本文主要是介绍智谱清华LongAlign发布:重塑NLP长文本处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
随着大型语言模型(LLMs)的不断进化,我们现在能够处理的文本长度已经达到了前所未有的规模——从最初的几百个tokens到现在的128k tokens,相当于一本300页的书。这一进步为语义信息的提供、错误率的减少以及用户体验的提升打开了新的可能性。智谱技术团队与清华大学的最新合作成果——LongAlign模型,专注于长文本的精准对齐问题,不仅突破了长上下文处理的技术瓶颈,而且在数据集构建、训练策略及评估基准等方面都取得了重大进展。
-
Huggingface模型下载:https://huggingface.co/THUDM
-
AI快站模型免费加速下载:https://aifasthub.com/models/THUDM

LongAlign模型的创新
传统的长文本处理方法主要集中在扩展上下文长度上,如通过增强位置编码和长文本的持续训练来实现。然而,这些方法并未充分解决长文本对齐的精确性问题。LongAlign模型的核心创新在于它通过一个全面的框架来提高长文本的对齐质量,包括精心设计的数据集、高效的训练方法以及专门针对长文本对齐能力的评估基准。这种方法显著提高了模型在处理长文本时的准确性和效率。
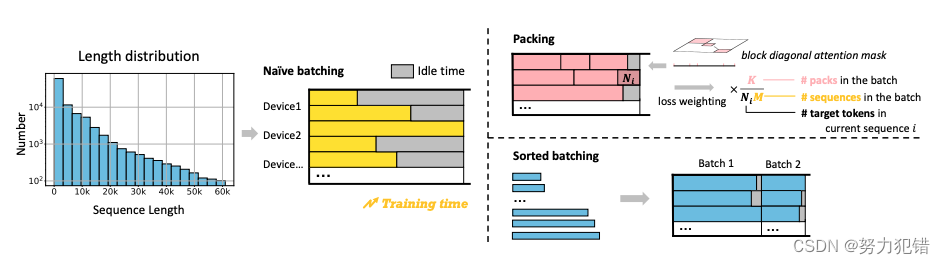
数据集和训练策略
在数据集方面,LongAlign首次尝试从书籍、百科、学术论文和代码等9个不同来源收集长篇文章和文件,并利用先进的语言模型生成与之匹配的任务和答案,成功创造了一个多样化且广泛的长指令数据集。训练策略方面,LongAlign引入了打包策略和排序批处理技术,不仅显著提高了模型的训练效率,还确保了模型在处理长短文本任务时的平衡能力。

评估基准和实验结果
LongAlign开发的评估基准LongBench-Chat,包含50个长上下文真实世界查询,涵盖了文档问答、摘要和编码等关键场景。实验结果表明,LongAlign在长上下文任务中显著优于现有方法,提升幅度高达30%,在短、通用任务中也没有表现出任何性能退化,证明了其在长文本处理方面的领先地位。
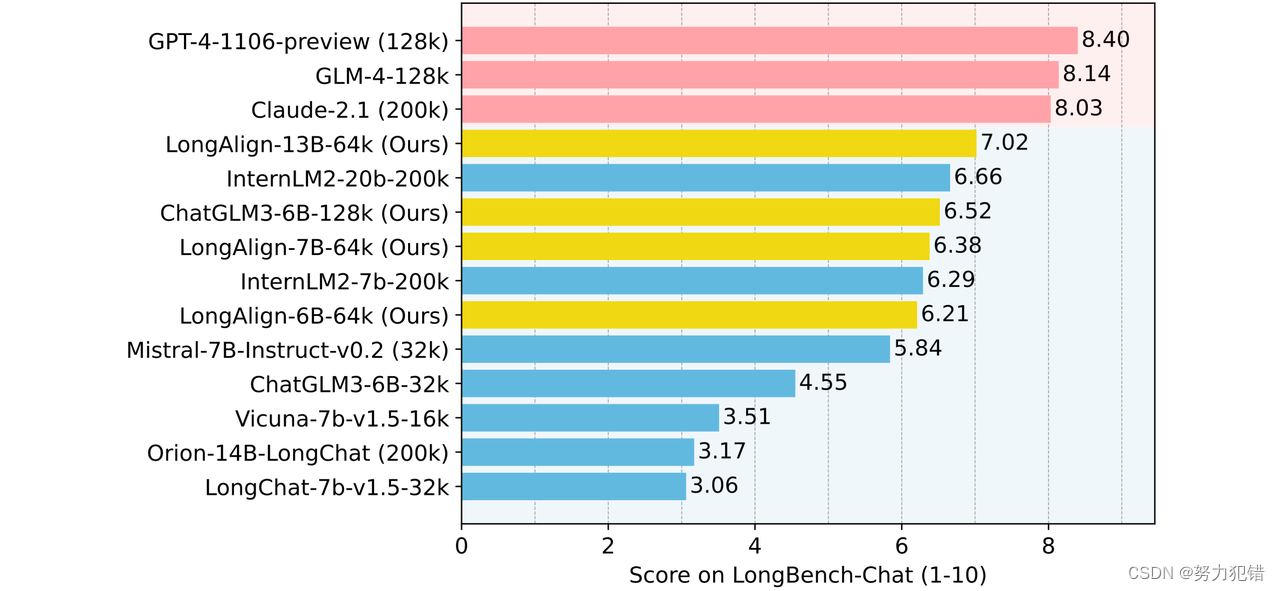
实际应用和未来展望
LongAlign模型的成功开发,为NLP领域带来了新的可能性,特别是在需要处理大量文本信息的领域,如电影制作、游戏开发、工业设计等。Looking forward,随着更大规模模型的开发和更长序列的上下文对齐技术的研究,LongAlign有望在自然语言处理和人机交互等更多领域发挥更大的作用。
结论
LongAlign模型的开发,标志着智谱技术团队和清华大学在长文本处理技术上取得的重大突破。通过其全面的方法,LongAlign不仅提升了长文本对齐的准确性和效率,也为NLP领域的未来发展提供了新的思路和工具。随着技术的不断进步,期待LongAlign在自然语言处理领域带来更多激动人心的应用和发展。
模型下载
Huggingface模型下载
https://huggingface.co/THUDM
AI快站模型免费加速下载
https://aifasthub.com/models/THUDM
这篇关于智谱清华LongAlign发布:重塑NLP长文本处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








