本文主要是介绍【Task01】Datawhale202205组队学习 吃瓜教程 机器学习西瓜书+南瓜书,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【Task01】Datawhale202205组队学习 吃瓜教程 机器学习西瓜书+南瓜书
概览西瓜书+南瓜书第1、2章
学习建议:概览西瓜书第1章和第2章的基本概念和术语,跳过以下内容:
第1章:【1.4-归纳偏好】可以跳过
第2章:【2.3.3-ROC与AUC】及其以后的都可以跳过
目录
- 西瓜书勘误(转)
- 第1章 绪论
- 1.1 引言
- 1.2 基本术语
- 1.3 假设空间
- 1.4 归纳偏好
- 1.5 发展历程
- 1.6 应用现状
- 1.7 阅读材料
- 第2章 模型评估与选择
- 2.1 经验误差与过拟合
- 2.2 评估方法
- 2.2.1 留出法
- 2.2.1 交叉验证法
- 2.2.3 自助法
- 2.2.4 调参与最终模型
- 2.3 性能度量
- 2.3.1 错误率与精度
- 2.3.2 查准率、查全率与*F*1
- 2.3.3 ROC与AUC
- 2.3.4 代价敏感错误率与代价曲线
- 2.4 比较检验
- 2.4.1 假设检验
- 2.4.2 交叉验证t 检验
- 2.4.3 McNemar 检验
- 2.4.4 Friedman 检验与Nemnenyi 后续检验
- 2.5 偏差与方差
- 2.6 阅读材料
西瓜书勘误(转)
一版第1次印刷, 2016年1月):
p.6, 图1.2: 图中两处"清脆" --> “浊响”
p.28, 第3段倒数第2行: “大量” --> “不少”
p.28, 边注: “例如 ……上百亿个参数” --> “机器学习常涉及两类参数: 一类是算法的参数, 亦称"超参数”, 数目常在10以内; 另一类是模型的参数, 数目可能很多, 例如……上百亿个参数. 两者调参方式相似, 均是产生多个模型之后基于某种评估方法来进行选择; 不同之处在于前者通常是由人工设定多个参数候选值后产生模型, 后者则是通过学习来产生多个候选模型(例如神经网络在不同轮数停止训练)."
p.31, 倒数第3行: “Event” --> “Even”
p.256, 第4段: “固定住 α i {\bf \alpha}_i αi” --> “以 α i {\bf \alpha}_i αi为初值”
p.256, 最后一段第1行: “ E i = {\bf E}_i = Ei=” --> “${\bf E}i = {\bf X} - " p . 385 , 式 ( 16.25 ) 和 ( 16.26 ) : 两 处 " " p.385, 式(16.25)和(16.26): 两处" "p.385,式(16.25)和(16.26):两处"r_i " − − > " " --> " "−−>"R_i " p . 385 , 式 ( 16.25 ) 下 一 行 : " 若 改 用 … … " − − > " 其 中 " p.385, 式(16.25)下一行: "若改用……" --> "其中 "p.385,式(16.25)下一行:"若改用……"−−>"其中R_i 表 示 第 表示第 表示第i 条 轨 迹 上 自 状 态 条轨迹上自状态 条轨迹上自状态x 至 结 束 的 累 积 奖 赏 . 若 改 用 … … " p . 386 , 式 ( 16.28 ) 下 一 行 : " 始 终 为 1 " − − > " 对 于 至结束的累积奖赏. 若改用……" p.386, 式(16.28)下一行: "始终为1" --> "对于 至结束的累积奖赏.若改用……"p.386,式(16.28)下一行:"始终为1"−−>"对于a_i=\pi(x_i) 始 终 为 1 " p . 386 , 图 16.11 , 第 4 步 : 两 处 " 始终为1" p.386, 图16.11, 第4步: 两处 " 始终为1"p.386,图16.11,第4步:两处"\pi(x) " − − > " " --> " "−−>"\pi(x_i) " p . 386 , 图 16.11 , 第 6 步 的 式 子 − − > " " p.386, 图16.11, 第6步的式子 --> " "p.386,图16.11,第6步的式子−−>"R=\frac{1}{T-t}\left(\sum{i=t+1}^T r_i\right) \prod_{i=t+1}^{T-1} \frac{\mathbb I(a_i=\pi(x_i))}{p_i}$”
p.386, 图16.11, 边注"计算修正的累积奖赏." --> “计算修正的累积奖赏. 连乘内下标大于上标的项取值为1.”; 去掉边注"重要性采样系数."
第1章 绪论
1.1 引言
机器学习:计算机、经验
机器学习所研究的主要内容:在计算机上从数据中产生"模
型" (model) 的算法,即"学习算法" (learning algorithm).
模型
模式
1.2 基本术语
1、数据集 (data set)
2、示例 (instance) 或样
本 (sample) 事件或对象
3、属性 (attribute) 或特征 (feature) 属性值(attribute value)
4、属性空间 (attribute space) 、样本空间 (sample space)或输入
空间
5、特征向量(feature vector)
…维数、学习、训练、训练数据、训练样本、训练集、假设、真相、学习器、预测、标记、样例、标记空间、分类、回归、测试、聚类、监督学习、无监督学习(是否有标记信息)、泛化、分布、独立同分布
1.3 假设空间
归纳与演绎
归纳学习 概念学习 布尔概念学习 布尔表达式 版本空间
1.4 归纳偏好
暂时不看
1.5 发展历程
推理期、知识期、学习期
1.6 应用现状
大数据时代的三大关键技术:
机器学习:数据分析
云计算:数据处理
众包(crowdsourcing):数据记忆
数据挖掘
自动驾驶方面:
1、著名机器学习教科书[Mitchell. 1997]4.2 节介绍了二十世纪九十年代早期利用神经网络学习来控制自动驾驶车的ALVINN系统
2、抽象机器学习任务:
输入:车载传感器接收到的信息
输出:转向、制动、加减速控制
3、美国DARPA挑战赛
DARPA 的全称是美国国防部先进研究计划局,互联网、全球卫星定位系统等都源于DARPA 启动的研究项目
4、2011 年6 月,美国内华达州议会通过法案,成为美国第一个认可自动驾驶车的州,此后,夏威夷州和佛罗里达州也先后通过类似法案
1.7 阅读材料
书、网站、会议、期刊
第2章 模型评估与选择
2.1 经验误差与过拟合
错误率E= a/m
精度=(1-a/m)X100%
误差 (error) 训练误差 (training error)或经验误差 (empirical error) ,在新样本上的误差称为泛化误差 (generalization error)
希望得到:在新样本上表现很好的学习器,而不是训练集
(反过来可能会导致…)
当学习器把训练样本学得"太好"了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降这种现象在机器学习中称为"过拟合" (overfitting). 与"过拟合"相对的是"欠拟合" (underfitting) ,这
是指对训练样本的一般性质尚未学好

学习能力过于强大可能导致过拟合(关键障碍),相反,欠拟合(较容易克服)
过拟合是无法彻底避免的
“模型选择” (model selection) 问题
理想解决方案:对候选模型的泛化误差进行评估,然后选择泛化误差最小的模型
2.2 评估方法
可通过实验测试来对学习器的泛化误差进行评估并进而做出选择
使用一个"测试集" (testing set)来测试学习器对新样本的判别能力,然后以测试集上的"测试误差" (testing error)作为泛化误差的近似
测试样本需要满足条件,尽可能不出现在训练集中(举一反三)
方法:对数据集D进行处理,产生训练集S和训练集T
2.2.1 留出法
训练/测试集的划分要尽可能保持数据分布的一致性,避免困数据划分过程引入额外的偏差而对最终结果产生影响
单次使用留出法得到的估计结果往往不够稳定可靠,在使用留出法时,一般要采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果
留出法的窘境:常见做法是将大约2/3 ~ 4/5 的样本用于训练,剩余样本用于测试
一般而言,测试集至少应含30 个样例[Mitchell,1997]
2.2.1 交叉验证法
k 折交叉验证(k倍交叉验证) k=5,10.20等
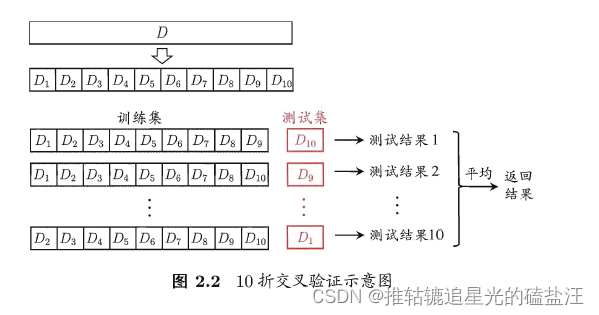
k 折交叉验证通常要随机使用不同的划分重复p 次,最终的评估结果是这p 次k 折交叉验证结果的均值,常见的有"10 次10 折交叉验证”
**留一法(Leave-One-Out,简称LOO) **
2.2.3 自助法
自助采样法(bootstrap sampling)
“包外估计” (out-of-bag estimate).
比较:
自助法在数据集较小、难以有效划分训练/测试集时很有用;此外,自助法能从初始数据集中产生多个不同的训练集,这对集成学习等方法有很大的好处。然而,自助法产生的数据集改变了初始数据集的分布,这会引入估计偏差。因此,在初始数据量足够时,留出法和交叉验证法更常用一些。
2.2.4 调参与最终模型
调参 (parameter tuning)
2.3 性能度量
性能度量(performance measure):对学习器的泛化性能进行评估
2.3.1 错误率与精度
错误率和精度是分类任务中最常用的两种性能度量,既适用于二分类任务,也适用于多分类任务
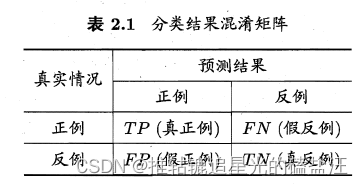
2.3.2 查准率、查全率与F1
查准率(precision)、查全率(recall):一对矛盾的度量

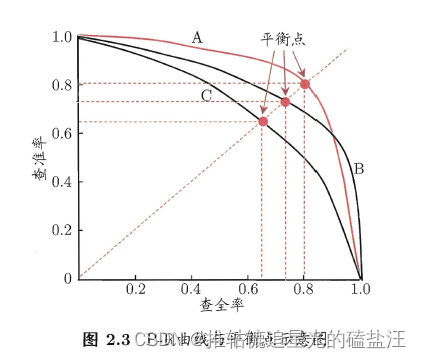
“平衡点” (Break-Even Point,简称BEP)

“微查准率”(micro-P) 、“徽查全率” (micro-R)和"微F1" (micro-F1)
2.3.3 ROC与AUC
2.3.4 代价敏感错误率与代价曲线
2.4 比较检验
2.4.1 假设检验
2.4.2 交叉验证t 检验
2.4.3 McNemar 检验
2.4.4 Friedman 检验与Nemnenyi 后续检验
2.5 偏差与方差
2.6 阅读材料
暂时不看
这篇关于【Task01】Datawhale202205组队学习 吃瓜教程 机器学习西瓜书+南瓜书的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






