本文主要是介绍12. 建立用户表并使用雪花算法生成用户ID,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、建立用户表
- 二、雪花算法生成唯一ID
- 三、将雪花算法整合到我们的项目中
一、建立用户表
上一节我们搭建完了脚手架,从这一节开始,就正式进入到业务逻辑的开发了。首先要开发的就是博客系统的用户注册与登录功能。
既然涉及到用户,那么前提就是要有一张用户信息表。
在bluebell数据库下建立user表,并插入两条测试数据,如下:
create table user
(id bigint auto_increment primary key,user_id bigint not null,username varchar(64) not null,password varchar(64) not null,email varchar(64) null,gender tinyint default 0 not null,create_time timestamp default CURRENT_TIMESTAMP null,update_time timestamp default CURRENT_TIMESTAMP null on update CURRENT_TIMESTAMP,constraint idx_user_id unique (user_id),constraint idx_username unique (username)
) collate = utf8mb4_general_ci;INSERT INTO user (id, user_id, username, password, email, gender, create_time, update_time) VALUES (1, 28018727488323585, 'lym', '313233343536639a9119599647d841b1bef6ce5ea293', null, 0, '2024-03-09 07:01:03', '2024-03-09 07:01:03');
INSERT INTO user (id, user_id, username, password, email, gender, create_time, update_time) VALUES (2, 4183532125556736, '小明', '313233639a9119599647d841b1bef6ce5ea293', null, 0, '2024-03-09 13:03:51', '2024-03-09 13:03:51');select * from user;

二、雪花算法生成唯一ID
在分布式系统中,生成唯一的ID是一个核心问题,特别是在需要确保数据完整性和避免冲突的场景中,比如作为链路追踪的trace_id,作为幂等性的主键id, 分布式锁中为了避免释放的是别人的锁时,本地保存的唯一id等。此处的用户ID我们就需要保证唯一,因此选用了雪花算法。
之前写过一篇用Go生成唯一ID的文章:76.Go分布式ID总览
简介
雪花算法是Twitter开发的一种生成64位ID的服务,基于时间戳、节点ID和序列号。
实现原理
-
工作方式:结合时间戳、工作机器的
ID和序列号来生成64位的ID。时间戳保证了ID的唯一性和顺序性,工作机器ID保证了在多机环境下的唯一性。 -
时间戳:确保
ID按时间顺序增长。
优缺点
-
优点:
ID有时间顺序,长度适中,生成速度快。 -
缺点:对系统时钟有依赖,时钟回拨会导致ID冲突。(时钟回拨:服务器上的时间突然倒退回之前的时间。可能是人为的调整时间;也可能是服务器之间的时间校对。)
-
网络依赖性:通常无需网络交互,除非在多机器环境中同步机器
ID。
由于雪花算法工作中还是可能用到的,所以介绍更详细一些。
Snowflake的核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心(DC,机房)),5个bit的机器ID(也可能是容器id)),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是01。这样可以确保每个ID都是唯一的。

package mainimport("fmt""github.com/bwmarrin/snowflake"
)func main() {
// 参数为机器idnode, err := snowflake.NewNode(1)if err != nil {fmt.Println(err)return}id := node.Generate().String() // id: 1552614118060462080 length: 19fmt.Println("id:", id, "length:", len(id))
}
三、将雪花算法整合到我们的项目中
雪花算法可以指定开始时间,还需要一个机器ID,由于我们是练习项目,只部署了一台机器,所以可以直接配置机器id为1。
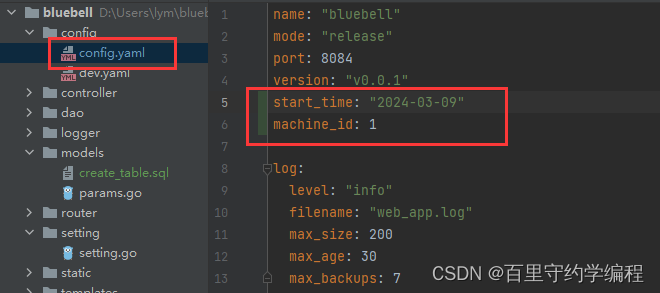
在config.yaml文件中加入开始时间和机器ID的配置
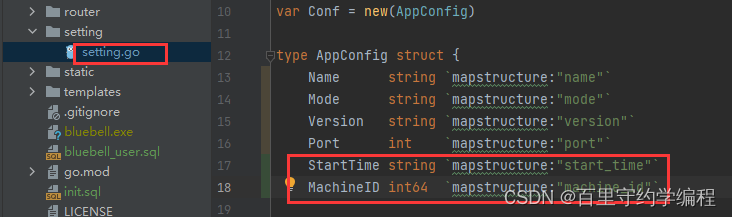
setting.go文件中的配置文件结构体也需要加上这两个字段啦
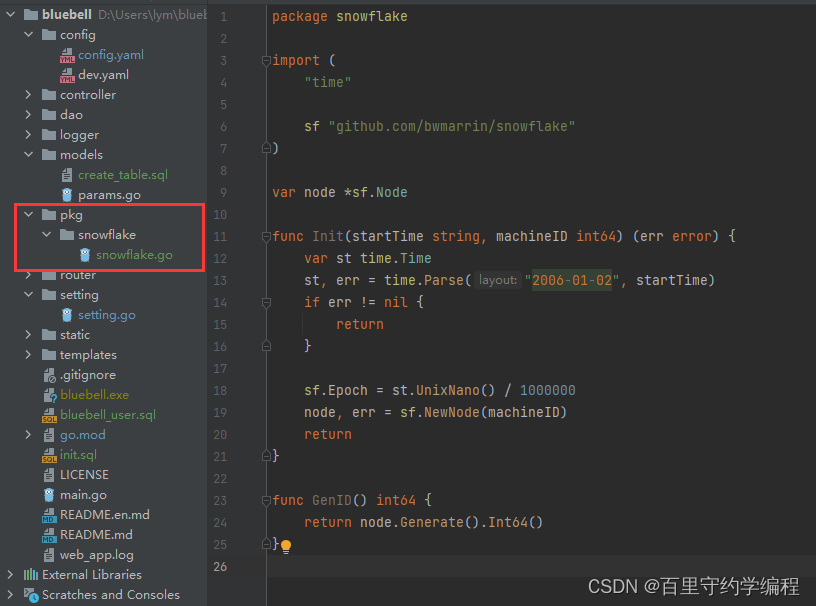
接着,我们可以将雪花算法生成用户id作为工具包,在需要使用的时候,直接调用GenID方法使用即可。
package snowflakeimport ("time"sf "github.com/bwmarrin/snowflake"
)var node *sf.Nodefunc Init(startTime string, machineID int64) (err error) {var st time.Timest, err = time.Parse("2006-01-02", startTime)if err != nil {return}sf.Epoch = st.UnixNano() / 1000000node, err = sf.NewNode(machineID)return
}func GenID() int64 {return node.Generate().Int64()
}
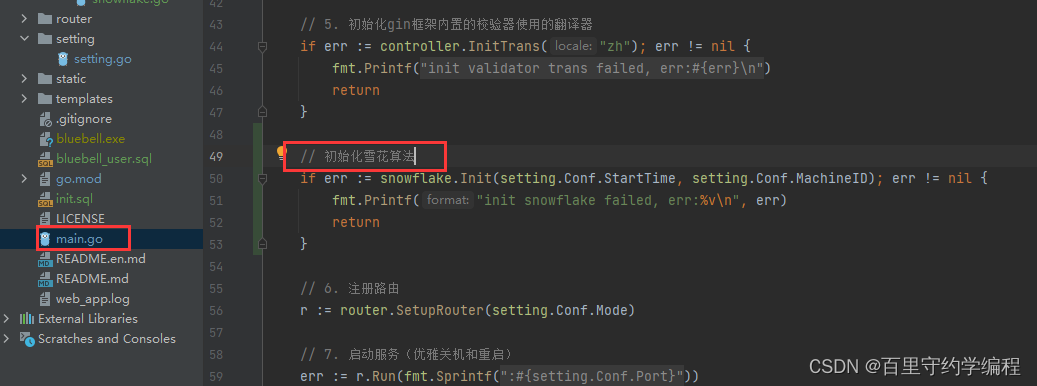
最后,我们需要在main.go文件中初始化雪花算法
这篇关于12. 建立用户表并使用雪花算法生成用户ID的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




