本文主要是介绍如何利用大模型对抗网络谣言,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、如何利用大模型对抗网络谣言
1.1 应用场景
1.1.2数字取证和司法鉴定:
在数字取证和司法鉴定领域,需要对图像和音频进行真伪鉴别。通过调用大模型端口,使用PyCharm等开发工具进行数据预处理和特征提取,利用知识图谱技术对检测结果进行可视化展示,可以帮助鉴定人员更加准确地判断图像和音频的真伪。
1.1.3安全监控:
在安全监控领域,需要识别视频监控中的真实和伪造的图像和音频。通过调用大模型端口,使用PyCharm等开发工具进行数据预处理和特征提取,利用知识图谱技术对检测结果进行可视化展示,可以帮助安全人员更加准确地发现伪造或篡改的图像和音频。
1.1.4艺术创作:
在艺术创作领域,需要对图像和音频进行真伪鉴别。通过调用大模型端口,使用PyCharm等开发工具进行数据预处理和特征提取,利用知识图谱技术对检测结果进行可视化展示,可以帮助艺术家更加准确地判断作品的真伪。
1.2 技术方案
1.2.1数据收集和处理:
收集真实的图像和音频以及伪造或篡改的图像和音频,使用PyCharm等开发工具进行数据清洗、预处理和增强,以提高模型的泛化能力。
1.2.2特征提取和表示学习:
利用PyCharm等开发工具编写特征提取算法,从图像和音频中提取出有用的特征,并利用表示学习技术将特征转化为高维空间的向量表示。
1.2.3调用大模型端口进行训练和优化:
使用PyCharm等开发工具构建与大模型端口通信的接口,将处理后的图像和音频特征输入到大模型端口,调用模型的分类预测功能,并使用监督学习的方法对模型进行训练和优化。
1.2.4后处理和可视化展示:
使用PyCharm等开发工具构建相应的后处理和可视化模块,将预测结果整理成知识图谱的形式,并使用图表、图形等形式展示检测结果以及各个特征对于分类的影响程度。
1.2.5模型部署和优化:
将训练好的大模型和应用程序部署到实际运行环境中,并根据实际运行情况和用户反馈对模型和应用程序进行优化和调整。
1.3核心技术
-
1.3.1大模型调用和集成:
- 了解现有大模型的架构和功能,能够正确地调用模型的API接口。
- 理解模型输入的格式和要求,能够将待检测的图像和音频数据转换为模型所需的输入格式。
- 掌握如何调整模型的参数,以优化模型的分类性能和准确性。
-
1.3.2特征提取和表示学习:
- 了解常见的特征提取方法和算法,例如HOG(Histogram of Oriented Gradients)、SIFT(Scale-Invariant Feature Transform)等。
- 能够根据不同的图像和音频数据选择合适的特征提取方法,并提取出有效的特征向量。
- 掌握表示学习技术,例如深度嵌入或卷积神经网络(CNN),将提取出的特征转化为高维空间的向量表示。
- 能够调整表示学习的参数,以优化特征的表示能力和分类性能。
-
1.3.3知识图谱技术:
- 了解知识图谱的基本概念和构建方法,能够构建相应的知识图谱模型。
- 掌握如何将检测结果整理成知识图谱的形式,例如使用实体、关系和属性等来表示检测结果。
- 能够使用图表、图形等形式展示知识图谱中的信息,例如展示不同实体之间的关系和属性。
-
1.3.4PyCharm等开发工具的应用:
- 熟悉PyCharm等开发工具的基本操作和常用功能,能够高效地进行编程和调试。
- 掌握常用的数据处理和分析方法,例如使用NumPy、Pandas等库进行数据处理和分析。
- 能够使用PyCharm等开发工具编写相应的特征提取算法和后处理代码,以实现高效的开发和调试过程。
-
1.3.5模型部署和优化:
- 掌握如何将训练好的大模型和应用程序部署到实际运行环境中。
- 能够根据实际运行情况和用户反馈对模型和应用程序进行优化和调整,例如调整模型的参数、使用不同的数据增强技术等。
- 了解常见的模型优化技术,例如正则化、Dropout、批量归一化等,能够使用这些技术提高模型的性能和准确性。
1.4大模型如何应用
我们可以学习亚马逊的Alexa的谣言对抗机制
1.4.1建立大规模语料库
为了训练有效的分类模型,首先我们可以建立一个大规模的语料库。这个语料库包括真实信息和谣言两类数据。从公开的新闻网站、社交媒体平台、论坛等收集真实信息,以及从已知的谣言网站、社区等收集谣言。
1.4.2训练分类模型:
一旦建立了大规模的语料库,我们就可以开始训练分类模型了。分类模型的作用是将新的信息分类为真实信息或谣言。可以使用多种机器学习算法进行训练,包括逻辑回归、朴素贝叶斯和支持向量机等。这些算法可以从语料库中学习到真实信息和谣言的特征,并用于对新信息的分类。
1.4.3优化模型以提高准确性:
为了提高分类模型的准确性,我们可以使用交叉验证技术来评估模型的性能。交叉验证技术是将原始数据分成多个部分,并使用其中的一部分数据进行训练,然后用另一部分数据测试模型的准确性。通过多次重复这个过程,可以获得更可靠的准确性评估。
1.4.4使用特征工程技术来提取更有效的特征
其次,可以使用特征工程技术来提取更有效的特征。特征工程是将原始数据转化为更有效的特征表示,以便机器学习算法更好地学习数据的特征。Alexa使用了一系列特征,包括词频、文本长度、URL结构等,来提高分类模型的准确性。
1.4.5使用超参数调整技术来优化模型的性能
最后,可以使用超参数调整技术来优化模型的性能。超参数是机器学习算法中需要手动设置的参数,如学习率、迭代次数等。通过调整这些参数,可以获得更好的模型性能。Alexa使用了自动化算法进行超参数调整,以获得最佳的模型性能。
1.4.6实时监测和预警:
一旦训练好了分类模型,我们就可以将其用于实时监测网络信息。当用户询问一个问题或输入一个URL时,Alexa会先使用分类模型对该信息进行分类。如果分类结果为谣言,Alexa会拒绝回答或提供辟谣信息,同时向用户发出预警。
总之,Alexa的谣言对抗机制是通过建立大规模语料库、训练分类模型、优化模型以提高准确性、实时监测和预警等多种策略和方法来实现的。这些方法可以帮助用户更好地识别和避免谣言,同时也可以提高Alexa的智能性和实用性。
1.5实验过程中大模型的应用:
- 调用大模型端口:首先,你需要获取并调用一个现有的大模型端口。这个模型应该已经被训练并优化,以用于图像或音频的真伪分类任务。通常,这个模型会提供一个API接口,你可以通过这个接口输入待检测的图像或音频数据,并获取分类预测结果。
- 数据预处理:在调用大模型端口之前,需要对输入的图像或音频数据进行预处理。预处理包括数据清洗、标准化、尺寸调整等步骤,以确保输入数据的质量和一致性。可以使用PyCharm等开发工具进行数据预处理编程和调试。
- 特征提取:在数据预处理之后,需要从图像或音频中提取出有用的特征。这些特征可以包括颜色、纹理、形状等对于图像,以及音调、音色、节奏等对于音频。可以使用PyCharm等开发工具编写相应的特征提取算法和代码。
- 调用大模型端口进行分类预测:将提取出的特征输入到大模型端口,调用模型的分类预测功能。根据模型的输出结果,可以判断图像或音频的真伪。
- 后处理和可视化展示:根据需要,可以进行进一步的后处理和可视化展示。例如,可以将预测结果整理成知识图谱的形式,以方便用户理解和分析。可以使用PyCharm等开发工具构建相应的应用程序或接口,以展示预测结果和知识图谱。
1.6工程实现
-
1.6.1数据收集和处理:
- 收集大量的真实图像和音频以及伪造或篡改的图像和音频。
- 对收集到的数据进行清洗和预处理,例如去除噪声、进行标准化等。
- 将数据划分为训练集、验证集和测试集,以供后续模型训练和测试使用。
-
1.6.2特征提取和表示学习:
- 使用PyCharm等开发工具编写特征提取算法,从图像和音频中提取出有用的特征。
- 利用表示学习技术,例如深度嵌入或卷积神经网络(CNN),将提取出的特征转化为高维空间的向量表示,以供后续分类器使用。
-
1.6.3调用大模型端口进行训练和优化:
- 使用PyCharm等开发工具构建与大模型端口通信的接口。
- 将处理后的图像和音频特征输入到大模型端口,调用模型的分类预测功能。
- 根据模型的输出结果,使用监督学习的方法对模型进行训练和优化,以提高模型的分类准确性和泛化能力。
-
1.6.4构建后处理和可视化模块:
- 使用PyCharm等开发工具构建相应的后处理和可视化模块。
- 将预测结果整理成知识图谱的形式,并使用图表、图形等形式展示检测结果以及各个特征对于分类的影响程度。
- 设计友好的用户界面,使用户能够方便地进行图像和音频真伪检测,并将结果显示给用户。
-
1.6.5模型部署和优化:
- 将训练好的大模型和应用程序部署到实际运行环境中。
- 根据实际运行情况和用户反馈,对模型和应用程序进行优化和调整。
- 可以针对不同的应用场景进行特定的优化和定制化开发,例如调整模型的参数、使用不同的数据增强技术等。
-
1.6.6持续监控和维护:
- 对模型和应用程序进行持续监控和维护,确保其正常运行和稳定性。
- 定期收集用户反馈和使用情况,以便对模型和应用程序进行进一步优化和改进。
- 根据需要更新模型和应用程序的功能和技术,以保持其竞争力和实用性。
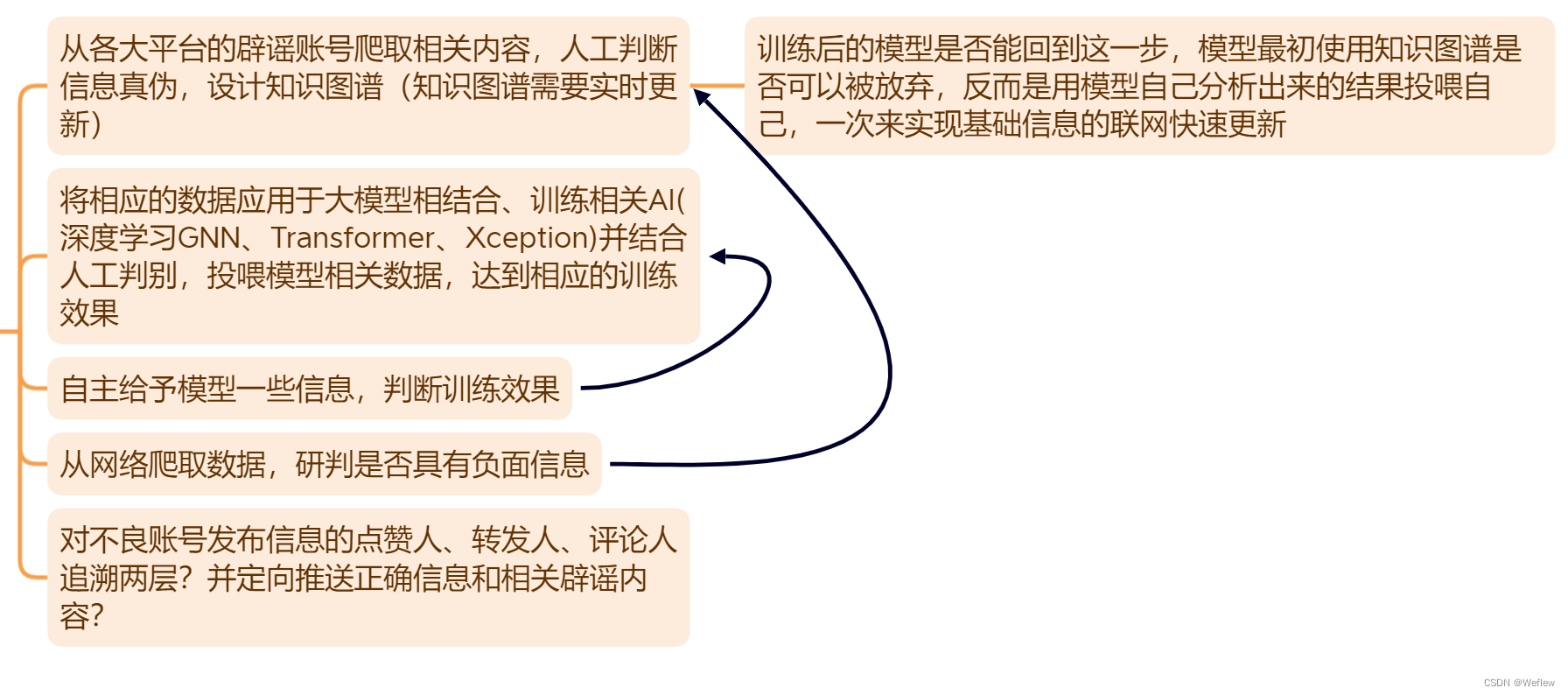
这篇关于如何利用大模型对抗网络谣言的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





