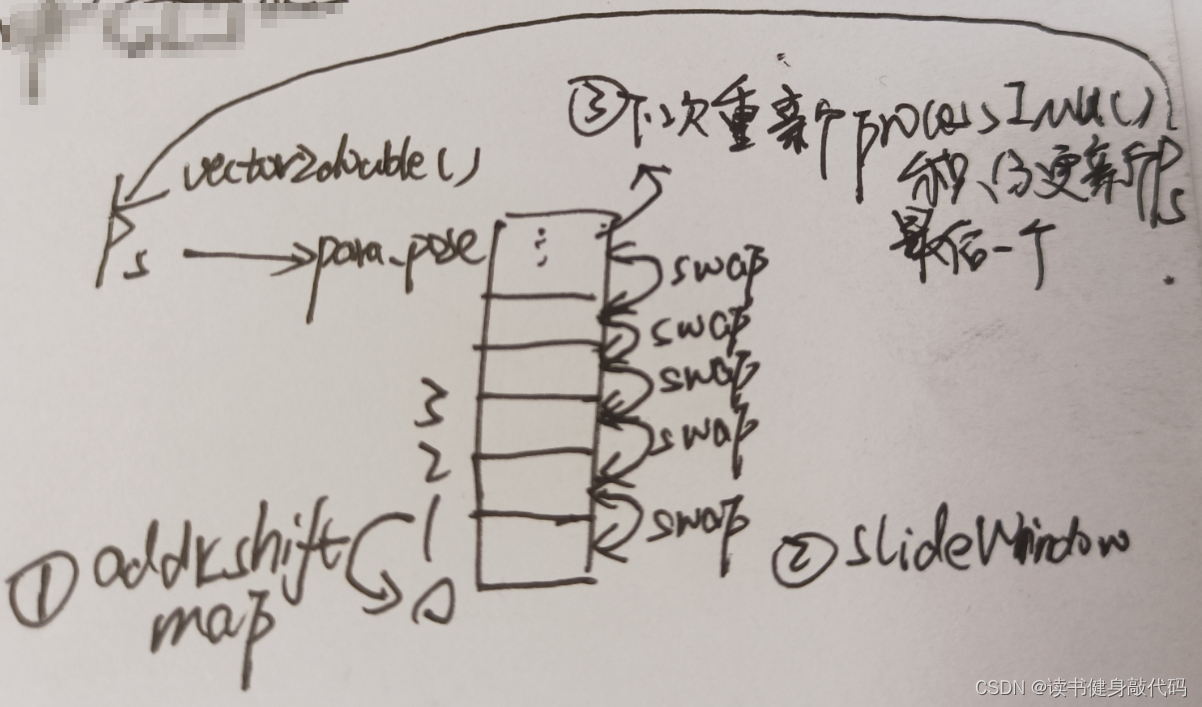
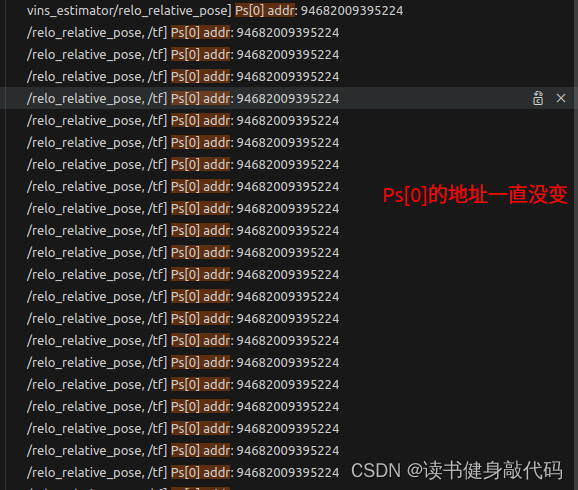
而addr_shift的意义就在于让系统优化的变量的起始地址不变,如果有新的landmark加入则会使整个parameter block所占的内存增大一点,但是整块内存的首地址是不变的,这样避免了因不断marg而导致的待优化变量的地址改变,进而导致地不断delete旧内存和new新内存,可以在求解后的slideWindow后加上一句打印:
ROS_DEBUG("Ps[0] addr: %ld", reinterpret_cast<long>(&Ps[0]));
-
地址操作完成之后,
getParameterBlocks(addr_shift)整理本次marg结果,放在keep_xxx中。 -
将本次marg结果传递,下次循环之后再
optimization函数中就会将本次marg结果应用到整个系统的ResidualBlock中,如此optimize,marg,optimize循环
last_marginalization_info = marginalization_info;
last_marginalization_parameter_blocks = parameter_blocks;
7. slideWindow
7.1 整体代码
根据之前KF selection的结果来执行不同的marg操作:
MARGIN_OLD则将old(即WINDOW[0])冒泡到最右侧(即WINDOW[WINDOW_SIZE]),删掉其预积分,并将all_image_frame内第[0]帧到old所在帧范围内(含)的所有frame删掉。对于old帧,还应将该帧下的landmark深度值向后传递。MARGIN_SECOND_NEW则2nd继承1st的IMU预积分,并初始化1st的预积分,all_image_frame不变
这部分之前在第3篇的2.2.3.7小结debug过一次,all_image_frame在长时间没遇到KF时确实会存在buffer很多帧图像的情况。
代码和注释:
//滑窗之后,WINDOW的最后两个Ps,Vs,Rs,Bas,Bgs相同,无论是old还是new,
//因为后面预积分要用最新的预积分初值,所以为了保证窗口内有11个观测,使最后两个相同
void Estimator::slideWindow()
{TicToc t_margin;//把最老的帧冒泡移到最右边,然后delete掉,在new一个新的对象出来if (marginalization_flag == MARGIN_OLD){double t_0 = Headers[0].stamp.toSec();back_R0 = Rs[0];back_P0 = Ps[0];if (frame_count == WINDOW_SIZE){for (int i = 0; i < WINDOW_SIZE; i++)//循环完成也就冒泡完成到最右侧{Rs[i].swap(Rs[i + 1]);//世界系下old冒泡std::swap(pre_integrations[i], pre_integrations[i + 1]);//每一帧的预积分old冒泡dt_buf[i].swap(dt_buf[i + 1]);//各种buf也冒泡linear_acceleration_buf[i].swap(linear_acceleration_buf[i + 1]);angular_velocity_buf[i].swap(angular_velocity_buf[i + 1]);Headers[i] = Headers[i + 1];//最后一个是 Headers[WINDOW_SIZE-1] = Headers[WINDOW_SIZE]Ps[i].swap(Ps[i + 1]);Vs[i].swap(Vs[i + 1]);Bas[i].swap(Bas[i + 1]);Bgs[i].swap(Bgs[i + 1]);}//这一步是为了 new IntegrationBase时传入最新的预积分的初值acc_0, gyr_0,ba,bg,所以必须要强制等于最新的Headers[WINDOW_SIZE] = Headers[WINDOW_SIZE - 1];Ps[WINDOW_SIZE] = Ps[WINDOW_SIZE - 1];Vs[WINDOW_SIZE] = Vs[WINDOW_SIZE - 1];Rs[WINDOW_SIZE] = Rs[WINDOW_SIZE - 1];Bas[WINDOW_SIZE] = Bas[WINDOW_SIZE - 1];Bgs[WINDOW_SIZE] = Bgs[WINDOW_SIZE - 1];//冒泡到最右边之后把对应的都delete&new或者clear掉delete pre_integrations[WINDOW_SIZE];//delete掉,并new新的预积分对象出来pre_integrations[WINDOW_SIZE] = new IntegrationBase{acc_0, gyr_0, Bas[WINDOW_SIZE], Bgs[WINDOW_SIZE]};dt_buf[WINDOW_SIZE].clear();linear_acceleration_buf[WINDOW_SIZE].clear();angular_velocity_buf[WINDOW_SIZE].clear();
// ROS_DEBUG("marg_flag: %d, before marg, all_image_frame.size(): %lu, WINDOW_SIZE: %d",
// marginalization_flag, all_image_frame.size(), WINDOW_SIZE);if (true || solver_flag == INITIAL){map<double, ImageFrame>::iterator it_0;it_0 = all_image_frame.find(t_0);//t_0是最老帧的时间戳,marg_old时删掉了帧,但是marg2nd的时候没有动,但是在process时候加进来了,说明all_image_frame应该是在增长的delete it_0->second.pre_integration;it_0->second.pre_integration = nullptr;for (map<double, ImageFrame>::iterator it = all_image_frame.begin(); it != it_0; ++it){if (it->second.pre_integration)delete it->second.pre_integration;it->second.pre_integration = NULL;}all_image_frame.erase(all_image_frame.begin(), it_0);//erase掉从开始到被marg掉的old之间所有的帧[begin(), it_0)all_image_frame.erase(t_0);//erase掉old帧}slideWindowOld();//求prior,删除某些变量
// ROS_DEBUG("marg_flag: %d, after marg, all_image_frame.size(): %lu, WINDOW_SIZE: %d",
// marginalization_flag, all_image_frame.size(), WINDOW_SIZE);}}//如果2nd不是KF则直接扔掉1st的visual测量,并在2nd基础上对1st的IMU进行预积分,window前面的都不动else{if (frame_count == WINDOW_SIZE){
// ROS_DEBUG("marg_flag: %d, before marg, all_image_frame.size(): %lu, WINDOW_SIZE: %d",
// marginalization_flag, all_image_frame.size(), WINDOW_SIZE);for (unsigned int i = 0; i < dt_buf[frame_count].size(); i++)//对最新帧的img对应的imu数据进行循环{double tmp_dt = dt_buf[frame_count][i];Vector3d tmp_linear_acceleration = linear_acceleration_buf[frame_count][i];Vector3d tmp_angular_velocity = angular_velocity_buf[frame_count][i];pre_integrations[frame_count - 1]->push_back(tmp_dt, tmp_linear_acceleration, tmp_angular_velocity);//2nd对1st进行IMU预积分//imu数据保存,相当于一个较长的KF,eg:// |-|-|-|-|-----|// ↑// 这段img为1st时,2nd不是KF,扔掉了这个1st的img,但buf了IMU数据,所以这段imu数据较长dt_buf[frame_count - 1].push_back(tmp_dt);linear_acceleration_buf[frame_count - 1].push_back(tmp_linear_acceleration);angular_velocity_buf[frame_count - 1].push_back(tmp_angular_velocity);}//相对世界系的预积分需要继承过来Headers[frame_count - 1] = Headers[frame_count];Ps[frame_count - 1] = Ps[frame_count];Vs[frame_count - 1] = Vs[frame_count];Rs[frame_count - 1] = Rs[frame_count];Bas[frame_count - 1] = Bas[frame_count];Bgs[frame_count - 1] = Bgs[frame_count];delete pre_integrations[WINDOW_SIZE];pre_integrations[WINDOW_SIZE] = new IntegrationBase{acc_0, gyr_0, Bas[WINDOW_SIZE], Bgs[WINDOW_SIZE]};dt_buf[WINDOW_SIZE].clear();linear_acceleration_buf[WINDOW_SIZE].clear();angular_velocity_buf[WINDOW_SIZE].clear();slideWindowNew();
// ROS_DEBUG("marg_flag: %d, after marg, all_image_frame.size(): %lu, WINDOW_SIZE: %d",
// marginalization_flag, all_image_frame.size(), WINDOW_SIZE);}}
}
7.2 slideWindowOld(理解marg视觉观测、三角化、绑定深度)
其中,在marg_old时VINS-MONO并未在每次marg时删除第[0]帧看到的所有landmark,当该feature只被[0]观测到时才会删除该feature,有些博客没有说清楚,会产生误解。
下图可见在第1次和第21次removeBackShiftDepth结束时仍有之前tracking到的feature
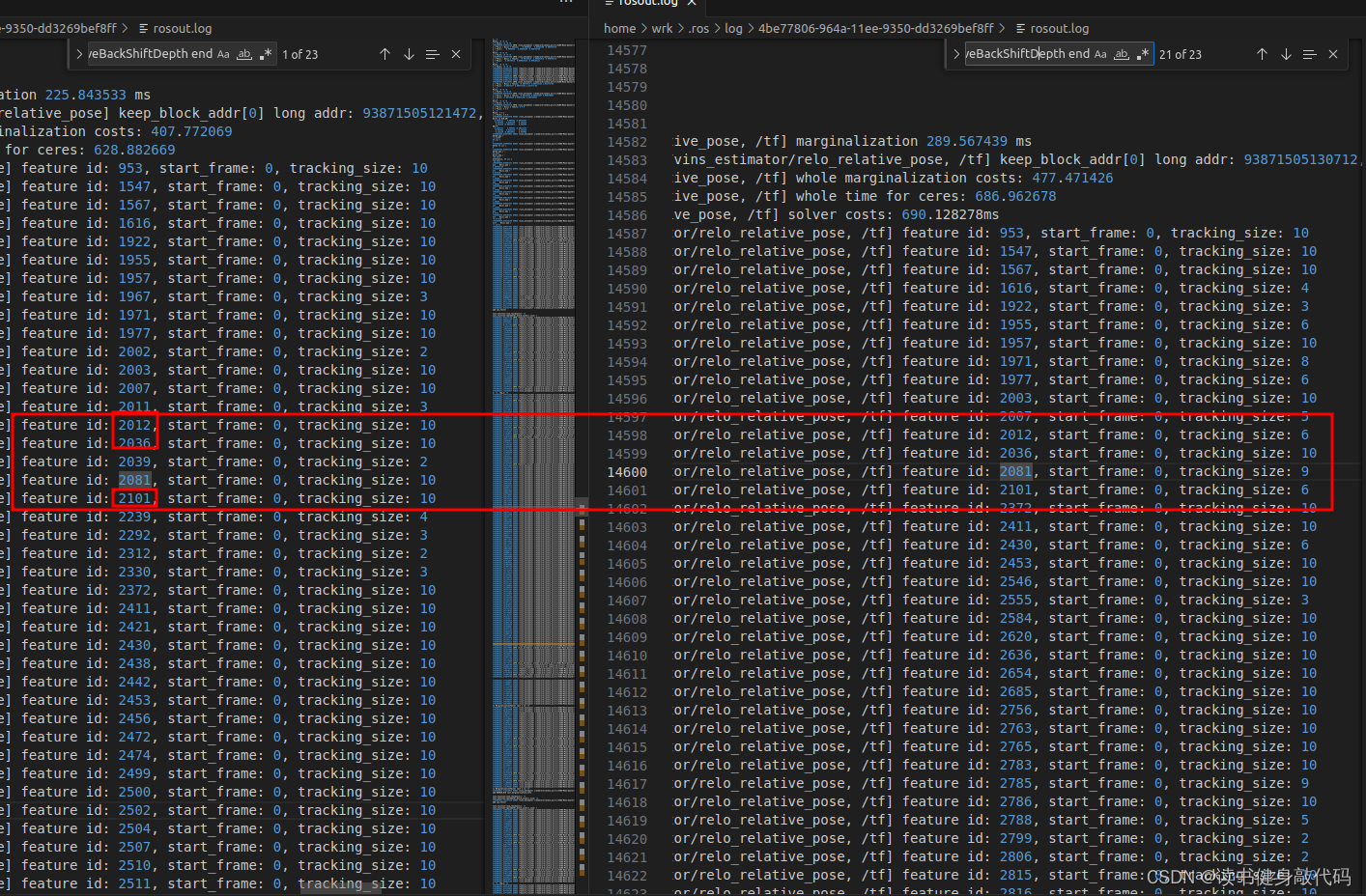
下图表明VINS-MONO并未删除始于第[0]帧看到的所有landmark,仅仅是当只在[0]有一次tracking时才会删除:
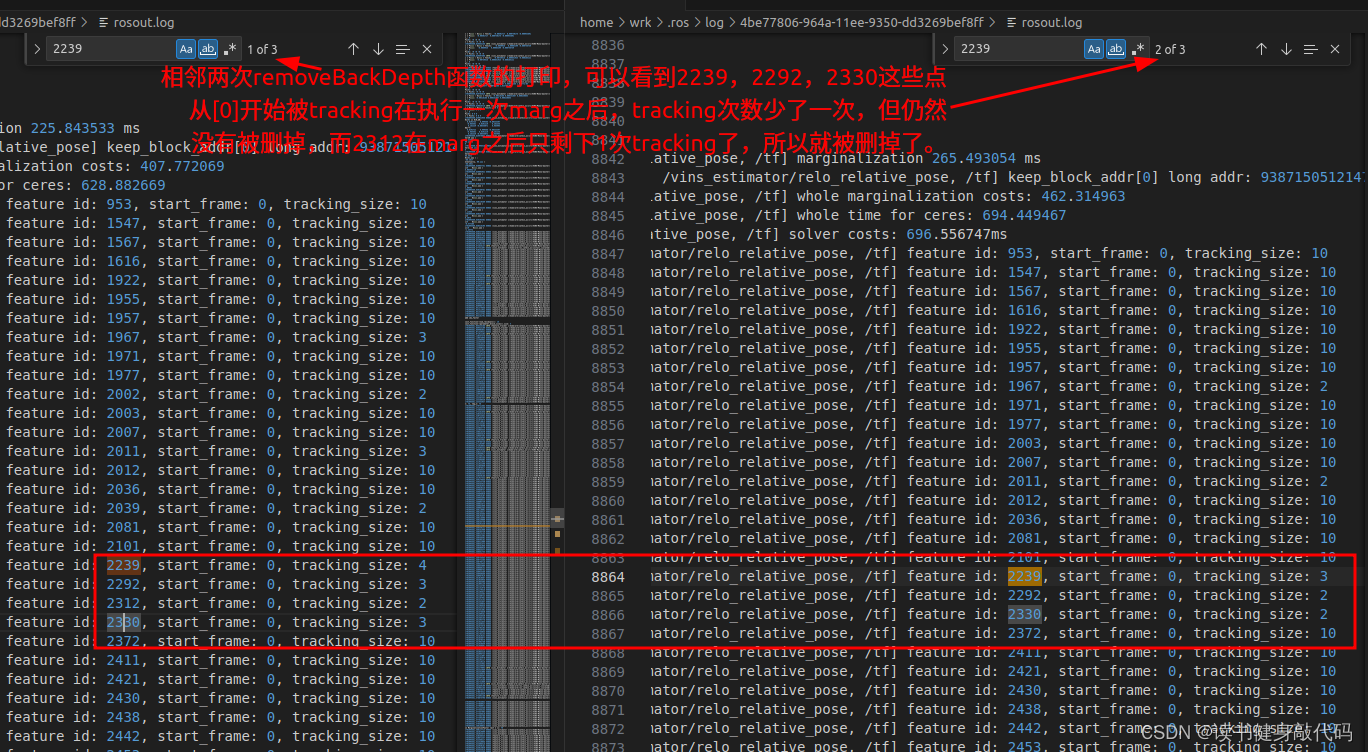
除了删除[0]的观测,还应该处理[0]作为start_frame该帧对应的camera系上绑定的深度,将其传递到后面的帧中,原因是该landmark的深度绑定在start_frame上,具体解释见上一篇博客的2.4.3.1节。
degbu代码:
//由于三角化出的camera系下的深度都绑定在start_frame上,所以当marg掉start_frame时,要将深度传递给后面的帧,这里绑定在了start_frame下一帧
void FeatureManager::removeBackShiftDepth(Eigen::Matrix3d marg_R, Eigen::Vector3d marg_P, Eigen::Matrix3d new_R, Eigen::Vector3d new_P)
{for (auto it = feature.begin(), it_next = feature.begin();it != feature.end(); it = it_next){it_next++;//不始于第[0]帧的landmark的start_frame前移,//始于第[0]帧的landmark,1.如果只在[0]tracking,则直接删掉(因为仅1帧算不出深度),2.如果tracking多于1帧,则将深度传递给start_frame+1帧//管理marg之后的start_frame,要往前移1if (it->start_frame != 0)it->start_frame--;else{Eigen::Vector3d uv_i = it->feature_per_frame[0].point; it->feature_per_frame.erase(it->feature_per_frame.begin());if (it->feature_per_frame.size() < 2){feature.erase(it);continue;}else{Eigen::Vector3d pts_i = uv_i * it->estimated_depth;//归一化->camera_margEigen::Vector3d w_pts_i = marg_R * pts_i + marg_P;//Twc_marg * camera = worldEigen::Vector3d pts_j = new_R.transpose() * (w_pts_i - new_P);//Twc_new^(-1) * world=camera_newdouble dep_j = pts_j(2);if (dep_j > 0)it->estimated_depth = dep_j;elseit->estimated_depth = INIT_DEPTH;}ROS_DEBUG("feature id: %d, start_frame: %d, tracking_size: %lu",it->feature_id, it->start_frame, it->feature_per_frame.size());}// remove tracking-lost feature after marginalize/*if (it->endFrame() < WINDOW_SIZE - 1){feature.erase(it);}*/}ROS_DEBUG("this removeBackShiftDepth end");
}
7.3 slideWindowNew
这部分属于MARGIN_SECOND_NEW的内容,MARGIN_SECOND_NEW中只marg掉了此时先验中关于2nd的视觉pose,连2nd对landmark的观测都没有向后传递info,这部分观测在slideWindow()中直接丢掉了。
optimization()中关于MARGIN_SECOND_NEW部分挑选drop_set的部分,只filter出了2nd的pose,没有视觉的factor:
//只drop掉2nd的视觉pose(IMU部分是在slideWindow内继承和delete的)
vector<int> drop_set;
for (int i = 0; i < static_cast<int>(last_marginalization_parameter_blocks.size()); i++)
{ROS_ASSERT(last_marginalization_parameter_blocks[i] != para_SpeedBias[WINDOW_SIZE - 1]);if (last_marginalization_parameter_blocks[i] == para_Pose[WINDOW_SIZE - 1])drop_set.push_back(i);
}
在slideWindow()中直接丢掉了,而这样做的理论依据是认为2nd和1st非常相似,所以对IMU直接继承预积分,对视觉pose直接丢弃,以下是崔华坤的解释:

8. 总结
本文主要讲解了VINS-MONO中的marginalization,marg的目的是为了维护我们优化问题的复杂度在一定的范围内,在新变量进来之前要把旧变量剔除出去,同时要保留旧变量对剩余变量的约束信息。
VINS-MONO有两种marg策略:
- 2nd为KF,则marg old;
- 2nd非KF,则marg 2nd的pose,并继承IMU积分。
保留marg变量的核心方法是Schur Compliment,原理方面,涉及到了:
- marg landmark的理解(marglandmark观测而非直接marg整个路标点);
- 先验误差 e p e_p ep的更新;
- 先验Jacobian不变带来的问题;
- 鲁棒核函数如何对residual和Jacobian使用;
- 三角化输出深度的理解(绑定在start_frame上);
- 整个系统Jacobian和information matrix理解。
编程方面,涉及到了:
- map地址映射;
- 内存管理;
- 多线程;
- 提高double类型矩阵的数值稳定性;
- SVD分解加速矩阵求逆过程(求助GPT)。
水平有限,如有纰漏,欢迎指正。
接下来是pose_graph部分。
这篇关于VINS-MONO代码解读5----vins_estimator(marginalization部分)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






